Getting Started with SONiC
Why SONiC?
We know that switches have their own operating systems for configuration, monitoring and so on. However, since the first switch was introduced in 1986, despite ongoing development by various vendors, there are still some issues, such as:
- Closed ecosystem: Non-open source systems primarily support proprietary hardware and are not compatible with devices from other vendors.
- Limited use cases: It is difficult to use the same system to support complex and diverse scenarios in large-scale data centers.
- Disruptive upgrades: Upgrades can cause network interruptions, which can be fatal for cloud providers.
- Slow feature upgrades: It is challenging to support rapid product iterations due to slow device feature upgrades.
To address these issues, Microsoft initiated the SONiC open-source project in 2016. The goal was to create a universal network operating system that solves the aforementioned problems. Additionally, Microsoft's extensive use of SONiC in Azure ensures its suitability for large-scale production environments, which is another significant advantage.
Architecture
SONiC is an open-source network operating system (NOS) developed by Microsoft based on Debian. It is designed with three core principles:
- Hardware and software decoupling: SONiC abstracts hardware operations through the Switch Abstraction Interface (SAI), enabling SONiC to support multiple hardware platforms. SAI defines this abstraction layer, which is implemented by various vendors.
- Microservices with Docker containers: The main functionalities of SONiC are divided into individual Docker containers. Unlike traditional network operating systems, upgrading the system can be done by upgrading specific containers without the need for a complete system upgrade or restart. This allows for easy upgrades, maintenance, and supports rapid development and iteration.
- Redis as a central database for service decoupling: The configuration and status of most services are stored in a central Redis database. This enables seamless collaboration between services (data storage and pub/sub) and provides a unified method for operating and querying various services without concerns about data loss or protocol compatibility. It also facilitates easy backup and recovery of states.
These design choices gives SONiC a great open ecosystem (Community, Workgroups, Devices). Overall, the architecture of SONiC is illustrated in the following diagram:
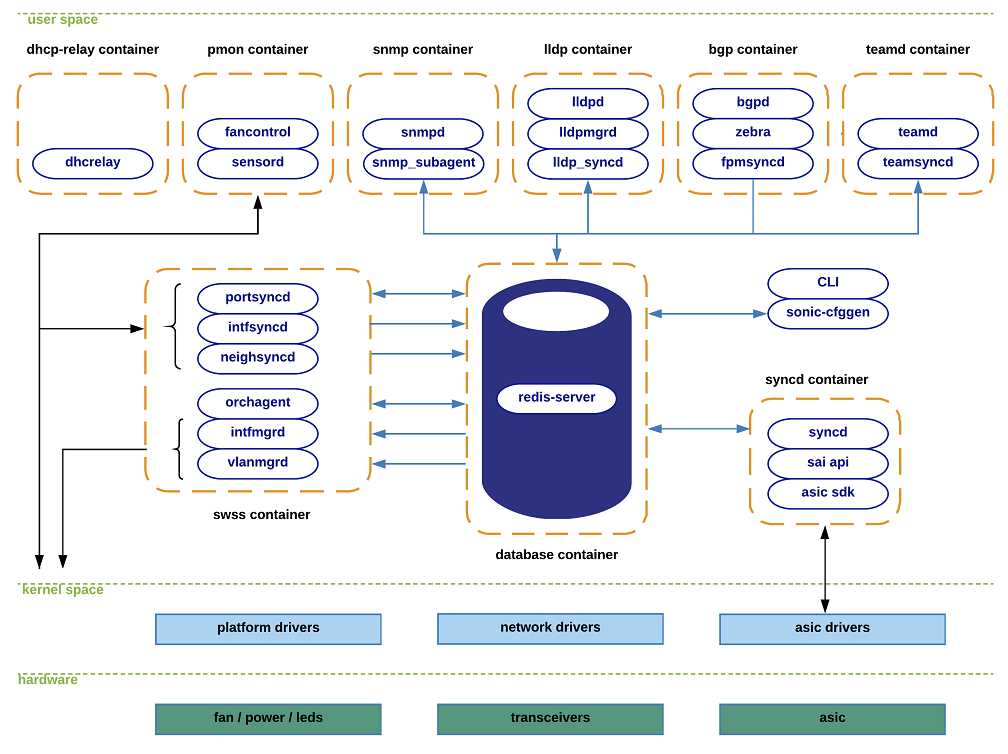
(Source: SONiC Wiki - Architecture)
Of course, this design has some drawbacks, such as relative large disk usage. However, with the availability of storage space and various methods to address this issue, it is not a significant concern.
Future Direction
Although switches have been around for many years, the development of cloud has raised higher demands and challenges for networks. These include intuitive requirements like increased bandwidth and capacity, as well as cutting-edge research such as in-band computing and edge-network convergence. These factors drive innovation among major vendors and research institutions. SONiC is no exception and continues to evolve to meet the growing demands.
To learn more about the future direction of SONiC, you can refer to its Roadmap. If you are interested in the latest updates, you can also follow its workshops, such as the recent OCP Global Summit 2022 - SONiC Workshop. However, I won't go into detail here.
Acknowledgments
Special thanks to the following individuals for their help and contributions. Without them, this introductory guide would not have been possible!
License
This book is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
References
- SONiC Wiki - Architecture
- SONiC Wiki - Roadmap Planning
- SONiC Landing Page
- SONiC Workgroups
- SONiC Supported Devices and Platforms
- SONiC User Manual
- OCP Global Summit 2022 - SONiC Workshop
Installation
If you already own a switch or are planning to purchase one and install SONiC on it, please read this section carefully. Otherwise, feel free to skip it. :D
Switch Selection and SONiC Installation
First, please confirm if your switch supports SONiC. The list of currently supported switch models can be found here. If your switch model is not on the list, you will need to contact the manufacturer to see if they have plans to support SONiC. There are many switches that do not support SONiC, such as:
- Regular switches for home use. These switches have relatively low hardware configurations (even if they support high bandwidth, such as MikroTik CRS504-4XQ-IN, which supports 100GbE networks but only has 16MB of flash storage and 64MB of RAM, so it can basically only run its own RouterOS).
- Some data center switches may not support SONiC due to their outdated models and lack of manufacturer plans.
Regarding the installation process, since each manufacturer's switch design is different, the underlying interfaces are also different, so the installation methods vary. These differences mainly focus on two areas:
- Each manufacturer will have their own SONiC Build, and some manufacturers will extend development on top of SONiC to support more features for their switches, such as Dell Enterprise SONiC and EdgeCore Enterprise SONiC. Therefore, you need to choose the corresponding version based on your switch model.
- Each manufacturer's switch will also support different installation methods, some using USB to flash the ROM directly, and some using ONIE for installation. This configuration needs to be done according to your specific switch.
Although the installation methods may vary, the overall steps are similar. Please contact your manufacturer to obtain the corresponding installation documentation and follow the instructions to complete the installation.
Configure the Switch
After installation, we need to perform some basic settings. Some settings are common, and we will summarize them here.
Set the admin password
The default SONiC account and password is admin and YourPaSsWoRd. Using default password is obviously not secure. To change the password, we can run the following command:
sudo passwd admin
Set fan speed
Data center switches are usually very noisy! For example, the switch I use is Arista 7050QX-32S, which has 4 fans that can spin up to 17000 RPM. Even if it is placed in the garage, the high-frequency whining can still be heard behind 3 walls on the second floor. Therefore, if you are using it at home, it is recommended to adjust the fan speed.
Unfortunately, SONiC does not have CLI control over fan speed, so we need to manually modify the configuration file in the pmon container to adjust the fan speed.
# Enter the pmon container
sudo docker exec -it pmon bash
# Use pwmconfig to detect all PWM fans and create a configuration file. The configuration file will be created at /etc/fancontrol.
pwmconfig
# Start fancontrol and make sure it works. If it doesn't work, you can run fancontrol directly to see what's wrong.
VERBOSE=1 /etc/init.d/fancontrol start
VERBOSE=1 /etc/init.d/fancontrol status
# Exit the pmon container
exit
# Copy the configuration file from the container to the host, so that the configuration will not be lost after reboot.
# This command needs to know what is the model of your switch. For example, the command I need to run here is as follows. If your switch model is different, please modify it accordingly.
sudo docker cp pmon:/etc/fancontrol /usr/share/sonic/device/x86_64-arista_7050_qx32s/fancontrol
Set the Switch Management Port IP
Data center switches usually can be connected via Serial Console, but its speed is very slow. Therefore, after installation, it is better to set up the Management Port as soon as possible, then use SSH connection.
Generally, the management port is named eth0, so we can use SONiC's configuration command to set it up:
# sudo config interface ip add eth0 <ip-cidr> <gateway>
# IPv4
sudo config interface ip add eth0 192.168.1.2/24 192.168.1.1
# IPv6
sudo config interface ip add eth0 2001::8/64 2001::1
Create Network Configuration
A newly installed SONiC switch will have a default network configuration, which has many issues, such as using 10.0.0.0 IP on Ethernet0, as shown below:
admin@sonic:~$ show ip interfaces
Interface Master IPv4 address/mask Admin/Oper BGP Neighbor Neighbor IP
----------- -------- ------------------- ------------ -------------- -------------
Ethernet0 10.0.0.0/31 up/up ARISTA01T2 10.0.0.1
Ethernet4 10.0.0.2/31 up/up ARISTA02T2 10.0.0.3
Ethernet8 10.0.0.4/31 up/up ARISTA03T2 10.0.0.5
Therefore, we need to update the ports with a new network configuration. A simple method is to create a VLAN and use VLAN Routing:
# Create untagged VLAN
sudo config vlan add 2
# Add IP to VLAN
sudo config interface ip add Vlan2 10.2.0.0/24
# Remove all default IP settings
show ip interfaces | tail -n +3 | grep Ethernet | awk '{print "sudo config interface ip remove", $1, $2}' > oobe.sh; chmod +x oobe.sh; ./oobe.sh
# Add all ports to the new VLAN
show interfaces status | tail -n +3 | grep Ethernet | awk '{print "sudo config vlan member add -u 2", $1}' > oobe.sh; chmod +x oobe.sh; ./oobe.sh
# Enable proxy ARP, so the switch can respond to ARP requests from hosts
sudo config vlan proxy_arp 2 enabled
# Save the config, so it will be persistent after reboot
sudo config save -y
That's it! Now we can use show vlan brief to check it:
admin@sonic:~$ show vlan brief
+-----------+--------------+-------------+----------------+-------------+-----------------------+
| VLAN ID | IP Address | Ports | Port Tagging | Proxy ARP | DHCP Helper Address |
+===========+==============+=============+================+=============+=======================+
| 2 | 10.2.0.0/24 | Ethernet0 | untagged | enabled | |
...
| | | Ethernet124 | untagged | | |
+-----------+--------------+-------------+----------------+-------------+-----------------------+
Configure the Host
If you only have one host at home using multiple NICs to connect to the switch for testing, we need to update some settings on the host to ensure that traffic flows through the NIC and the switch. Otherwise, feel free to skip this step.
There are many online guides for this, such as using DNAT and SNAT in iptables to create a virtual address. However, after some experiments, I found that the simplest way is to move one of the NICs to a new network namespace, even if it uses the same IP subnet, it will still work.
For example, if I use Netronome Agilio CX 2x40GbE at home, it will create two interfaces: enp66s0np0 and enp66s0np1. Here, we can move enp66s0np1 to a new network namespace and configure the IP address:
# Create a new network namespace
sudo ip netns add toy-ns-1
# Move the interface to the new namespace
sudo ip link set enp66s0np1 netns toy-ns-1
# Setting up IP and default routes
sudo ip netns exec toy-ns-1 ip addr add 10.2.0.11/24 dev enp66s0np1
sudo ip netns exec toy-ns-1 ip link set enp66s0np1 up
sudo ip netns exec toy-ns-1 ip route add default via 10.2.0.1
That's it! We can start testing it using iperf and confirm on the switch:
# On the host (enp66s0np0 has IP 10.2.0.10 assigned)
$ iperf -s --bind 10.2.0.10
# Test within the new network namespace
$ sudo ip netns exec toy-ns-1 iperf -c 10.2.0.10 -i 1 -P 16
------------------------------------------------------------
Client connecting to 10.2.0.10, TCP port 5001
TCP window size: 85.0 KByte (default)
------------------------------------------------------------
...
[SUM] 0.0000-10.0301 sec 30.7 GBytes 26.3 Gbits/sec
[ CT] final connect times (min/avg/max/stdev) = 0.288/0.465/0.647/0.095 ms (tot/err) = 16/0
# Confirm on the switch
admin@sonic:~$ show interfaces counters
IFACE STATE RX_OK RX_BPS RX_UTIL RX_ERR RX_DRP RX_OVR TX_OK TX_BPS TX_UTIL TX_ERR TX_DRP TX_OVR
----------- ------- ---------- ------------ --------- -------- -------- -------- ---------- ------------ --------- -------- -------- --------
Ethernet4 U 2,580,140 6190.34 KB/s 0.12% 0 3,783 0 51,263,535 2086.64 MB/s 41.73% 0 0 0
Ethernet12 U 51,261,888 2086.79 MB/s 41.74% 0 1 0 2,580,317 6191.00 KB/s 0.12% 0 0 0
References
- SONiC Supported Devices and Platforms
- SONiC Thermal Control Design
- Dell Enterprise SONiC Distribution
- Edgecore Enterprise SONiC Distribution
- Mikrotik CRS504-4XQ-IN
Hello, World! Virtually
Although SONiC is powerful, most of the time the price of a switch that supports SONiC OS is not cheap. If you just want to try SONiC without spending money on a hardware device, then this chapter is a must-read. In this chapter, we will summarize how to build a virtual SONiC lab using GNS3 locally, allowing you to quickly experience the basic functionality of SONiC.
There are several ways to run SONiC locally, such as docker + vswitch, p4 software switch, etc. For first-time users, using GNS3 may be the most convenient way, so here, we will use GNS3 as an example to explain how to build a SONiC lab locally. So, let's get started!
Prepare GNS3
First, in order to easily and intuitively establish a virtual network for testing, we need to install GNS3.
GNS3, short for Graphical Network Simulator 3, is (obviously) a graphical network simulation software. It supports various virtualization technologies such as QEMU, VMware, VirtualBox, etc. With it, when we build a virtual network, we don't have to run many commands manually or write scripts. Most of the work can be done through its GUI, which is very convenient.
Install Dependencies
Before installing it, we need to install several other software: docker, wireshark, putty, qemu, ubridge, libvirt, and bridge-utils. If you have already installed them, you can skip this step.
First is Docker. You can install it by following the instructions in this link: https://docs.docker.com/engine/install/
Installing the others on Ubuntu is very simple, just execute the following command. Note that during the installation of ubridge and Wireshark, you will be asked if you want to create the wireshark user group to bypass sudo. Be sure to choose Yes.
sudo apt-get install qemu-kvm libvirt-daemon-system libvirt-clients bridge-utils wireshark putty ubridge
Once completed, we can proceed to install GNS3.
Install GNS3
On Ubuntu, the installation of GNS3 is very simple, just execute the following commands:
sudo add-apt-repository ppa:gns3/ppa
sudo apt update
sudo apt install gns3-gui gns3-server
Then add your user to the following groups, so that GNS3 can access docker, wireshark, and other functionalities without using sudo.
for g in ubridge libvirt kvm wireshark docker; do
sudo usermod -aG $g <user-name>
done
If you are not using Ubuntu, you can refer to their official documentation for more detailed installation instructions.
Prepare the SONiC Image
Before testing, we need a SONiC image. Since SONiC supports various vendors with different underlying implementations, each vendor has their own image. In our case, since we are creating a virtual environment, we can use the VSwitch-based image to create virtual switches: sonic-vs.img.gz.
The SONiC image project is located here. Although we can compile it ourselves, the process can be slow. To save time, we can directly download the latest image from here. Just find the latest successful build and download the sonic-vs.img.gz file from the Artifacts section.
Next, let's prepare the project:
git clone --recurse-submodules https://github.com/sonic-net/sonic-buildimage.git
cd sonic-buildimage/platform/vs
# Place the downloaded image in this directory and then run the following command to extract it.
gzip -d sonic-vs.img.gz
# The following command will generate the GNS3 image configuration file.
./sonic-gns3a.sh
After executing the above commands, you can run the ls command to see the required image file.
r12f@r12f-svr:~/code/sonic/sonic-buildimage/platform/vs
$ l
total 2.8G
...
-rw-rw-r-- 1 r12f r12f 1.1K Apr 18 16:36 SONiC-latest.gns3a # <= This is the GNS3 image configuration file
-rw-rw-r-- 1 r12f r12f 2.8G Apr 18 16:32 sonic-vs.img # <= This is the image we extracted
...
Import the Image
Now, run gns3 in the command line to start GNS3. If you are SSHed into another machine, you can try enabling X11 forwarding so that you can run GNS3 remotely, with the GUI displayed locally on your machine. And I made this working using MobaXterm on my local machine.
Once it's up and running, GNS3 will prompt us to create a project. It's simple, just enter a directory. If you are using X11 forwarding, please note that this directory is on your remote server, not local.
Next, we can import the image we just generated by going to File -> Import appliance.
Select the SONiC-latest.gns3a image configuration file we just generated and click Next.
Now you can see our image, click Next.
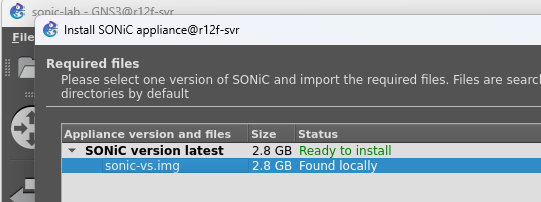
At this point, the image import process will start, which may be slow because GNS3 needs to convert the image to qcow2 format and place it in our project directory. Once completed, we can see our image.
Great! We're done!
Create the Network
Alright! Now that everything is set up, let's create a virtual network!
The GNS3 graphical interface is very user-friendly. Basically, open the sidebar, drag in the switch, drag in the VPC, and then connect the ports. After connecting, remember to click the Play button at the top to start the network simulation. We won't go into much detail here, let's just look at the pictures.
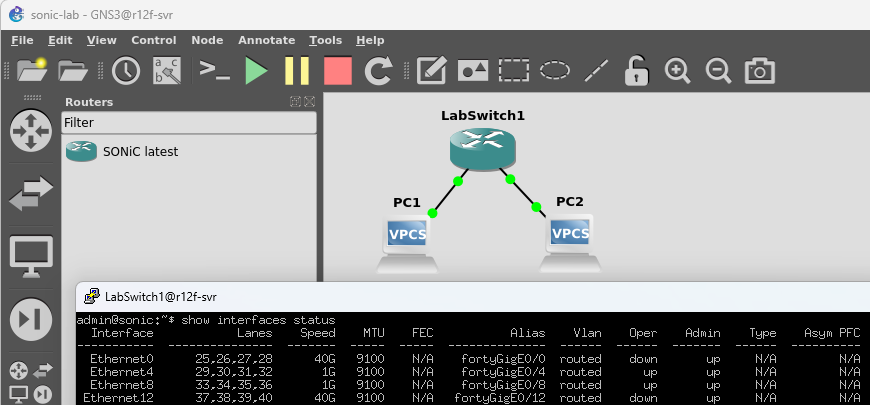
Next, right-click on the switch, select Custom Console, then select Putty to open the console of the switch we saw earlier. Here, the default username and password for SONiC are admin and YourPaSsWoRd. Once logged in, we can run familiar commands like show interfaces status or show ip interface to check the network status. Here, we can also see that the status of the first two interfaces we connected is up.
Configure the Network
In SONiC software switches, the default ports use the 10.0.0.x subnet (as shown below) with neighbor paired.
admin@sonic:~$ show ip interfaces
Interface Master IPv4 address/mask Admin/Oper BGP Neighbor Neighbor IP
----------- -------- ------------------- ------------ -------------- -------------
Ethernet0 10.0.0.0/31 up/up ARISTA01T2 10.0.0.1
Ethernet4 10.0.0.2/31 up/up ARISTA02T2 10.0.0.3
Ethernet8 10.0.0.4/31 up/up ARISTA03T2 10.0.0.5
Similar to what we mentioned in installation, we are going to create a simple network by creating a small VLAN and including our ports in it (in this case, Ethernet4 and Ethernet8):
# Remove old config
sudo config interface ip remove Ethernet4 10.0.0.2/31
sudo config interface ip remove Ethernet8 10.0.0.4/31
# Create VLAN with id 2
sudo config vlan add 2
# Add ports to VLAN
sudo config vlan member add -u 2 Ethernet4
sudo config vlan member add -u 2 Ethernet8
# Add IP address to VLAN
sudo config interface ip add Vlan2 10.0.0.0/24
Now, our VLAN is created, and we can use show vlan brief to check:
admin@sonic:~$ show vlan brief
+-----------+--------------+-----------+----------------+-------------+-----------------------+
| VLAN ID | IP Address | Ports | Port Tagging | Proxy ARP | DHCP Helper Address |
+===========+==============+===========+================+=============+=======================+
| 2 | 10.0.0.0/24 | Ethernet4 | untagged | disabled | |
| | | Ethernet8 | untagged | | |
+-----------+--------------+-----------+----------------+-------------+-----------------------+
Now, let's assign a 10.0.0.x IP address to each host.
# VPC1
ip 10.0.0.2 255.0.0.0 10.0.0.1
# VPC2
ip 10.0.0.3 255.0.0.0 10.0.0.1
Alright, let's start the ping!
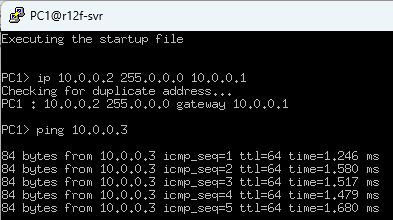
It works!
Packet Capture
Before installing GNS3, we installed Wireshark so that we can capture packets within the virtual network created by GNS3. To start capturing, simply right-click on the link you want to capture on and select Start capture.
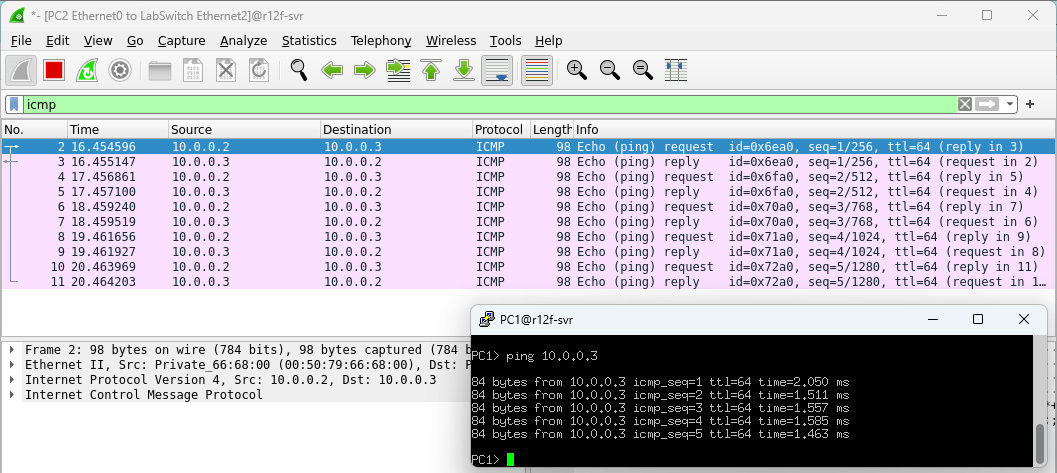
After a moment, Wireshark will automatically open and display all the packets in real-time. Very convenient!
More Networks
In addition to the simplest network setup we discussed above, we can actually use GNS3 to build much more complex networks for testing, such as multi-layer ECMP + eBGP, and more. XFlow Research has published a very detailed document that covers these topics. Interested folks can refer to the document: SONiC Deployment and Testing Using GNS3.
References
Common Commands
To help us check and configure the state of SONiC, SONiC provides a large number of CLI commands for us to use. These commands are mostly divided into two categories: show and config. Their formats are generally similar, mostly following the format below:
show <object> [options]
config <object> [options]
The SONiC documentation provides a very detailed list of commands: SONiC Command Line Interface Guide, but due to the large number of commands, it is not very convenient for us to ramp up, so we listed some of the most commonly used commands and explanations for reference.
All subcommands in SONiC can be abbreviated to the first three letters to help us save time when entering commands. For example:
show interface transceiver error-status
is equivalent to:
show int tra err
To help with memory and lookup, the following command list uses full names, but in actual use, you can boldly use abbreviations to reduce workload.
If you encounter unfamiliar commands, you can view the help information by entering -h or --help, for example:
show -h
show interface --help
show interface transceiver --help
Basic system information
# Show system version, platform info and docker containers
show version
# Show system uptime
show uptime
# Show platform information, such as HWSKU
show platform summary
Config
# Reload all config.
# WARNING: This will restart almost all services and will cause network interruption.
sudo config reload
# Save the current config from redis DB to disk, which makes the config persistent across reboots.
# NOTE: The config file is saved to `/etc/sonic/config_db.json`
sudo config save -y
Docker Related
# Show all docker containers
docker ps
# Show processes running in a container
docker top <container_id>|<container_name>
# Enter the container
docker exec -it <container_id>|<container_name> bash
If we want to perform an operation on all docker containers, we can use the docker ps command to get all container IDs, then pipe to tail -n +2 to remove the first line of the header, thus achieving batch calls.
For example, we can use the following command to view all threads running in all containers:
$ for id in `docker ps | tail -n +2 | awk '{print $1}'`; do docker top $id; done
UID PID PPID C STIME TTY TIME CMD
root 7126 7103 0 Jun09 pts/0 00:02:24 /usr/bin/python3 /usr/local/bin/supervisord
root 7390 7126 0 Jun09 pts/0 00:00:24 python3 /usr/bin/supervisor-proc-exit-listener --container-name telemetry
...
Interfaces / IPs
show interface status
show interface counters
show interface portchannel
show interface transceiver info
show interface transceiver eeprom
sonic-clear counters
TODO: config
MAC / ARP / NDP
# Show MAC (FDB) entries
show mac
# Show IP ARP table
show arp
# Show IPv6 NDP table
show ndp
BGP / Routes
show ip/ipv6 bgp summary
show ip/ipv6 bgp network
show ip/ipv6 bgp neighbors [IP]
show ip/ipv6 route
TODO: add
config bgp shutdown neighbor <IP>
config bgp shutdown all
TODO: IPv6
LLDP
# Show LLDP neighbors in table format
show lldp table
# Show LLDP neighbors details
show lldp neighbors
VLAN
show vlan brief
QoS Related
# Show PFC watchdog stats
show pfcwd stats
show queue counter
ACL
show acl table
show acl rule
MUXcable / Dual ToR
Muxcable mode
config muxcable mode {active} {<portname>|all} [--json]
config muxcable mode active Ethernet4 [--json]
Muxcable config
show muxcable config [portname] [--json]
Muxcable status
show muxcable status [portname] [--json]
Muxcable firmware
# Firmware version:
show muxcable firmware version <port>
# Firmware download
# config muxcable firmware download <firmware_file> <port_name>
sudo config muxcable firmware download AEC_WYOMING_B52Yb0_MS_0.6_20201218.bin Ethernet0
# Rollback:
# config muxcable firmware rollback <port_name>
sudo config muxcable firmware rollback Ethernet0
References
Core components
We might feel that a switch is a simple network device, but in fact, there could be many components running on the switch.
Since SONiC decoupled all its services using Redis, it can be difficult to understand the relationships between services by simpling tracking the code. To get started on SONiC quickly, it is better to first establish a high-level model, and then delve into the details of each component. Therefore, before diving into other parts, we will first give a brief introduction to each component to help everyone build a rough overall model.
Before reading this chapter, there are two terms that will frequently appear in this chapter and in SONiC's official documentation: ASIC (Application-Specific Integrated Circuit) and ASIC state. They refer to the state of the pipeline used for packet processing in the switch, such as ACL or other packet forwarding methods.
If you are interested in learning more details, you can first read two related materials: SAI (Switch Abstraction Interface) API and a related paper on RMT (Reprogrammable Match Table): Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN.
In addition, to help us get started, we placed the SONiC architecture diagram here again as a reference:
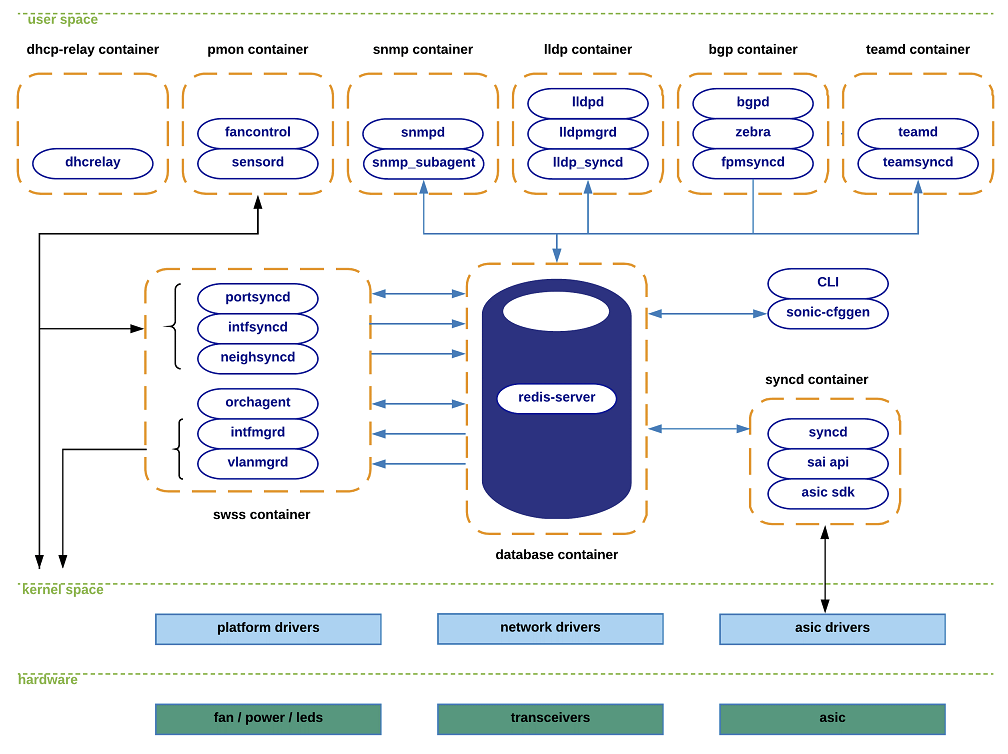
(Source: SONiC Wiki - Architecture)
References
- SONiC Architecture
- SAI API
- Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN
Redis database
First and foremost, the core service in SONiC is undoubtedly the central database - Redis! It has two major purposes: storing the configuration and state of all services, and providing a communication channel for these services.
To provide these functionalities, SONiC creates a database instance in Redis named sonic-db. The configuration and database partitioning information can be found in /var/run/redis/sonic-db/database_config.json:
admin@sonic:~$ cat /var/run/redis/sonic-db/database_config.json
{
"INSTANCES": {
"redis": {
"hostname": "127.0.0.1",
"port": 6379,
"unix_socket_path": "/var/run/redis/redis.sock",
"persistence_for_warm_boot": "yes"
}
},
"DATABASES": {
"APPL_DB": { "id": 0, "separator": ":", "instance": "redis" },
"ASIC_DB": { "id": 1, "separator": ":", "instance": "redis" },
"COUNTERS_DB": { "id": 2, "separator": ":", "instance": "redis" },
"LOGLEVEL_DB": { "id": 3, "separator": ":", "instance": "redis" },
"CONFIG_DB": { "id": 4, "separator": "|", "instance": "redis" },
"PFC_WD_DB": { "id": 5, "separator": ":", "instance": "redis" },
"FLEX_COUNTER_DB": { "id": 5, "separator": ":", "instance": "redis" },
"STATE_DB": { "id": 6, "separator": "|", "instance": "redis" },
"SNMP_OVERLAY_DB": { "id": 7, "separator": "|", "instance": "redis" },
"RESTAPI_DB": { "id": 8, "separator": "|", "instance": "redis" },
"GB_ASIC_DB": { "id": 9, "separator": ":", "instance": "redis" },
"GB_COUNTERS_DB": { "id": 10, "separator": ":", "instance": "redis" },
"GB_FLEX_COUNTER_DB": { "id": 11, "separator": ":", "instance": "redis" },
"APPL_STATE_DB": { "id": 14, "separator": ":", "instance": "redis" }
},
"VERSION": "1.0"
}
Although we can see that there are about a dozen databases in SONiC, most of the time we only need to focus on the following most important ones:
- CONFIG_DB (ID = 4): Stores the configuration of all services, such as port configuration, VLAN configuration, etc. It represents the data model of the desired state of the switch as intended by the user. This is also the main object of operation when all CLI and external applications modify the configuration.
- APPL_DB (Application DB, ID = 0): Stores internal state information of all services. It contains two types of information:
- One is calculated by each service after reading the configuration information from CONFIG_DB, which can be understood as the desired state of the switch (Goal State) but from the perspective of each service.
- The other is when the ASIC state changes and is written back, some services write directly to APPL_DB instead of the STATE_DB we will introduce next. This information can be understood as the current state of the switch as perceived by each service.
- STATE_DB (ID = 6): Stores the current state of various components of the switch. When a service in SONiC receives a state change from STATE_DB and finds it inconsistent with the Goal State, SONiC will reapply the configuration until the two states are consistent. (Of course, for those states written back to APPL_DB, the service will monitor changes in APPL_DB instead of STATE_DB.)
- ASIC_DB (ID = 1): Stores the desired state information of the switch ASIC in SONiC, such as ACL, routing, etc. Unlike APPL_DB, the data model in this database is designed for ASIC rather than service abstraction. This design facilitates the development of SAI and ASIC drivers by various vendors.
Now, we have an intuitive question: with so many services in the switch, are all configurations and states stored in a single database without isolation? What if two services use the same Redis Key? This is a very good question, and SONiC's solution is straightforward: continue to partition each database into tables!
We know that Redis does not have the concept of tables within each database but uses key-value pairs to store data. Therefore, to further partition tables, SONiC's solution is to include the table name in the key and separate the table and key with a delimiter. The separator field in the configuration file above serves this purpose. For example, the state of the Ethernet4 port in the PORT_TABLE table in APPL_DB can be accessed using PORT_TABLE:Ethernet4 as follows:
127.0.0.1:6379> select 0
OK
127.0.0.1:6379> hgetall PORT_TABLE:Ethernet4
1) "admin_status"
2) "up"
3) "alias"
4) "Ethernet6/1"
5) "index"
6) "6"
7) "lanes"
8) "13,14,15,16"
9) "mtu"
1) "9100"
2) "speed"
3) "40000"
4) "description"
5) ""
6) "oper_status"
7) "up"
Of course, in SONiC, not only the data model but also the communication mechanism uses a similar method to achieve "table" level isolation.
References
Introduction to Services and Workflows
There are many services (daemon processes) in SONiC, around twenty to thirty. They start with the switch and keep running until the switch is shut down. If we want to quickly understand how SONiC works, diving into each service one by one is obviously not a good option. Therefore, it is better to categorize these services and control flows on high level to help us build a big picture.
We will not delve into any specific service here. Instead, we will first look at the overall structure of services in SONiC to help us build a comprehensive understanding. For specific services, we will introduce its workflows in the workflow chapter. For detailed information, we can also refer to the design documents related to each service.
Service Categories
Generally speaking, the services in SONiC can be divided into the following categories: *syncd, *mgrd, feature implementations, orchagent, and syncd.
*syncd Services
These services have names ending with syncd. They perform similar tasks: synchronizing hardware states to Redis, usually into APPL_DB or STATE_DB.
For example, portsyncd listens to netlink events and synchronizes the status of all ports in the switch to STATE_DB, while natsyncd listens to netlink events and synchronizes all NAT statuses in the switch to APPL_DB.
*mgrd Services
These services have names ending with mgrd. As the name suggests, these are "Manager" services responsible for configuring various hardware, opposite to *syncd. Their logic mainly consists of two parts:
- Configuration Deployment: Responsible for reading configuration files and listening to configuration and state changes in Redis (mainly CONFIG_DB, APPL_DB, and STATE_DB), then pushing these changes to the switch hardware. The method of pushing varies depending on the target, either by updating APPL_DB and publishing update messages or directly calling Linux command lines to modify the system. For example,
nbrmgrlistens to changes in CONFIG_DB, APPL_DB, and STATE_DB for neighbors and modifies neighbors and routes using netlink and command lines, whileintfmgrnot only calls command lines but also updates some states to APPL_DB. - State Synchronization: For services that need reconciliation,
*mgrdalso listens to state changes in STATE_DB. If it finds that the hardware state is inconsistent with the expected state, it will re-initiate the configuration process to set the hardware state to the expected state. These state changes in STATE_DB are usually pushed by*syncdservices. For example,intfmgrlistens to port up/down status and MTU changes pushed byportsyncdin STATE_DB. If it finds inconsistencies with the expected state stored in its memory, it will re-deploy the configuration.
orchagent Service
This is the most important service in SONiC. Unlike other services that are responsible for one or two specific functions, orchagent, as the orchestrator of the switch ASIC state, checks all states from *syncd services in the database, integrates them, and deploys them to ASIC_DB, which is used to store the switch ASIC configuration. These states are eventually received by syncd, which calls the SAI API through the SAI implementation and ASIC SDK provided by various vendors to interact with the ASIC, ultimately deploying the configuration to the switch hardware.
Feature Implementation Services
Some features are not implemented by the OS itself but by specific processes, such as BGP or some external-facing interfaces. These services often have names ending with d, indicating daemon, such as bgpd, lldpd, snmpd, teamd, etc., or simply the name of the feature, such as fancontrol.
syncd Service
The syncd service is downstream of orchagent. Although its name is syncd, it shoulders the work of both *mgrd and *syncd for the ASIC.
- First, as
*mgrd, it listens to state changes in ASIC_DB. Once detected, it retrieves the new state and calls the SAI API to deploy the configuration to the switch hardware. - Then, as
*syncd, if the ASIC sends any notifications to SONiC, it will send these notifications to Redis as messages, allowingorchagentand*mgrdservices to obtain these changes and process them. The types of these notifications can be found in SwitchNotifications.h.
Control Flow Between Services
With service categories, we can now better understand the services in SONiC. To get started, it is crucial to understand the control flow between services. Based on the above categories, we can divide the main control flows into two categories: configuration deployment and state synchronization.
Configuration Deployment
The configuration deployment process generally follows these steps:
- Modify Configuration: Users can modify configurations through CLI or REST API. These configurations are written to CONFIG_DB and send update notifications through Redis. Alternatively, external programs can modify configurations through specific interfaces, such as the BGP API. These configurations are sent to
*mgrdservices through internal TCP sockets. *mgrdDeploys Configuration: Services listen to configuration changes in CONFIG_DB and then push these configurations to the switch hardware. There are two main scenarios (which can coexist):- Direct Deployment:
*mgrdservices directly call Linux command lines or modify system configurations through netlink.*syncdservices listen to system configuration changes through netlink or other methods and push these changes to STATE_DB or APPL_DB.*mgrdservices listen to configuration changes in STATE_DB or APPL_DB, compare these configurations with those stored in their memory, and if inconsistencies are found, they re-call command lines or netlink to modify system configurations until they are consistent.
- Indirect Deployment:
*mgrdpushes states to APPL_DB and sends update notifications through Redis.orchagentlistens to configuration changes, calculates the state the ASIC should achieve based on all related states, and deploys it to ASIC_DB.syncdlistens to changes in ASIC_DB and updates the switch ASIC configuration through the unified SAI API interface by calling the ASIC Driver.
- Direct Deployment:
Configuration initialization is similar to configuration deployment but involves reading configuration files when services start, which will not be expanded here.
State Synchronization
If situations arise, such as a port failure or changes in the ASIC state, state updates and synchronization are needed. The process generally follows these steps:
- Detect State Changes: These state changes mainly come from
*syncdservices (netlink, etc.) andsyncdservices (SAI Switch Notification). After detecting changes, these services send them to STATE_DB or APPL_DB. - Process State Changes:
orchagentand*mgrdservices listen to these changes, process them, and re-deploy new configurations to the system through command lines and netlink or to ASIC_DB forsyncdservices to update the ASIC again.
Specific Examples
The official SONiC documentation provides several typical examples of control flow. Interested readers can refer to SONiC Subsystem Interactions. In the workflow chapter, we will also expand on some very common workflows.
References
Key containers
One of the most distinctive features of SONiC's design is containerization.
From the design diagram of SONiC, we can see that all services in SONiC run in the form of containers. After logging into the switch, we can use the docker ps command to see all containers that are currently running:
admin@sonic:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ddf09928ec58 docker-snmp:latest "/usr/local/bin/supe…" 2 days ago Up 32 hours snmp
c480f3cf9dd7 docker-sonic-mgmt-framework:latest "/usr/local/bin/supe…" 2 days ago Up 32 hours mgmt-framework
3655aff31161 docker-lldp:latest "/usr/bin/docker-lld…" 2 days ago Up 32 hours lldp
78f0b12ed10e docker-platform-monitor:latest "/usr/bin/docker_ini…" 2 days ago Up 32 hours pmon
f9d9bcf6c9a6 docker-router-advertiser:latest "/usr/bin/docker-ini…" 2 days ago Up 32 hours radv
2e5dbee95844 docker-fpm-frr:latest "/usr/bin/docker_ini…" 2 days ago Up 32 hours bgp
bdfa58009226 docker-syncd-brcm:latest "/usr/local/bin/supe…" 2 days ago Up 32 hours syncd
655e550b7a1b docker-teamd:latest "/usr/local/bin/supe…" 2 days ago Up 32 hours teamd
1bd55acc181c docker-orchagent:latest "/usr/bin/docker-ini…" 2 days ago Up 32 hours swss
bd20649228c8 docker-eventd:latest "/usr/local/bin/supe…" 2 days ago Up 32 hours eventd
b2f58447febb docker-database:latest "/usr/local/bin/dock…" 2 days ago Up 32 hours database
Here we will briefly introduce these containers.
Database Container: database
This container contains the central database - Redis, which we have mentioned multiple times. It stores all the configuration and status of the switch, and SONiC also uses it to provide the underlying communication mechanism to various services.
By entering this container via Docker, we can see the running Redis process:
admin@sonic:~$ sudo docker exec -it database bash
root@sonic:/# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
...
root 82 13.7 1.7 130808 71692 pts/0 Sl Apr26 393:27 /usr/bin/redis-server 127.0.0.1:6379
...
root@sonic:/# cat /var/run/redis/redis.pid
82
How does other container access this Redis database?
The answer is through Unix Socket. We can see this Unix Socket in the database container, which is mapped from the /var/run/redis directory on the switch.
# In database container
root@sonic:/# ls /var/run/redis
redis.pid redis.sock sonic-db
# On host
admin@sonic:~$ ls /var/run/redis
redis.pid redis.sock sonic-db
Then SONiC maps /var/run/redis folder into all relavent containers, allowing other services to access the central database. For example, the swss container:
admin@sonic:~$ docker inspect swss
...
"HostConfig": {
"Binds": [
...
"/var/run/redis:/var/run/redis:rw",
...
],
...
SWitch State Service Container: swss
This container can be considered the most critical container in SONiC. It is the brain of SONiC, running numerous *syncd and *mgrd services to manage various configurations of the switch, such as Port, neighbor, ARP, VLAN, Tunnel, etc. Additionally, it runs the orchagent, which handles many configurations and state changes related to the ASIC.
We have already discussed the general functions and processes of these services, so we won't repeat them here. We can use the ps command to see the services running in this container:
admin@sonic:~$ docker exec -it swss bash
root@sonic:/# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
...
root 43 0.0 0.2 91016 9688 pts/0 Sl Apr26 0:18 /usr/bin/portsyncd
root 49 0.1 0.6 558420 27592 pts/0 Sl Apr26 4:31 /usr/bin/orchagent -d /var/log/swss -b 8192 -s -m 00:1c:73:f2:bc:b4
root 74 0.0 0.2 91240 9776 pts/0 Sl Apr26 0:19 /usr/bin/coppmgrd
root 93 0.0 0.0 4400 3432 pts/0 S Apr26 0:09 /bin/bash /usr/bin/arp_update
root 94 0.0 0.2 91008 8568 pts/0 Sl Apr26 0:09 /usr/bin/neighsyncd
root 96 0.0 0.2 91168 9800 pts/0 Sl Apr26 0:19 /usr/bin/vlanmgrd
root 99 0.0 0.2 91320 9848 pts/0 Sl Apr26 0:20 /usr/bin/intfmgrd
root 103 0.0 0.2 91136 9708 pts/0 Sl Apr26 0:19 /usr/bin/portmgrd
root 104 0.0 0.2 91380 9844 pts/0 Sl Apr26 0:20 /usr/bin/buffermgrd -l /usr/share/sonic/hwsku/pg_profile_lookup.ini
root 107 0.0 0.2 91284 9836 pts/0 Sl Apr26 0:20 /usr/bin/vrfmgrd
root 109 0.0 0.2 91040 8600 pts/0 Sl Apr26 0:19 /usr/bin/nbrmgrd
root 110 0.0 0.2 91184 9724 pts/0 Sl Apr26 0:19 /usr/bin/vxlanmgrd
root 112 0.0 0.2 90940 8804 pts/0 Sl Apr26 0:09 /usr/bin/fdbsyncd
root 113 0.0 0.2 91140 9656 pts/0 Sl Apr26 0:20 /usr/bin/tunnelmgrd
root 208 0.0 0.0 5772 1636 pts/0 S Apr26 0:07 /usr/sbin/ndppd
...
ASIC Management Container: syncd
This container is mainly used for managing the ASIC on the switch, running the syncd service. The SAI (Switch Abstraction Interface) implementation and ASIC Driver provided by various vendors are placed in this container. It allows SONiC to support multiple different ASICs without modifying the upper-layer services. In other words, without this container, SONiC would be a brain in a jar, capable of only thinking but nothing else.
We don't have too many services running in the syncd container, mainly syncd. We can check them using the ps command, and in the /usr/lib directory, we can find the enormous SAI file compiled to support the ASIC:
admin@sonic:~$ docker exec -it syncd bash
root@sonic:/# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
...
root 20 0.0 0.0 87708 1544 pts/0 Sl Apr26 0:00 /usr/bin/dsserve /usr/bin/syncd --diag -u -s -p /etc/sai.d/sai.profile -b /tmp/break_before_make_objects
root 32 10.7 14.9 2724404 599408 pts/0 Sl Apr26 386:49 /usr/bin/syncd --diag -u -s -p /etc/sai.d/sai.profile -b /tmp/break_before_make_objects
...
root@sonic:/# ls -lh /usr/lib
total 343M
...
lrwxrwxrwx 1 root root 13 Apr 25 04:38 libsai.so.1 -> libsai.so.1.0
-rw-r--r-- 1 root root 343M Feb 1 06:10 libsai.so.1.0
...
Feature Containers
There are many containers in SONiC designed to implement specific features. These containers usually have special external interfaces (non-SONiC CLI and REST API) and implementations (non-OS or ASIC), such as:
bgp: Container for implementing the BGP and other routing protocol (Border Gateway Protocol)lldp: Container for implementing the LLDP protocol (Link Layer Discovery Protocol)teamd: Container for implementing Link Aggregationsnmp: Container for implementing the SNMP protocol (Simple Network Management Protocol)
Similar to SWSS, these containers also run the services we mentioned earlier to adapt to SONiC's architecture:
- Configuration management and deployment (similar to
*mgrd):lldpmgrd,zebra(bgp) - State synchronization (similar to
*syncd):lldpsyncd,fpmsyncd(bgp),teamsyncd - Service implementation or external interface (
*d):lldpd,bgpd,teamd,snmpd
Management Service Container: mgmt-framework
In previous chapters, we have seen how to use SONiC's CLI to configure some aspects of the switch. However, in a production environment, manually logging into the switch and using the CLI to configure all switches is unrealistic. Therefore, SONiC provides a REST API to solve this problem. This REST API is implemented in the mgmt-framework container. We can check it using the ps command:
admin@sonic:~$ docker exec -it mgmt-framework bash
root@sonic:/# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
...
root 16 0.3 1.2 1472804 52036 pts/0 Sl 16:20 0:02 /usr/sbin/rest_server -ui /rest_ui -logtostderr -cert /tmp/cert.pem -key /tmp/key.pem
...
In addition to the REST API, SONiC can also be managed through other methods such as gNMI, all of which run in this container. The overall architecture is shown in the figure below [2]:
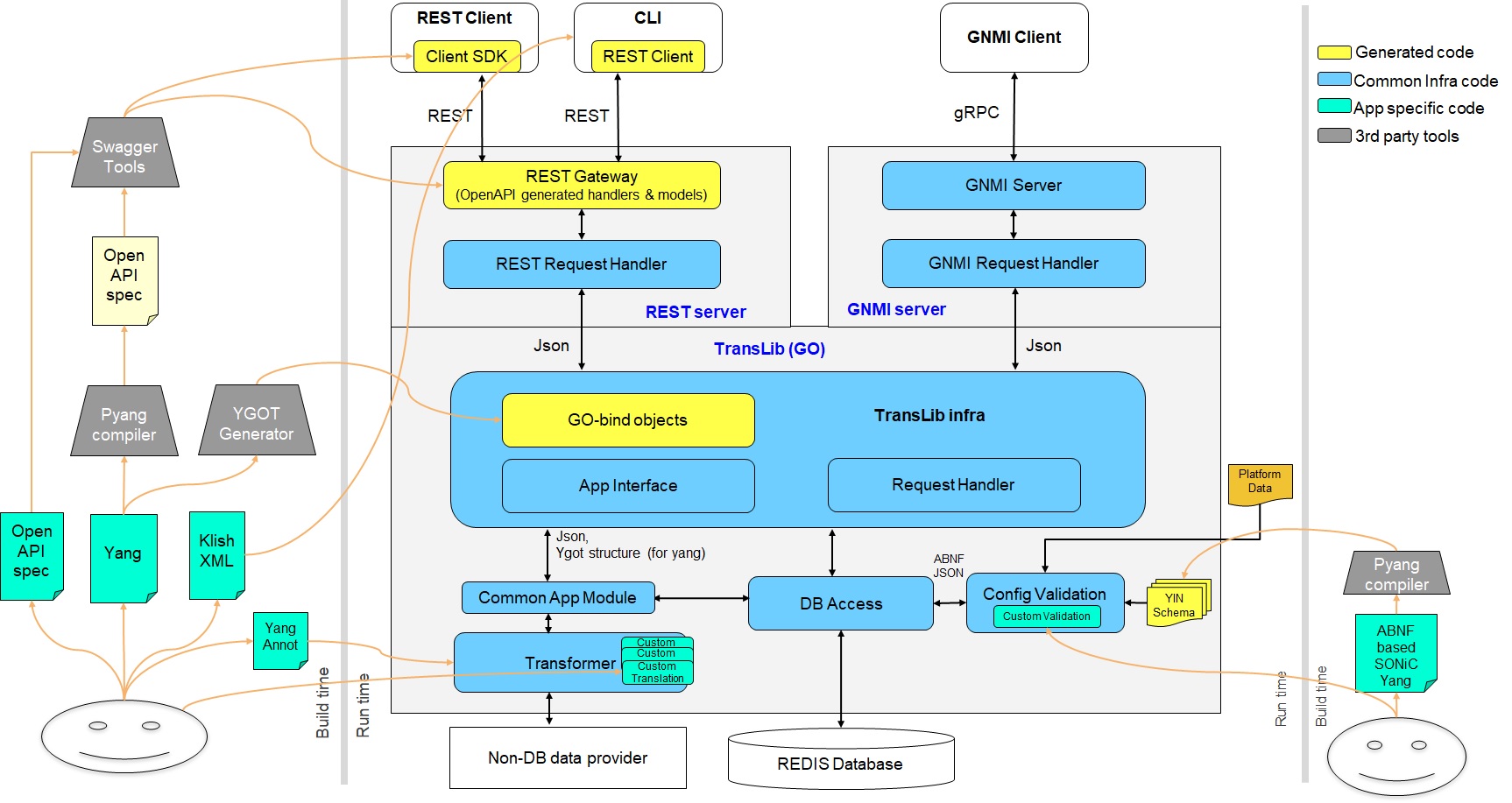
Here we can also see that the CLI we use can be implemented by calling this REST API at the bottom layer.
Platform Monitor Container: pmon
The services in this container are mainly used to monitor the basic hardware status of the switch, such as temperature, power supply, fans, SFP events, etc. Similarly, we can use the ps command to check the services running in this container:
admin@sonic:~$ docker exec -it pmon bash
root@sonic:/# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
...
root 28 0.0 0.8 49972 33192 pts/0 S Apr26 0:23 python3 /usr/local/bin/ledd
root 29 0.9 1.0 278492 43816 pts/0 Sl Apr26 34:41 python3 /usr/local/bin/xcvrd
root 30 0.4 1.0 57660 40412 pts/0 S Apr26 18:41 python3 /usr/local/bin/psud
root 32 0.0 1.0 57172 40088 pts/0 S Apr26 0:02 python3 /usr/local/bin/syseepromd
root 33 0.0 1.0 58648 41400 pts/0 S Apr26 0:27 python3 /usr/local/bin/thermalctld
root 34 0.0 1.3 70044 53496 pts/0 S Apr26 0:46 /usr/bin/python3 /usr/local/bin/pcied
root 42 0.0 0.0 55320 1136 ? Ss Apr26 0:15 /usr/sbin/sensord -f daemon
root 45 0.0 0.8 58648 32220 pts/0 S Apr26 2:45 python3 /usr/local/bin/thermalctld
...
The purpose of most of these services can be told from their names. The only one that is not so obvious is xcvrd, where xcv stands for transceiver. It is used to monitor the optical modules of the switch, such as SFP, QSFP, etc.
References
SAI
SAI (Switch Abstraction Interface) is the cornerstone of SONiC, while enables it to support multiple hardware platforms. In this SAI API document, we can see all the interfaces it defines.
In the core container section, we mentioned that SAI runs in the syncd container. However, unlike other components, it is not a service but a set of common header files and dynamic link libraries (.so). All abstract interfaces are defined as C language header files in the OCP SAI repository, and the hardware vendors provides the .so files that implement the SAI interfaces.
SAI Interface
To make things more intuitive, let's take a small portion of the code to show how SAI interfaces look like and how it works, as follows:
// File: meta/saimetadata.h
typedef struct _sai_apis_t {
sai_switch_api_t* switch_api;
sai_port_api_t* port_api;
...
} sai_apis_t;
// File: inc/saiswitch.h
typedef struct _sai_switch_api_t
{
sai_create_switch_fn create_switch;
sai_remove_switch_fn remove_switch;
sai_set_switch_attribute_fn set_switch_attribute;
sai_get_switch_attribute_fn get_switch_attribute;
...
} sai_switch_api_t;
// File: inc/saiport.h
typedef struct _sai_port_api_t
{
sai_create_port_fn create_port;
sai_remove_port_fn remove_port;
sai_set_port_attribute_fn set_port_attribute;
sai_get_port_attribute_fn get_port_attribute;
...
} sai_port_api_t;
The sai_apis_t structure is a collection of interfaces for all SAI modules, with each member being a pointer to a specific module's interface list. For example, sai_switch_api_t defines all the interfaces for the SAI Switch module, and its definition can be found in inc/saiswitch.h. Similarly, the interface definitions for the SAI Port module can be found in inc/saiport.h.
SAI Initialization
SAI initialization is essentially about obtaining these function pointers so that we can operate the ASIC through the SAI interfaces.
The main functions involved in SAI initialization are defined in inc/sai.h:
sai_api_initialize: Initialize SAIsai_api_query: Pass in the type of SAI API to get the corresponding interface list
Although most vendors' SAI implementations are closed-source, Mellanox has open-sourced its SAI implementation, allowing us to gain a deeper understanding of how SAI works.
For example, the sai_api_initialize function simply sets two global variables and returns SAI_STATUS_SUCCESS:
// File: https://github.com/Mellanox/SAI-Implementation/blob/master/mlnx_sai/src/mlnx_sai_interfacequery.c
sai_status_t sai_api_initialize(_In_ uint64_t flags, _In_ const sai_service_method_table_t* services)
{
if (g_initialized) {
return SAI_STATUS_FAILURE;
}
// Validate parameters here (code omitted)
memcpy(&g_mlnx_services, services, sizeof(g_mlnx_services));
g_initialized = true;
return SAI_STATUS_SUCCESS;
}
After initialization, we can use the sai_api_query function to query the corresponding interface list by passing in the type of API, where each interface list is actually a global variable:
// File: https://github.com/Mellanox/SAI-Implementation/blob/master/mlnx_sai/src/mlnx_sai_interfacequery.c
sai_status_t sai_api_query(_In_ sai_api_t sai_api_id, _Out_ void** api_method_table)
{
if (!g_initialized) {
return SAI_STATUS_UNINITIALIZED;
}
...
return sai_api_query_eth(sai_api_id, api_method_table);
}
// File: https://github.com/Mellanox/SAI-Implementation/blob/master/mlnx_sai/src/mlnx_sai_interfacequery_eth.c
sai_status_t sai_api_query_eth(_In_ sai_api_t sai_api_id, _Out_ void** api_method_table)
{
switch (sai_api_id) {
case SAI_API_BRIDGE:
*(const sai_bridge_api_t**)api_method_table = &mlnx_bridge_api;
return SAI_STATUS_SUCCESS;
case SAI_API_SWITCH:
*(const sai_switch_api_t**)api_method_table = &mlnx_switch_api;
return SAI_STATUS_SUCCESS;
...
default:
if (sai_api_id >= (sai_api_t)SAI_API_EXTENSIONS_RANGE_END) {
return SAI_STATUS_INVALID_PARAMETER;
} else {
return SAI_STATUS_NOT_IMPLEMENTED;
}
}
}
// File: https://github.com/Mellanox/SAI-Implementation/blob/master/mlnx_sai/src/mlnx_sai_bridge.c
const sai_bridge_api_t mlnx_bridge_api = {
mlnx_create_bridge,
mlnx_remove_bridge,
mlnx_set_bridge_attribute,
mlnx_get_bridge_attribute,
...
};
// File: https://github.com/Mellanox/SAI-Implementation/blob/master/mlnx_sai/src/mlnx_sai_switch.c
const sai_switch_api_t mlnx_switch_api = {
mlnx_create_switch,
mlnx_remove_switch,
mlnx_set_switch_attribute,
mlnx_get_switch_attribute,
...
};
Using SAI
In the syncd container, SONiC starts the syncd service at startup, which loads the SAI component present in the system. This component is provided by various vendors, who implement the SAI interfaces based on their hardware platforms, allowing SONiC to use a unified upper-layer logic to control various hardware platforms.
We can verify this using the ps, ls, and nm commands:
# Enter into syncd container
admin@sonic:~$ docker exec -it syncd bash
# List all processes. We will only see syncd process here.
root@sonic:/# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
...
root 21 0.0 0.0 87708 1532 pts/0 Sl 16:20 0:00 /usr/bin/dsserve /usr/bin/syncd --diag -u -s -p /etc/sai.d/sai.profile -b /tmp/break_before_make_objects
root 33 11.1 15.0 2724396 602532 pts/0 Sl 16:20 36:30 /usr/bin/syncd --diag -u -s -p /etc/sai.d/sai.profile -b /tmp/break_before_make_objects
...
# Find all libsai*.so.* files.
root@sonic:/# find / -name libsai*.so.*
/usr/lib/x86_64-linux-gnu/libsaimeta.so.0
/usr/lib/x86_64-linux-gnu/libsaimeta.so.0.0.0
/usr/lib/x86_64-linux-gnu/libsaimetadata.so.0.0.0
/usr/lib/x86_64-linux-gnu/libsairedis.so.0.0.0
/usr/lib/x86_64-linux-gnu/libsairedis.so.0
/usr/lib/x86_64-linux-gnu/libsaimetadata.so.0
/usr/lib/libsai.so.1
/usr/lib/libsai.so.1.0
# Copy the file out of switch and check libsai.so on your own dev machine.
# We will see the most important SAI export functions here.
$ nm -C -D ./libsai.so.1.0 > ./sai-exports.txt
$ vim sai-exports.txt
...
0000000006581ae0 T sai_api_initialize
0000000006582700 T sai_api_query
0000000006581da0 T sai_api_uninitialize
...
References
- SONiC Architecture
- SAI API
- Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN
- Github: sonic-net/sonic-sairedis
- Github: opencomputeproject/SAI
- Arista 7050QX Series 10/40G Data Center Switches Data Sheet
- Github repo: Nvidia (Mellanox) SAI implementation
Developer Guide
Code Repositories
The code of SONiC is hosted on the sonic-net account on GitHub, with over 30 repositories. It can be a bit overwhelming at first, but don't worry, we'll go through them together here.
Core Repositories
First, let's look at the two most important core repositories in SONiC: SONiC and sonic-buildimage.
Landing Repository: SONiC
https://github.com/sonic-net/SONiC
This repository contains the SONiC Landing Page and a large number of documents, Wiki, tutorials, slides from past talks, and so on. This repository is the most commonly used by newcomers, but note that there is no code in this repository, only documentation.
Image Build Repository: sonic-buildimage
https://github.com/sonic-net/sonic-buildimage
Why is this build repository so important to us? Unlike other projects, the build repository of SONiC is actually its main repository! This repository contains:
- All the feature implementation repositories, in the form of git submodules (under the
srcdirectory). - Support files for each device from switch manufactures (under the
devicedirectory), such as device configuration files for each model of switch, scripts, and so on. For example, my switch is an Arista 7050QX-32S, so I can find its support files in thedevice/arista/x86_64-arista_7050_qx32sdirectory. - Support files provided by all ASIC chip manufacturers (in the
platformdirectory), such as drivers, BSP, and low-level support scripts for each platform. Here we can see support files from almost all major chip manufacturers, such as Broadcom, Mellanox, etc., as well as implementations for simulated software switches, such as vs and p4. But for protecting IPs from each vendor, most of the time, the repo only contains the Makefiles that downloads these things for build purpose. - Dockerfiles for building all container images used by SONiC (in the
dockersdirectory). - Various general configuration files and scripts (in the
filesdirectory). - Dockerfiles for the build containers used for building (in the
sonic-slave-*directories). - And more...
Because this repository brings all related resources together, we basically only need to checkout this single repository to get all SONiC's code. It makes searching and navigating the code much more convenient than checking out the repos one by one!
Feature Repositories
In addition to the core repositories, SONiC also has many feature repositories, which contain the implementations of various containers and services. These repositories are imported as submodules in the src directory of sonic-buildimage. If we would like to modify and contribute to SONiC, we also need to understand them.
SWSS (Switch State Service) Related Repositories
As introduced in the previous section, the SWSS container is the brain of SONiC. In SONiC, it consists of two repositories: sonic-swss-common and sonic-swss.
SWSS Common Library: sonic-swss-common
The first one is the common library: sonic-swss-common (https://github.com/sonic-net/sonic-swss-common).
This repository contains all the common functionalities needed by *mgrd and *syncd services, such as logger, JSON, netlink encapsulation, Redis operations, and various inter-service communication mechanisms based on Redis. Although it was initially intended for swss services, its extensive functionalities have led to its use in many other repositories, such as swss-sairedis and swss-restapi.
Main SWSS Repository: sonic-swss
Next is the main SWSS repository: sonic-swss (https://github.com/sonic-net/sonic-swss).
In this repository, we can find:
- Most of the
*mgrdand*syncdservices:orchagent,portsyncd/portmgrd/intfmgrd,neighsyncd/nbrmgrd,natsyncd/natmgrd,buffermgrd,coppmgrd,macsecmgrd,sflowmgrd,tunnelmgrd,vlanmgrd,vrfmgrd,vxlanmgrd, and more. swssconfig: Located in theswssconfigdirectory, used to restore FDB and ARP tables during fast reboot.swssplayer: Also in theswssconfigdirectory, used to record all configuration operations performed through SWSS, allowing us to replay them for troubleshooting and debugging.- Even some services not in the SWSS container, such as
fpmsyncd(BGP container) andteamsyncd/teammgrd(teamd container).
SAI/Platform Related Repositories
Next is the Switch Abstraction Interface (SAI). Although SAI was proposed by Microsoft and released version 0.1 in March 2015, by September 2015, before SONiC had even released its first version, it was already accepted by OCP as a public standard. This shows how quickly SONiC and SAI was getting supports from the community and vendors.
Overall, the SAI code is divided into two parts:
- OpenComputeProject/SAI under OCP: https://github.com/opencomputeproject/SAI. This repository contains all the code related to the SAI standard, including SAI header files, behavior models, test cases, documentation, and more.
- sonic-sairedis under SONiC: https://github.com/sonic-net/sonic-sairedis. This repository contains all the code used by SONiC to interact with SAI, such as the syncd service and various debugging tools like
saiplayerfor replay andsaidumpfor exporting ASIC states.
In addition to these two repositories, there is another platform-related repository, such as sonic-platform-vpp, which uses SAI interfaces to implement data plane functionalities through VPP, essentially acting as a high-performance soft switch. I personally feel it might be merged into the buildimage repository in the future as part of the platform directory.
Management Service (mgmt) Related Repositories
Next are all the repositories related to management services in SONiC:
| Name | Description |
|---|---|
| sonic-mgmt-common | Base library for management services, containing translib, YANG model-related code |
| sonic-mgmt-framework | REST Server implemented in Go, acting as the REST Gateway in the architecture diagram below (process name: rest_server) |
| sonic-gnmi | Similar to sonic-mgmt-framework, this is the gNMI (gRPC Network Management Interface) Server based on gRPC in the architecture diagram below |
| sonic-restapi | Another configuration management REST Server implemented in Go. Unlike mgmt-framework, this server directly operates on CONFIG_DB upon receiving messages, instead of using translib (not shown in the diagram, process name: go-server-server) |
| sonic-mgmt | Various automation scripts (in the ansible directory), tests (in the tests directory), test bed setup and test reporting (in the test_reporting directory), and more |
Here is the architecture diagram of SONiC management services for reference [4]:
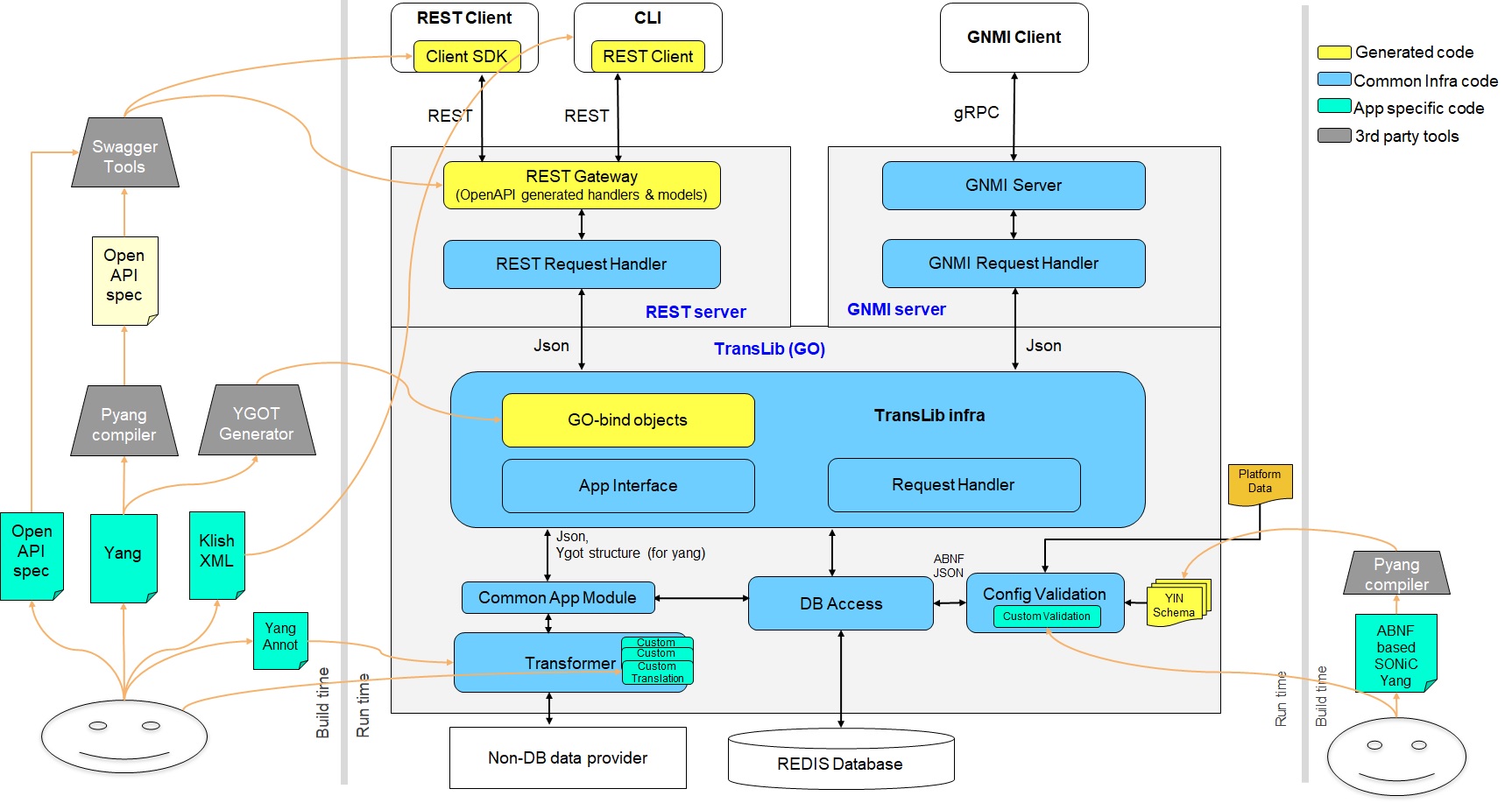
Platform Monitoring Related Repositories: sonic-platform-common and sonic-platform-daemons
The following two repositories are related to platform monitoring and control, such as LEDs, fans, power supplies, thermal control, and more:
| Name | Description |
|---|---|
| sonic-platform-common | A base package provided to manufacturers, defining interfaces for accessing fans, LEDs, power management, thermal control, and other modules, all implemented in Python |
| sonic-platform-daemons | Contains various monitoring services running in the pmon container in SONiC, such as chassisd, ledd, pcied, psud, syseepromd, thermalctld, xcvrd, ycabled. All these services are implemented in Python, and used for monitoring and controlling the platform modules, by calling the interface implementations provided by manufacturers. |
Other Feature Repositories
In addition to the repositories above, SONiC has many repositories implementing various functionalities. They can be services or libraries described in the table below:
| Repository | Description |
|---|---|
| sonic-frr | FRRouting, implementing various routing protocols, so in this repository, we can find implementations of routing-related processes like bgpd, zebra, etc. |
| sonic-snmpagent | Implementation of AgentX SNMP subagent (sonic_ax_impl), used to connect to the Redis database and provide various information needed by snmpd. It can be understood as the control plane of snmpd, while snmpd is the data plane, responding to external SNMP requests |
| sonic-linkmgrd | Dual ToR support, checking the status of links and controlling ToR connections |
| sonic-dhcp-relay | DHCP relay agent |
| sonic-dhcpmon | Monitors the status of DHCP and reports to the central Redis database |
| sonic-dbsyncd | lldp_syncd service, but the repository name is not well-chosen, called dbsyncd |
| sonic-pins | Google's P4-based network stack support (P4 Integrated Network Stack, PINS). More information can be found on the PINS website |
| sonic-stp | STP (Spanning Tree Protocol) support |
| sonic-ztp | Zero Touch Provisioning |
| DASH | Disaggregated API for SONiC Hosts |
| sonic-host-services | Services running on the host, providing support to services in containers via dbus, such as saving and reloading configurations, saving dumps, etc., similar to a host broker |
| sonic-fips | FIPS (Federal Information Processing Standards) support, containing various patch files added to support FIPS standards |
| sonic-wpa-supplicant | Support for various wireless network protocols |
Tooling Repository: sonic-utilities
https://github.com/sonic-net/sonic-utilities
This repository contains all the command-line tools for SONiC:
config,show,cleardirectories: These are the implementations of the three main SONiC CLI commands. Note that the specific command implementations may not necessarily be in these directories; many commands are implemented by calling other commands, with these directories providing an entry point.scripts,sfputil,psuutil,pcieutil,fwutil,ssdutil,acl_loaderdirectories: These directories provide many tool commands, but most are not directly used by users; instead, they are called by commands in theconfig,show, andcleardirectories. For example, theshow platform fancommand is implemented by calling thefanshowcommand in thescriptsdirectory.utilities_common,flow_counter_util,syslog_utildirectories: Similar to the above, but they provide base classes that can be directly imported and called in Python.- There are also many other commands:
fdbutil,pddf_fanutil,pddf_ledutil,pddf_psuutil,pddf_thermalutil, etc., used to view and control the status of various modules. connectandconsutildirectories: Commands in these directories are used to connect to and manage other SONiC devices.crmdirectory: Used to configure and view CRM (Critical Resource Monitoring) in SONiC. This command is not included in theconfigandshowcommands, so users can use it directly.pfcdirectory: Used to configure and view PFC (Priority-based Flow Control) in SONiC.pfcwddirectory: Used to configure and view PFC Watch Dog in SONiC, such as starting, stopping, modifying polling intervals, and more.
Kernel Patches: sonic-linux-kernel
https://github.com/sonic-net/sonic-linux-kernel
Although SONiC is based on Debian, the default Debian kernel may not necessarily run SONiC, such as certain modules not being enabled by default or issues with older drivers. Therefore, SONiC requires some modifications to the Linux kernel. This repository is used to store all the kernel patches.
References
- SONiC Architecture
- SONiC Source Repositories
- SONiC Management Framework
- SAI API
- SONiC Critical Resource Monitoring
- SONiC Zero Touch Provisioning
- SONiC Critical Resource Monitoring
- SONiC P4 Integrated Network Stack
- SONiC Disaggregated API for Switch Hosts
- SAI spec for OCP
- PFC Watchdog
Build
To ensure that we can successfully build SONiC on any platform as well, SONiC leverages docker to build its build environment. It installs all tools and dependencies in a docker container of the corresponding Debian version, mounts its code into the container, and then start the build process inside the container. This way, we can easily build SONiC on any platform without worrying about dependency mismatches. For example, some packages in Debian have higher versions than in Ubuntu, which might cause unexpected errors during build time or runtime.
Setup the Build Environment
Install Docker
To support the containerized build environment, the first step is to ensure that Docker is installed on our machine.
You can refer to the official documentation for Docker installation methods. Here, we briefly introduce the installation method for Ubuntu.
First, we need to add docker's source and certificate to the apt source list:
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
Then, we can quickly install docker via apt:
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
After installing docker, we need to add the current user to the docker user group and log out and log back in. This way, we can run any docker commands without sudo! This is very important because subsequent SONiC builds do not allow the use of sudo.
sudo gpasswd -a ${USER} docker
After installation, don't forget to verify the installation with the following command (note, no sudo is needed here!):
docker run hello-world
Install Other Dependencies
sudo apt install -y python3-pip
pip3 install --user j2cli
Pull the Code
In Chapter 3.1 Code Repositories, we mentioned that the main repository of SONiC is sonic-buildimage. It is also the only repo we need to focus on for now.
Since this repository includes all other build-related repositories as submodules, we need to use the --recurse-submodules option when pulling the code with git:
git clone --recurse-submodules https://github.com/sonic-net/sonic-buildimage.git
If you forget to pull the submodules when pulling the code, you can make up for it with the following command:
git submodule update --init --recursive
After the code is downloaded, or for an existing repo, we can initialize the compilation environment with the following command. This command updates all current submodules to the required versions to help us successfully compile:
sudo modprobe overlay
make init
Set Your Target Platform
Although SONiC supports many different types of switches, different models of switches use different ASICs, which means different drivers and SDKs. Although SONiC uses SAI to hide these differences and provide a unified interface for the upper layers. However, we need to set target platform correctly to ensure that the right SAI will be used, so the SONiC we build can run on our target devices.
Currently, SONiC mainly supports the following platforms:
- broadcom
- mellanox
- marvell
- barefoot
- cavium
- centec
- nephos
- innovium
- vs
After confirming the target platform, we can configure our build environment with the following command:
make PLATFORM=<platform> configure
# e.g.: make PLATFORM=mellanox configure
All make commands (except make init) will first check and create all Debian version docker builders: bookwarm, bullseye, stretch, jessie, buster. Each builder takes tens of minutes to create, which is unnecessary for our daily development. Generally, we only need to create the latest version (currently bookwarm). The specific command is as follows:
NO_BULLSEYE=1 NOJESSIE=1 NOSTRETCH=1 NOBUSTER=1 make PLATFORM=<platform> configure
To make future development more convenient and avoid entering these every time, we can set these environment variables in ~/.bashrc, so that every time we open the terminal, they will be set automatically.
export NOBULLSEYE=1
export NOJESSIE=1
export NOSTRETCH=1
export NOBUSTER=1
Build the Code
Build All Code
After setting the platform, we can start compiling the code:
# The number of jobs can be the number of cores on your machine.
# Say, if you have 16 cores, then feel free to set it to 16 to speed up the build.
make SONIC_BUILD_JOBS=4 all
For daily development, we can also add SONIC_BUILD_JOBS and other variables above to ~/.bashrc:
export SONIC_BUILD_JOBS=<number of cores>
Build Debug Image
To improve the debug experience, SONiC also supports building debug image. During build, SONiC will make sure the symbols are kept and debug tools are installed inside all the containers, such as gdb. This will help us debug the code more easily.
To build the debug image, we can use INSTALL_DEBUG_TOOLS build option:
INSTALL_DEBUG_TOOLS=y make all
Build Specific Package
From SONiC's Build Pipeline, we can see that compiling the entire project is very time-consuming. Most of the time, our code changes only affect a small part of the code. So, is there a way to reduce our compilation workload? Gladly, yes! We can specify the make target to build only the target or package we need.
In SONiC, the files generated by each subproject can be found in the target directory. For example:
- Docker containers: target/
.gz, e.g., target/docker-orchagent.gz - Deb packages: target/debs/
/ .deb, e.g., target/debs/bullseye/libswsscommon_1.0.0_amd64.deb - Python wheels: target/python-wheels/
/ .whl, e.g., target/python-wheels/bullseye/sonic_utilities-1.2-py3-none-any.whl
After figuring out the package we need to build, we can delete its generated files and then call the make command again. Here we use libswsscommon as an example:
# Remove the deb package for bullseye
rm target/debs/bullseye/libswsscommon_1.0.0_amd64.deb
# Build the deb package for bullseye
make target/debs/bullseye/libswsscommon_1.0.0_amd64.deb
Check and Handle Build Errors
If an error occurs during the build process, we can check the log file of the failed project to find the specific reason. In SONiC, each subproject generates its related log file, which can be easily found in the target directory, such as:
$ ls -l
...
-rw-r--r-- 1 r12f r12f 103M Jun 8 22:35 docker-database.gz
-rw-r--r-- 1 r12f r12f 26K Jun 8 22:35 docker-database.gz.log // Log file for docker-database.gz
-rw-r--r-- 1 r12f r12f 106M Jun 8 22:44 docker-dhcp-relay.gz
-rw-r--r-- 1 r12f r12f 106K Jun 8 22:44 docker-dhcp-relay.gz.log // Log file for docker-dhcp-relay.gz
If we don't want to check the log files every time, then fix errors and recompile in the root directory, SONiC provides another more convenient way that allows us to stay in the docker builder after build. This way, we can directly go to the corresponding directory to run the make command to recompile the things you need:
# KEEP_SLAVE_ON=yes make <target>
KEEP_SLAVE_ON=yes make target/debs/bullseye/libswsscommon_1.0.0_amd64.deb
KEEP_SLAVE_ON=yes make all
Some parts of the code in some repositories will not be build during full build. For example, gtest in sonic-swss-common. So, when using this way to recompile, please make sure to check the original repository's build guidance to avoid errors, such as: https://github.com/sonic-net/sonic-swss-common#build-from-source.
Get the Correct Image File
After compilation, we can find the image files we need in the target directory. However, there will be many different types of SONiC images, so which one should we use? This mainly depends on what kind of BootLoader or Installer the switch uses. The mapping is as below:
| Bootloader | Suffix |
|---|---|
| Aboot | .swi |
| ONIE | .bin |
| Grub | .img.gz |
Partial Upgrade
Obviously, during development, build the image and then performing a full installation each time is very inefficient. So, we could choose not to install the image but directly upgrading certain deb packages as partial upgrade, which could improving our development efficiency.
First, we can upload the deb package to the /etc/sonic directory of the switch. The files in this directory will be mapped to the /etc/sonic directory of all containers. Then, we can enter the container and use the dpkg command to install the deb package, as follows:
# Enter the docker container
docker exec -it <container> bash
# Install deb package
dpkg -i <deb-package>
References
- SONiC Build Guide
- Install Docker Engine
- Github repo: sonic-buildimage
- SONiC Supported Devices and Platforms
- Wrapper for starting make inside sonic-slave container
Testing
Debugging
Debugging SAI
Communication
There are three main communication mechanisms in SONiC: communication using kernel, Redis-based inter-service communication, and ZMQ-based inter-service communication.
- There are two main methods for communication using kernel: command line calls and Netlink messages.
- Redis-based inter-service communication: There are 4 different communication channel based on Redis - SubscriberStateTable, NotificationProducer/Consumer, Producer/ConsumerTable, and Producer/ConsumerStateTable. Although they are all based on Redis, their use case can be very different.
- ZMQ-based inter-service communication: This communication mechanism is currently only used in the communication between
orchagentandsyncd.
Although most communication mechanisms support multi-consumer PubSub mode, please note: in SONiC, majority of communication (except some config table or state table via SubscriberStateTable) is point-to-point, meaning one producer will only send the message to one consumer. It is very rare to have a situation where one producer sending data to multiple consumers!
Channels like Producer/ConsumerStateTable essentually only support point-to-point communication. If multiple consumers appear, the message will only be delivered to one of the customers, causing all other consumer missing updates.
The implementation of all these basic communication mechanisms is in the common directory of the sonic-swss-common repo. Additionally, to facilitate the use of various services, SONiC has build a wrapper layer called Orch in sonic-swss, which helps simplify the upper-layer services.
In this chapter, we will dive into the implementation of these communication mechanisms!
References
Communicate via Kernel
Command Line Invocation
The simplest way SONiC communicates with the kernel is through command-line calls, which are implemented in common/exec.h. The interface is straight-forward:
// File: common/exec.h
// Namespace: swss
int exec(const std::string &cmd, std::string &stdout);
Here, cmd is the command to execute, and stdout captures the command output. The exec function is a synchronous call that blocks until the command finishes. Internally, it creates a child process via popen and retrieves output via fgets. However, although this function returns output, it is rarely used in practice. Most code only checks the return value for success, and sometimes even error logs won't be logged in the output.
Despite its simplicity, this function is widely used, especially in various *mgrd services. For instance, portmgrd calls it to set each port's status:
// File: sonic-swss - cfgmgr/portmgr.cpp
bool PortMgr::setPortAdminStatus(const string &alias, const bool up)
{
stringstream cmd;
string res, cmd_str;
// ip link set dev <port_name> [up|down]
cmd << IP_CMD << " link set dev " << shellquote(alias) << (up ? " up" : " down");
cmd_str = cmd.str();
int ret = swss::exec(cmd_str, res);
// ...
Why is a command-line call considered a communication mechanism?
Because when a *mgrd service modifies the system using exec, it triggers netlink events (which will be mentioned in later chapters), notifying other services like *syncd to take corresponding actions. This indirect communication helps us better understand SONiC's workflows.
References
Netlink
Netlinkis the message-based communication mechanism provided by Linux kernel and used between the kernel and user-space processes. It is implemented via socket and custom protocol families. It can be used to deliver various types of kernel messages, including network device status, routing table updates, firewall rule changes, and system resource usage. SONiC's *sync services heavily utilize Netlink to monitor changes of network devices in the system, synchronize the latest status to Redis, and notify other services to make corresponding updates.
The main implementation of netlink communication channel is done by these files:
The class diagram is as follows:
In this diagram:
- Netlink: Wraps the netlink socket interface and provides an interface for sending netlink messages and a callback for receiving messages.
- NetDispatcher: A singleton that provides an interface for registering handlers. When a raw netlink message is received, it calls NetDispatcher to parse them into
nl_objectobjects and then dispatches them to the corresponding handler based on the message type. - NetMsg: The base class for netlink message handlers, which only provides the
onMsginterface without a default implementation.
For example, when portsyncd starts, it creates a Netlink object to listen for link-related status changes and implements the NetMsg interface to handle the link messages. The specific implementation is as follows:
// File: sonic-swss - portsyncd/portsyncd.cpp
int main(int argc, char **argv)
{
// ...
// Create Netlink object to listen to link messages
NetLink netlink;
netlink.registerGroup(RTNLGRP_LINK);
// Here SONiC requests a full dump of the current state to get the status of all links
netlink.dumpRequest(RTM_GETLINK);
cout << "Listen to link messages..." << endl;
// ...
// Register handler for link messages
LinkSync sync(&appl_db, &state_db);
NetDispatcher::getInstance().registerMessageHandler(RTM_NEWLINK, &sync);
NetDispatcher::getInstance().registerMessageHandler(RTM_DELLINK, &sync);
// ...
}
The LinkSync class above is an implementation of NetMsg, providing the onMsg interface for handling link messages:
// File: sonic-swss - portsyncd/linksync.h
class LinkSync : public NetMsg
{
public:
LinkSync(DBConnector *appl_db, DBConnector *state_db);
// NetMsg interface
virtual void onMsg(int nlmsg_type, struct nl_object *obj);
// ...
};
// File: sonic-swss - portsyncd/linksync.cpp
void LinkSync::onMsg(int nlmsg_type, struct nl_object *obj)
{
// ...
// Write link state to Redis DB
FieldValueTuple fv("oper_status", oper ? "up" : "down");
vector<FieldValueTuple> fvs;
fvs.push_back(fv);
m_stateMgmtPortTable.set(key, fvs);
// ...
}
References
Redis-based Channels
To facilitate communication between services, SONiC provides a messaging layer that is built on top of the Redis. On high-level, it contains 2 layers:
- First layer wraps frequenctly used redis operations and provide table abstraction on top of it.
- Second layer provides different channels for inter-service communication to satisfy various communication channel requirements.
Now, let's dive into them one by one.
Redis Wrappers
Redis Database Operation Layer
The first layer, which is also the lowest layer, is the Redis database operation layer. It wraps various basic commands, such as DB connection, command execution, event notification callback interfaces, etc. The specific class diagram is as follows:
Among them:
- RedisContext: Wraps and maintains the connection to Redis, and closes the connection when it is destroyed.
- DBConnector: Wraps all the underlying Redis commands used, such as
SET,GET,DEL, etc. - RedisTransactioner: Wraps Redis transaction operations, used to execute multiple commands in a transaction, such as
MULTI,EXEC, etc. - RedisPipeline: Wraps the hiredis redisAppendFormattedCommand API, providing an asynchronous interface for executing Redis commands similar to a queue (although most usage methods are still synchronous). It is also one of the few classes that wraps the
SCRIPT LOADcommand, used to load Lua scripts in Redis to implement stored procedures. Most classes in SONiC that need to execute Lua scripts will use this class for loading and calling. - RedisSelect: Implements the Selectable interface to support the epoll-based event notification mechanism (Event Polling). Mainly used to trigger epoll callbacks when we receive a reply from Redis (we will introduce this in more detail later).
- SonicDBConfig: This class is a "static class" that mainly implements the reading and parsing of the SONiC DB configuration file. Other database operation classes will use this class to obtain any configuration information if needed.
Table Abstraction Layer
Above the Redis database operation layer is the table abstraction layer established by SONiC using the keys in Redis. Since the format of each Redis key is <table-name><separator><key-name>, SONiC needs to craft or parse it, when accessing the database. For more details on how the database is designed, please refer to the database section for more information.
The main class diagram of related classes is as follows:
In this diagram, we have three key classes:
- TableBase: This class is the base class for all tables. It mainly wraps the basic information of the table, such as the table name, Redis key packaging, the name of the channel used for communication when each table is modified, etc.
- Table: This class wraps the CRUD operations for each table. It contains the table name and separator, so the final key can be constructed when called.
- ConsumerTableBase: This class is the base class for various SubscriptionTables. It mainly wraps a simple queue and its pop operation (yes, only pop, no push, because it is for consumers only), for upper layer calls.
References
SubscribeStateTable
The most straight-forward redis-based communication channel is SubscriberStateTable.
The idea is to use the built-in keyspace notification mechanism of the Redis database [4]. When any value in the Redis database changes, Redis sends two keyspace event notifications: one is <op> on __keyspace@<db-id>__:<key> and the other is <key> on __keyevent@<db-id>__:<op>. For example, deleting a key in database 0 triggers:
PUBLISH __keyspace@0__:foo del
PUBLISH __keyevent@0__:del foo
SubscriberStateTable listens for the first event notification and then calls the corresponding callback function. The main classes related to it are shown in this diagram, where we can see it inherits from ConsumerTableBase because it is a consumer of Redis messages:
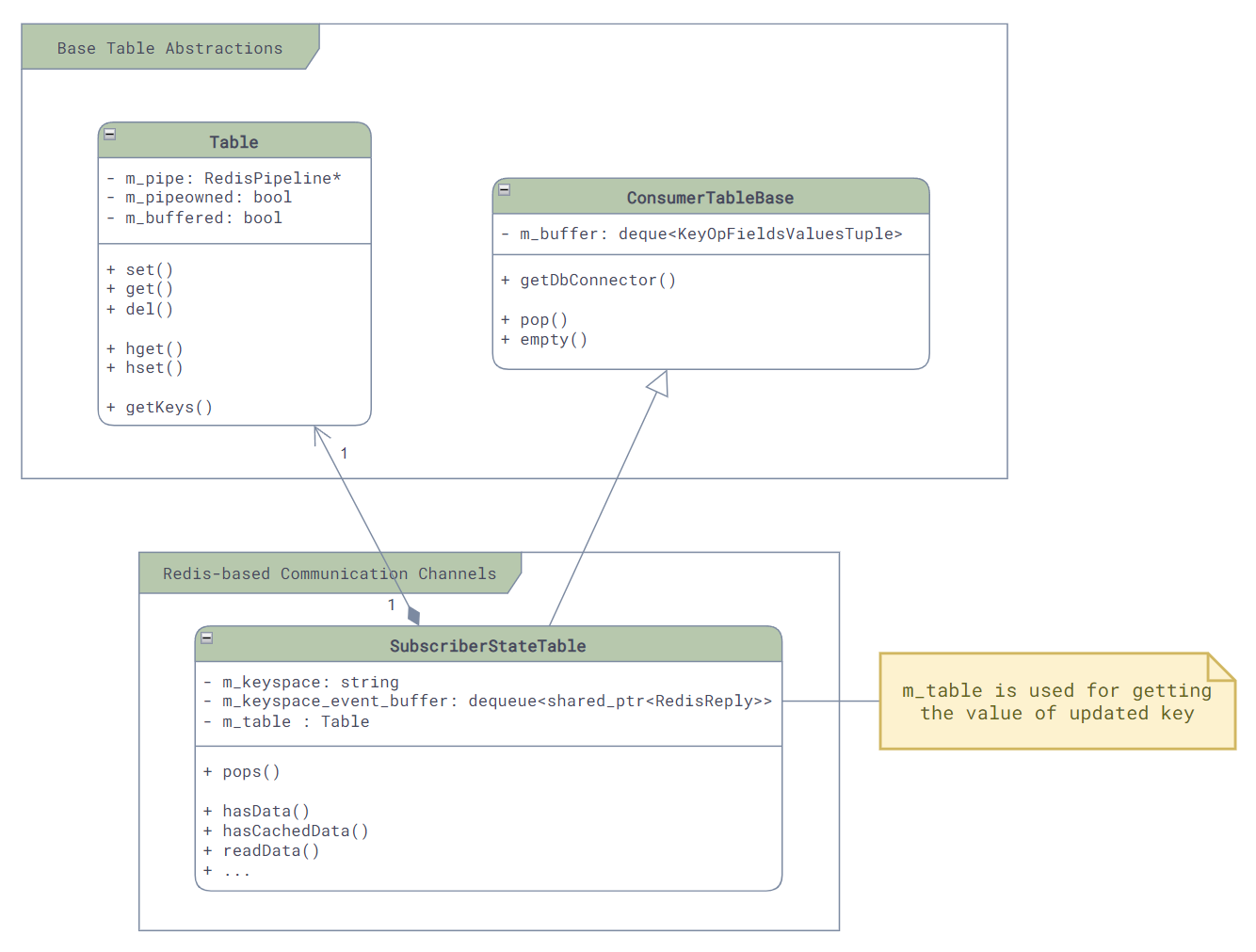
Initialization
From the initialization code, we can see how it subscribes to Redis event notifications:
// File: sonic-swss-common - common/subscriberstatetable.cpp
SubscriberStateTable::SubscriberStateTable(DBConnector *db, const string &tableName, int popBatchSize, int pri)
: ConsumerTableBase(db, tableName, popBatchSize, pri), m_table(db, tableName)
{
m_keyspace = "__keyspace@";
m_keyspace += to_string(db->getDbId()) + "__:" + tableName + m_table.getTableNameSeparator() + "*";
psubscribe(m_db, m_keyspace);
// ...
Event handling
SubscriberStateTable handles the event reception and distribution in two main functions:
readData(): Reads pending events from Redis and puts them into the ConsumerTableBase queuepops(): Retrieves the raw events from the queue, parses and passes them to the caller via function parameters
// File: sonic-swss-common - common/subscriberstatetable.cpp
uint6464_t SubscriberStateTable::readData()
{
// ...
reply = nullptr;
int status;
do {
status = redisGetReplyFromReader(m_subscribe->getContext(), reinterpret_cast<void**>(&reply));
if(reply != nullptr && status == REDIS_OK) {
m_keyspace_event_buffer.emplace_back(make_shared<RedisReply>(reply));
}
} while(reply != nullptr && status == REDIS_OK);
// ...
return 0;
}
void SubscriberStateTable::pops(deque<KeyOpFieldsValuesTuple> &vkco, const string& /*prefix*/)
{
vkco.clear();
// ...
// Pop from m_keyspace_event_buffer, which is filled by readData()
while (auto event = popEventBuffer()) {
KeyOpFieldsValuesTuple kco;
// Parsing here ...
vkco.push_back(kco);
}
m_keyspace_event_buffer.clear();
}
References
- SONiC Architecture
- Github repo: sonic-swss
- Github repo: sonic-swss-common
- Redis keyspace notifications
NotificationProducer / NotificationConsumer
When it comes to message communication, there is no way we can bypass message queues. And this is the second communication channel in SONiC - NotificationProducer and NotificationConsumer.
This communication channel is implemented using Redis's built-in PubSub mechanism, wrapping the PUBLISH and SUBSCRIBE commands. However, because PUBLISH needs everything being send to be serialized in the command, due to API limitations [5], these commands are not suitable for passing large data. Hence, in SONiC, it is only used in limited places, such as simple notification scenarios (e.g., timeout checks or restart checks in orchagent), which won't have large payload, such as user configurations or data:
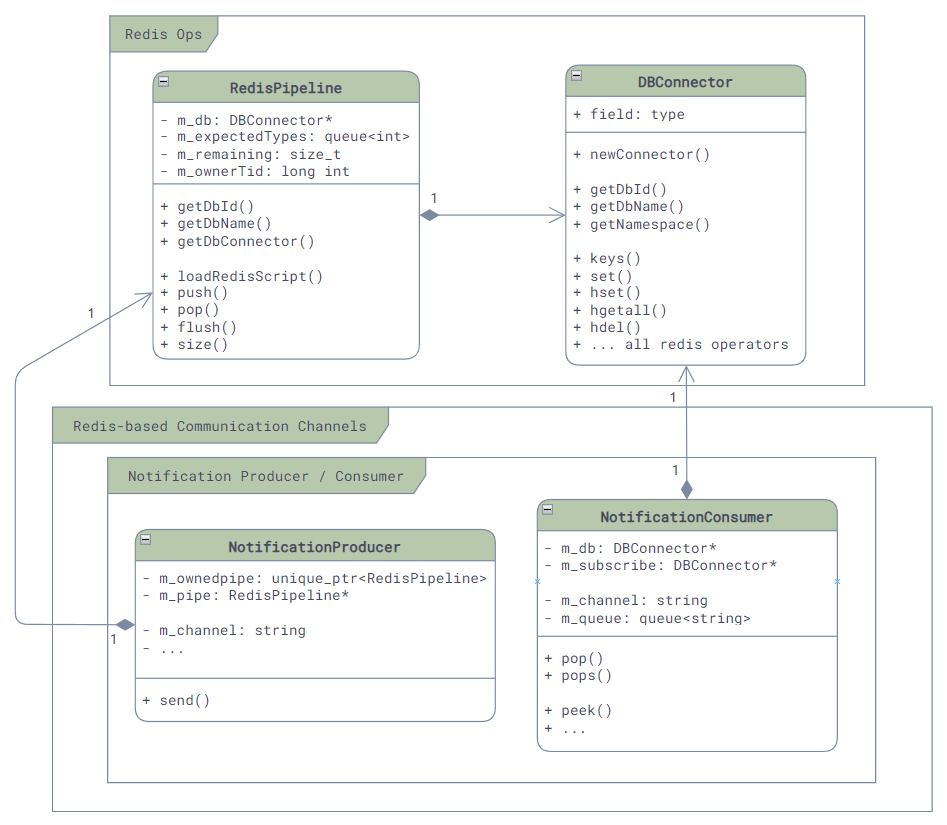
In this communication channel, the producer side performs two main tasks:
- Package the message into JSON format.
- Call Redis command
PUBLISHto send it.
Because PUBLISH can only carry a single message, the "op" and "data" fields are placed at the front of "values", then the buildJson function is called to package them into a JSON array:
int64_t swss::NotificationProducer::send(const std::string &op, const std::string &data, std::vector<FieldValueTuple> &values)
{
// Pack the op and data into values array, then pack everything into a JSON string as the message
FieldValueTuple opdata(op, data);
values.insert(values.begin(), opdata);
std::string msg = JSon::buildJson(values);
values.erase(values.begin());
// Publish message to Redis channel
RedisCommand command;
command.format("PUBLISH %s %s", m_channel.c_str(), msg.c_str());
// ...
RedisReply reply = m_pipe->push(command);
reply.checkReplyType(REDIS_REPLY_INTEGER);
return reply.getReply<long long int>();
}
The consumer side uses the SUBSCRIBE command to receive all notifications:
void swss::NotificationConsumer::subscribe()
{
// ...
m_subscribe = new DBConnector(m_db->getDbId(),
m_db->getContext()->unix_sock.path,
NOTIFICATION_SUBSCRIBE_TIMEOUT);
// ...
// Subscribe to Redis channel
std::string s = "SUBSCRIBE " + m_channel;
RedisReply r(m_subscribe, s, REDIS_REPLY_ARRAY);
}
References
- SONiC Architecture
- Github repo: sonic-swss
- Github repo: sonic-swss-common
- Redis keyspace notifications
- Redis client handling
ProducerTable / ConsumerTable
Although NotificationProducer and NotificationConsumer is straight-forward, but they are not suitable for passing large data. Therefore, SONiC provides another message-queue-based communication mechanism that works in similar way - ProducerTable and ConsumerTable.
This channel leverages the Redis list to pass the message. Unlike Notification, which has limited message capacity, it stores all the message data in a Redis list with a very slim custom messsage format. This solves the message size limitation in Notification. In SONiC, it is mainly used in FlexCounter, the syncd service, and ASIC_DB.
Message format
In this channel, a message is a triplet (Key, FieldValuePairs, Op) and will be pushed into the Redis list (Key = <table-name>_KEY_VALUE_OP_QUEUE) as 3 list items:
Keyis table name and key (e.g.,SAI_OBJECT_TYPE_SWITCH:oid:0x21000000000000).FieldValuePairsare the field that needs to be updated in the database and their values, which is serialized into a JSON string:"[\"Field1\", \"Value1\", \"Field2\", \"Value2\", ...]".Opis the operation to be performed (e.g., Set, Get, Del, etc.)
Once the message is pushed into the Redis list, a notification will be published to a specific channel (Key = <table-name>_CHANNEL) with only a single character "G" as payload, indicating that there is a new message in the list.
So, when using this channel, we can imaging the actual data stored in the Redis:
- In the channel:
["G", "G", ...] - In the list:
["Key1", "FieldValuePairs1", "Op1", "Key2", "FieldValuePairs2", "Op2", ...]
Queue operations
Using this message format, ProducerTable and ConsumerTable provides two queue operations:
- Enqueue:
ProducerTableuses a Lua script to atomically write the message triplet into the Redis list and then publishes an update notification to a specific channel. - Pop:
ConsumerTablealso uses a Lua script to atomically read the message triplet from the message queue and writes the requested changes to the database during the read process.
Note: The atomicity of Lua scripts and MULTI/EXEC in Redis differs from the usual database ACID notion of Atomicity. Redis's atomicity is closer to Isolation in ACID: it ensures that no other command interleaves while a Lua script is running, but it does not guarantee that all commands in the script will successfully execute. For example, if the second command fails, the first one is still committed, and the subsequent commands are not executed. Refer to [5] and [6] for more details.
Its main class diagram is shown below. In ProducerTable, m_shaEnqueue and in ConsumerTable, m_shaPop are the two Lua scripts we mentioned. After they are loaded, you can call them atomically via EVALSHA:
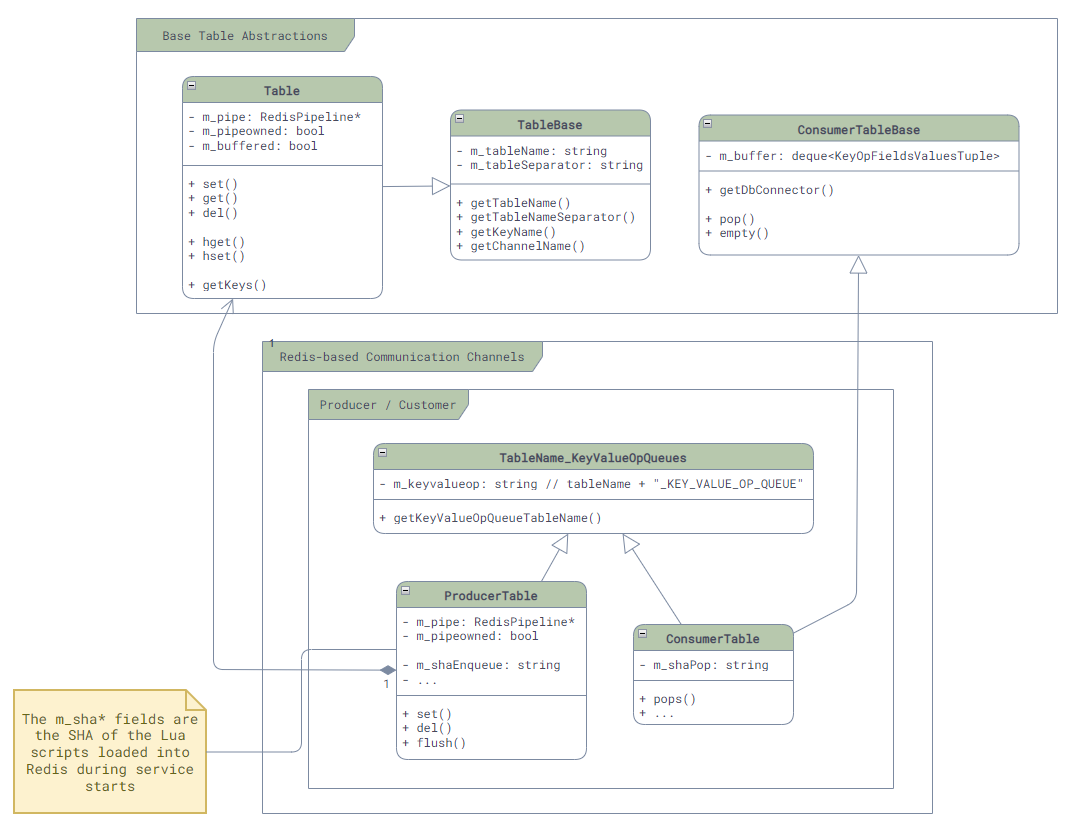
The core logic of ProducerTable is as follows, showing how values are packed into JSON and how EVALSHA is used to call Lua scripts:
// File: sonic-swss-common - common/producertable.cpp
ProducerTable::ProducerTable(RedisPipeline *pipeline, const string &tableName, bool buffered)
// ...
{
string luaEnque =
"redis.call('LPUSH', KEYS[1], ARGV[1], ARGV[2], ARGV[3]);"
"redis.call('PUBLISH', KEYS[2], ARGV[4]);";
m_shaEnque = m_pipe->loadRedisScript(luaEnque);
}
void ProducerTable::set(const string &key, const vector<FieldValueTuple> &values, const string &op, const string &prefix)
{
enqueueDbChange(key, JSon::buildJson(values), "S" + op, prefix);
}
void ProducerTable::del(const string &key, const string &op, const string &prefix)
{
enqueueDbChange(key, "{}", "D" + op, prefix);
}
void ProducerTable::enqueueDbChange(const string &key, const string &value, const string &op, const string& /* prefix */)
{
RedisCommand command;
command.format(
"EVALSHA %s 2 %s %s %s %s %s %s",
m_shaEnque.c_str(),
getKeyValueOpQueueTableName().c_str(),
getChannelName(m_pipe->getDbId()).c_str(),
key.c_str(),
value.c_str(),
op.c_str(),
"G");
m_pipe->push(command, REDIS_REPLY_NIL);
}
On the other side, ConsumerTable is slightly more complicated because it supports many types of ops. The logic is written in a separate file (common/consumer_table_pops.lua). Interested readers can explore it further:
// File: sonic-swss-common - common/consumertable.cpp
ConsumerTable::ConsumerTable(DBConnector *db, const string &tableName, int popBatchSize, int pri)
: ConsumerTableBase(db, tableName, popBatchSize, pri)
, TableName_KeyValueOpQueues(tableName)
, m_modifyRedis(true)
{
std::string luaScript = loadLuaScript("consumer_table_pops.lua");
m_shaPop = loadRedisScript(db, luaScript);
// ...
}
void ConsumerTable::pops(deque<KeyOpFieldsValuesTuple> &vkco, const string &prefix)
{
// Note that here we are processing the messages in bulk with POP_BATCH_SIZE!
RedisCommand command;
command.format(
"EVALSHA %s 2 %s %s %d %d",
m_shaPop.c_str(),
getKeyValueOpQueueTableName().c_str(),
(prefix+getTableName()).c_str(),
POP_BATCH_SIZE,
RedisReply r(m_db, command, REDIS_REPLY_ARRAY);
vkco.clear();
// Parse and pack the messages in bulk
// ...
}
Monitor
To monitor how the ProducerTable and ConsumerTable work, we can use the redis-cli monitor command to see the actual Redis commands that being executed.
# Filter to `LPUSH` and `PUBLISH` commands to help us reduce the noise.
redis-cli monitor | grep -E "LPUSH|PUBLISH"
And here is an example of the output showing a ProducerTable enqueue operation:
1735966216.139741 [1 lua] "LPUSH" "ASIC_STATE_KEY_VALUE_OP_QUEUE" "SAI_OBJECT_TYPE_SWITCH:oid:0x21000000000000" "[\"SAI_SWITCH_ATTR_AVAILABLE_IPV4_NEXTHOP_ENTRY\",\"1\"]" "Sget"
1735966216.139774 [1 lua] "PUBLISH" "ASIC_STATE_CHANNEL@1" "G"
References
- SONiC Architecture
- Github repo: sonic-swss
- Github repo: sonic-swss-common
- Redis keyspace notifications
- Redis Transactions
- Redis Atomicity with Lua
- Redis hashes
- Redis client handling
ProducerStateTable / ConsumerStateTable
Although Producer/ConsumerTable is straightforward and maintains the order of the messages, each message can only update one table key and requires JSON serialization. However, in many cases, we don't need strict ordering but need higher throughput. To optimize performance, SONiC introduces the fourth, and most frequently used, communication channel: ProducerStateTable and ConsumerStateTable.
Overview
Unlike ProducerTable, ProducerStateTable uses a Hash to store messages instead of a List. This means the order of messages will not be guranteed, but it can significantly boosts performance:
- First, no more JSON serialization, hence its overhead is gone.
- Second, batch processing:
- Multiple table updates can be merged into one (single pending update key set per table).
- If the same Field under the same Key is changed multiple times, only the latest change is preserved, merging all changes related to that Key into a single message and reducing unnecessary handling.
Producer/ConsumerStateTable is more complex under the hood than Producer/ConsumerTable. The related classes are shown in the diagram below, where m_shaSet and m_shaDel store the Lua scripts for modifying and sending messages, while m_shaPop is used to retrieve messages:
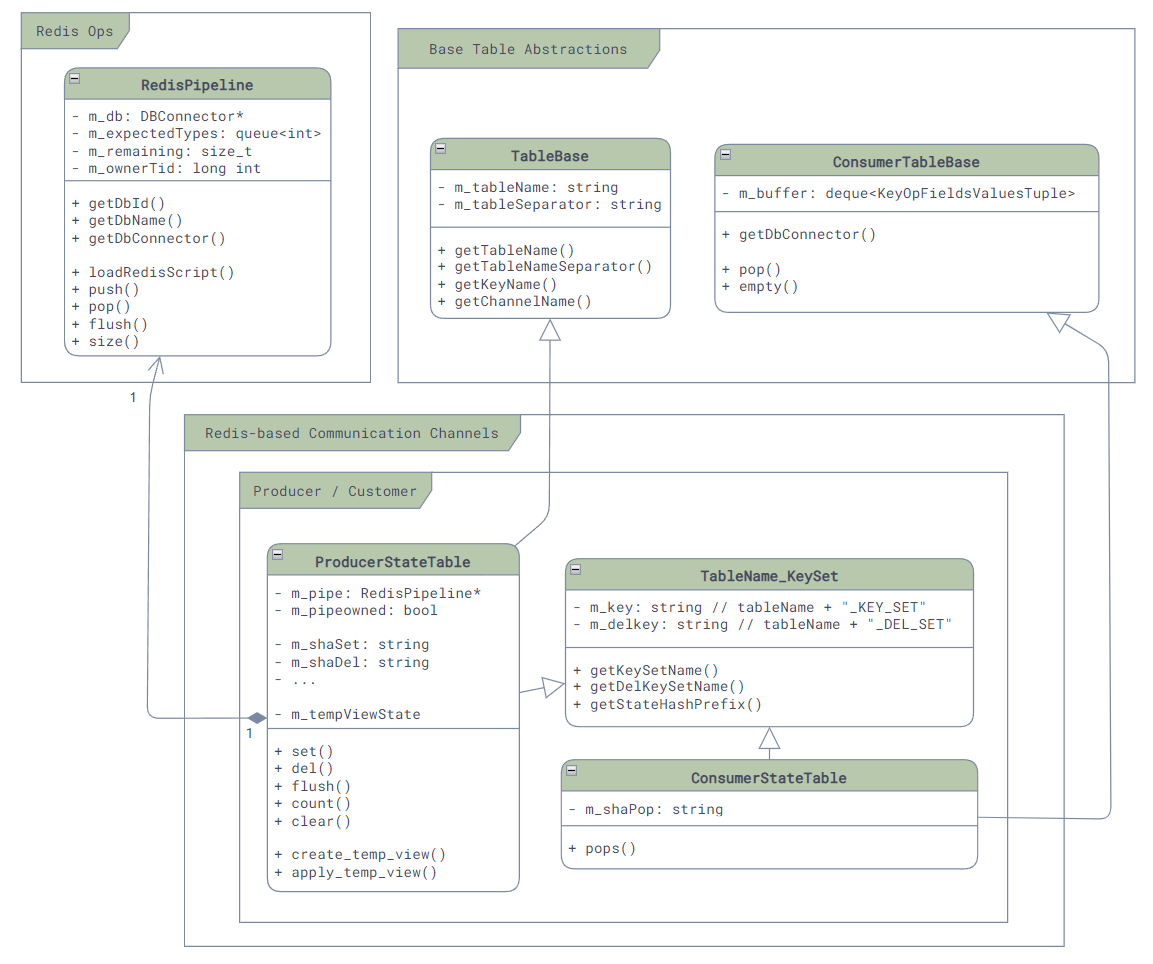
Sending messages
When sending messages:
-
Each message is stored in two parts:
- KEY_SET: keeps track of which Keys have been modified (stored as a Set at
<table-name_KEY_SET>) - A series of Hash: One Hash for each modified Key (stored at
_<redis-key-name>).
- KEY_SET: keeps track of which Keys have been modified (stored as a Set at
-
After storing a message, if the Producer finds out it's a new Key, it calls
PUBLISHto notify<table-name>_CHANNEL@<db-id>that a new Key has appeared.// File: sonic-swss-common - common/producerstatetable.cpp ProducerStateTable::ProducerStateTable(RedisPipeline *pipeline, const string &tableName, bool buffered) : TableBase(tableName, SonicDBConfig::getSeparator(pipeline->getDBConnector())) , TableName_KeySet(tableName) // ... { string luaSet = "local added = redis.call('SADD', KEYS[2], ARGV[2])\n" "for i = 0, #KEYS - 3 do\n" " redis.call('HSET', KEYS[3 + i], ARGV[3 + i * 2], ARGV[4 + i * 2])\n" "end\n" " if added > 0 then \n" " redis.call('PUBLISH', KEYS[1], ARGV[1])\n" "end\n"; m_shaSet = m_pipe->loadRedisScript(luaSet); }
Receiving messages
When receiving messages:
The consumer uses SUBSCRIBE to listen on <table-name>_CHANNEL@<db-id>. Once a new message arrives, it calls a Lua script to run HGETALL, fetch all Keys, and write them into the database.
ConsumerStateTable::ConsumerStateTable(DBConnector *db, const std::string &tableName, int popBatchSize, int pri)
: ConsumerTableBase(db, tableName, popBatchSize, pri)
, TableName_KeySet(tableName)
{
std::string luaScript = loadLuaScript("consumer_state_table_pops.lua");
m_shaPop = loadRedisScript(db, luaScript);
// ...
subscribe(m_db, getChannelName(m_db->getDbId()));
// ...
}
Example
To illustrate, here is an example of enabling Port Ethernet0:
-
First, we call
config interface startup Ethernet0from the command line to enable Ethernet0. This causesportmgrdto send a status update to APP_DB via ProducerStateTable, as shown below:EVALSHA "<hash-of-set-lua>" "6" "PORT_TABLE_CHANNEL@0" "PORT_TABLE_KEY_SET" "_PORT_TABLE:Ethernet0" "_PORT_TABLE:Ethernet0" "_PORT_TABLE:Ethernet0" "_PORT_TABLE:Ethernet0" "G" "Ethernet0" "alias" "Ethernet5/1" "index" "5" "lanes" "9,10,11,12" "speed" "40000"This command triggers the following creation and broadcast:
SADD "PORT_TABLE_KEY_SET" "_PORT_TABLE:Ethernet0" HSET "_PORT_TABLE:Ethernet0" "alias" "Ethernet5/1" HSET "_PORT_TABLE:Ethernet0" "index" "5" HSET "_PORT_TABLE:Ethernet0" "lanes" "9,10,11,12" HSET "_PORT_TABLE:Ethernet0" "speed" "40000" PUBLISH "PORT_TABLE_CHANNEL@0" "_PORT_TABLE:Ethernet0"Thus, the message is ultimately stored in APPL_DB as follows:
PORT_TABLE_KEY_SET: _PORT_TABLE:Ethernet0 _PORT_TABLE:Ethernet0: alias: Ethernet5/1 index: 5 lanes: 9,10,11,12 speed: 40000 -
When ConsumerStateTable receives the message, it also calls
EVALSHAto execute a Lua script, such as:EVALSHA "<hash-of-pop-lua>" "3" "PORT_TABLE_KEY_SET" "PORT_TABLE:" "PORT_TABLE_DEL_SET" "8192" "_"Similar to the Producer side, this script runs:
SPOP "PORT_TABLE_KEY_SET" "_PORT_TABLE:Ethernet0" HGETALL "_PORT_TABLE:Ethernet0" HSET "PORT_TABLE:Ethernet0" "alias" "Ethernet5/1" HSET "PORT_TABLE:Ethernet0" "index" "5" HSET "PORT_TABLE:Ethernet0" "lanes" "9,10,11,12" HSET "PORT_TABLE:Ethernet0" "speed" "40000" DEL "_PORT_TABLE:Ethernet0"At this point, the data update is complete.
References
- SONiC Architecture
- Github repo: sonic-swss
- Github repo: sonic-swss-common
- Redis keyspace notifications
- Redis Transactions
- Redis Atomicity with Lua
- Redis hashes
- Redis client handling
ZMQ-based Channels
Service Layer - Orch
Finally, to make it more convenient for building services, SONiC provides another layer of abstraction on top of the communication layer, offering a base class for services: Orch.
With all the lower layers, adding message communication support in Orch is relatively straightforward. The main class diagram is shown below:
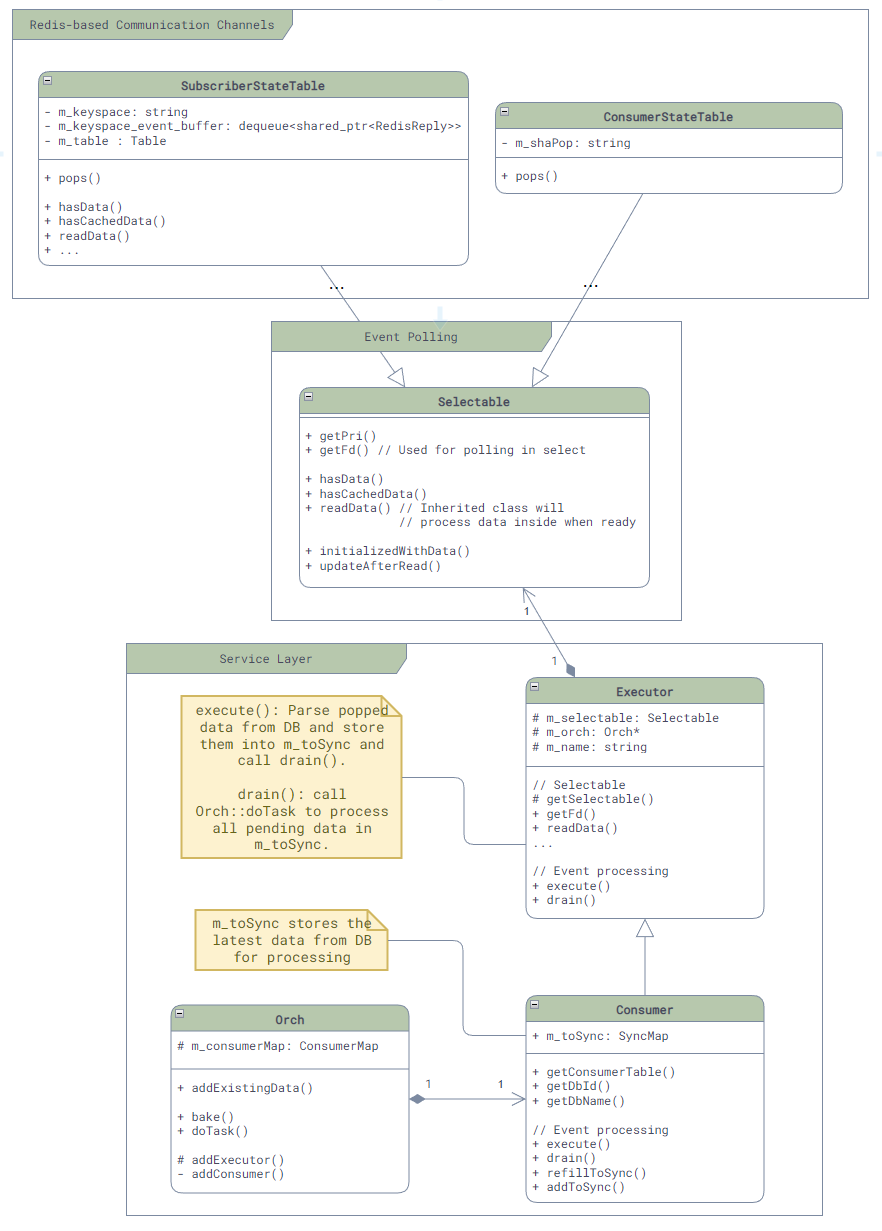
Note: Since this layer is part of the service layer, the code lives in the sonic-swss repository, not in sonic-swss-common. In addition to message communication, this class also provides many other utility functions related to service implementation (for example, log files, etc.).
We can see that Orch mainly wraps SubscriberStateTable and ConsumerStateTable to simplify and unify the message subscription. The core code is very simple and creates different Consumers based on the database type:
void Orch::addConsumer(DBConnector *db, string tableName, int pri)
{
if (db->getDbId() == CONFIG_DB || db->getDbId() == STATE_DB || db->getDbId() == CHASSIS_APP_DB) {
addExecutor(
new Consumer(
new SubscriberStateTable(db, tableName, TableConsumable::DEFAULT_POP_BATCH_SIZE, pri),
this,
tableName));
} else {
addExecutor(
new Consumer(
new ConsumerStateTable(db, tableName, gBatchSize, pri),
this,
tableName));
}
}
References
Event Dispatching and Error Handling
Epoll-based Event Dispatching
Just like many other Linux services, SONiC uses epoll at its core for event dispatching:
- Any class that supports event dispatching should inherit from
Selectableand implement two key functions:int getFd();: Returns the fd for epoll to listen on. For most services, this fd is the one used for Redis communication, so the call togetFd()ultimately delegates to the Redis library.uint64_t readData(): Reads data when an event arrives.
- Any objects that need to participate in event dispatching must register with the
Selectclass. This class registers allSelectableobjects' fds with epoll and callsSelectable'sreadData()when an event arrives.
Here's the class diagram:
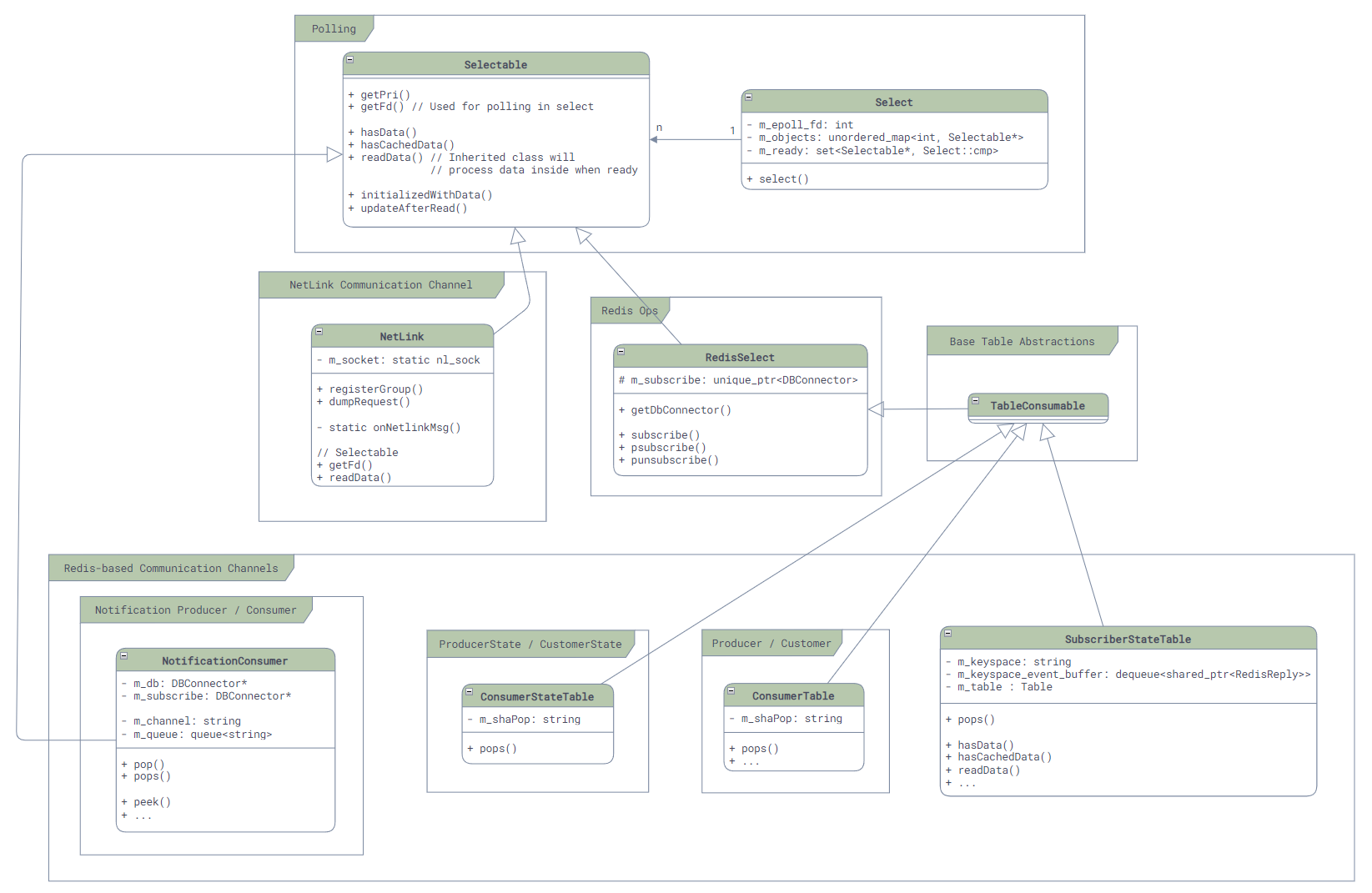
The core logic lives in the Select class, which can be simplified as follows:
int Select::poll_descriptors(Selectable **c, unsigned int timeout, bool interrupt_on_signal = false)
{
int sz_selectables = static_cast<int>(m_objects.size());
std::vector<struct epoll_event> events(sz_selectables);
int ret;
while(true) {
ret = ::epoll_wait(m_epoll_fd, events.data(), sz_selectables, timeout);
// ...
}
// ...
for (int i = 0; i < ret; ++i)
{
int fd = events[i].data.fd;
Selectable* sel = m_objects[fd];
sel->readData();
// error handling here ...
m_ready.insert(sel);
}
while (!m_ready.empty())
{
auto sel = *m_ready.begin();
m_ready.erase(sel);
// After update callback ...
return Select::OBJECT;
}
return Select::TIMEOUT;
}
However, here comes the question... where is the callback? As mentioned, readData() only reads the message and stores it in a pending queue for processing. The real processing needs to call pops(). So at which point does every upper-level message handler get called?
Here, let's look back again at portmgrd's main function. From the simplified code below, we can see - unlike a typical event loop, SONiC does not handle events with callbacks; the outermost event loop directly calls the actual handlers:
int main(int argc, char **argv)
{
// ...
// Create PortMgr, which implements Orch interface.
PortMgr portmgr(&cfgDb, &appDb, &stateDb, cfg_port_tables);
vector<Orch *> cfgOrchList = {&portmgr};
// Create Select object for event loop and add PortMgr to it.
swss::Select s;
for (Orch *o : cfgOrchList) {
s.addSelectables(o->getSelectables());
}
// Event loop
while (true)
{
Selectable *sel;
int ret;
// When anyone of the selectables gets signaled, select() will call
// into readData() and fetch all events, then return.
ret = s.select(&sel, SELECT_TIMEOUT);
// ...
// Then, we call into execute() explicitly to process all events.
auto *c = (Executor *)sel;
c->execute();
}
return -1;
}
Error Handling
Another thing about event loops is error handling. For example, if a Redis command fails, or the connection is broken, or any kind of failure happens, what will happen to our services?
SONiC's error handling is very simple: it just throws exceptions (for example, in the code that fetches command results). Then the event loop catches the exceptions, logs them, and continues:
RedisReply::RedisReply(RedisContext *ctx, const RedisCommand& command)
{
int rc = redisAppendFormattedCommand(ctx->getContext(), command.c_str(), command.length());
if (rc != REDIS_OK)
{
// The only reason of error is REDIS_ERR_OOM (Out of memory)
// ref: https://github.com/redis/hiredis/blob/master/hiredis.c
throw bad_alloc();
}
rc = redisGetReply(ctx->getContext(), (void**)&m_reply);
if (rc != REDIS_OK)
{
throw RedisError("Failed to redisGetReply with " + string(command.c_str()), ctx->getContext());
}
guard([&]{checkReply();}, command.c_str());
}
There is no specific code here for statistics or telemetry, so monitoring is somewhat weak. We also need to consider data errors (for example, partial writes leading to corrupted data), though simply restarting *syncd or *mgrd services might fix such issues because many stored data in database will be wiped out, such as APPL_DB, and the services will do a full sync on startup.
References
Core Components
In this chapter, we take a deeper look at some of the representative core components in SONiC and their workflows from a code perspective.
For helping us to read and understand, all the code shown here will be simplified to its core part to illustrate the process. If you would like to read the full code, please refer to the original code in the repository.
Additionally, the relevant file path of the code will be shared in the beginning of each code block, which is based on the SONiC's main repository: sonic-buildimage. If the code is not imported by buildimage repo, the full URL will be provided.
Syncd and SAI
Syncd Container is the container in SONiC dedicated to managing the ASIC. The key process syncd is responsible for communicating with the Redis database, loading SAI implementation, and interacting with it to handle ASIC initialization, configuration, status reporting, and so on.
Since many SONiC workflows ultimately need to interact with the ASIC through Syncd and SAI, this part becomes common to all those workflows. Therefore, before diving into other workflows, let's take a look at how Syncd and SAI work first.
Syncd Startup Flow
The entry point of the syncd process is the syncd_main function in syncd_main.cpp. The startup flow can be roughly divided into two parts.
The first part creates and initializes various objects:
sequenceDiagram
autonumber
participant SDM as syncd_main
participant SD as Syncd
participant SAI as VendorSai
SDM->>+SD: Call constructor
SD->>SD: Load and parse command line<br/>arguments and config files
SD->>SD: Create database objects, e.g.:<br/>ASIC_DB Connector and FlexCounterManager
SD->>SD: Create MDIO IPC server
SD->>SD: Create SAI event reporting logic
SD->>SD: Create RedisSelectableChannel<br/>to receive Redis notifications
SD->>-SAI: Initialize SAI
The second part starts the main loop and handles initialization events:
sequenceDiagram
autonumber
box purple Main Thread
participant SDM as syncd_main
participant SD as Syncd
participant SAI as VendorSai
end
box darkblue Notification Handler Thread
participant NP as NotificationProcessor
end
box darkgreen MDIO IPC Server Thread
participant MIS as MdioIpcServer
end
SDM->>+SD: Start main thread loop
SD->>NP: Start SAI event reporting thread
NP->>NP: Begin notification processing loop
SD->>MIS: Start MDIO IPC server thread
MIS->>MIS: Begin MDIO IPC server event loop
SD->>SD: Initialize and start event dispatching,<br/>then begin main loop
loop Process events
alt If it's the create-Switch event or WarmBoot
SD->>SAI: Create Switch object, set notification callbacks
else If it's other events
SD->>SD: Handle events
end
end
SD->>-SDM: Exit main loop and return
Now, let's dive into the code to see how Syncd and SAI are implemented.
The syncd_main Function
The syncd_main function itself is straightforward: it creates a Syncd object and then calls its run method:
// File: src/sonic-sairedis/syncd/syncd_main.cpp
int syncd_main(int argc, char **argv)
{
auto vendorSai = std::make_shared<VendorSai>();
auto syncd = std::make_shared<Syncd>(vendorSai, commandLineOptions, isWarmStart);
syncd->run();
return EXIT_SUCCESS;
}
The Syncd constructor initializes each feature in Syncd, while the run method starts the Syncd main loop.
The Syncd Constructor
The Syncd constructor creates or initializes the key components in Syncd, such as database connection objects, statistics management, and ASIC notification handler. The key code looks like below:
// File: src/sonic-sairedis/syncd/Syncd.cpp
Syncd::Syncd(
_In_ std::shared_ptr<sairedis::SaiInterface> vendorSai,
_In_ std::shared_ptr<CommandLineOptions> cmd,
_In_ bool isWarmStart):
m_vendorSai(vendorSai),
...
{
...
// Load context config
auto ccc = sairedis::ContextConfigContainer::loadFromFile(m_commandLineOptions->m_contextConfig.c_str());
m_contextConfig = ccc->get(m_commandLineOptions->m_globalContext);
...
// Create FlexCounter manager
m_manager = std::make_shared<FlexCounterManager>(m_vendorSai, m_contextConfig->m_dbCounters);
// Create DB related objects
m_dbAsic = std::make_shared<swss::DBConnector>(m_contextConfig->m_dbAsic, 0);
m_mdioIpcServer = std::make_shared<MdioIpcServer>(m_vendorSai, m_commandLineOptions->m_globalContext);
m_selectableChannel = std::make_shared<sairedis::RedisSelectableChannel>(m_dbAsic, ASIC_STATE_TABLE, REDIS_TABLE_GETRESPONSE, TEMP_PREFIX, modifyRedis);
// Create notification processor and handler
m_notifications = std::make_shared<RedisNotificationProducer>(m_contextConfig->m_dbAsic);
m_client = std::make_shared<RedisClient>(m_dbAsic);
m_processor = std::make_shared<NotificationProcessor>(m_notifications, m_client, std::bind(&Syncd::syncProcessNotification, this, _1));
m_handler = std::make_shared<NotificationHandler>(m_processor);
m_sn.onFdbEvent = std::bind(&NotificationHandler::onFdbEvent, m_handler.get(), _1, _2);
m_sn.onNatEvent = std::bind(&NotificationHandler::onNatEvent, m_handler.get(), _1, _2);
// Init many other event handlers here
m_handler->setSwitchNotifications(m_sn.getSwitchNotifications());
...
// Initialize SAI
sai_status_t status = vendorSai->initialize(0, &m_test_services);
...
}
SAI Initialization and VendorSai
The last and most important step in Syncd initialization is to initialize SAI. In the core component introduction to SAI, we briefly described how SAI is initialized and implemented, and how it provides support for different platforms in SONiC. And here, we will focus more on how Syncd wraps SAI and uses it.
Syncd uses VendorSai to wrap all SAI APIs to simplify upper-level calls. The initialization looks like below, essentially just calling the sai initialize and api query functions, and handling errors:
// File: src/sonic-sairedis/syncd/VendorSai.cpp
sai_status_t VendorSai::initialize(
_In_ uint64_t flags,
_In_ const sai_service_method_table_t *service_method_table)
{
...
// Initialize SAI
memcpy(&m_service_method_table, service_method_table, sizeof(m_service_method_table));
auto status = sai_api_initialize(flags, service_method_table);
// If SAI is initialized successfully, query all SAI API methods.
// sai_metadata_api_query will also update all extern global sai_*_api variables, so we can also use
// sai_metadata_get_object_type_info to get methods for a specific SAI object type.
if (status == SAI_STATUS_SUCCESS) {
memset(&m_apis, 0, sizeof(m_apis));
int failed = sai_metadata_apis_query(sai_api_query, &m_apis);
...
}
...
return status;
}
Once all the SAI APIs have been acquired, we can call into the SAI implementation using the VendorSai object.
Currently, VendorSai internally has two different ways to call the SAI APIs:
-
Using
sai_object_type_info_tfrom SAI metadata, which essentially acts like a virtual table for all SAI Objects:// File: src/sonic-sairedis/syncd/VendorSai.cpp sai_status_t VendorSai::set( _In_ sai_object_type_t objectType, _In_ sai_object_id_t objectId, _In_ const sai_attribute_t *attr) { ... auto info = sai_metadata_get_object_type_info(objectType); sai_object_meta_key_t mk = { .objecttype = objectType, .objectkey = { .key = { .object_id = objectId } } }; return info->set(&mk, attr); } -
Using
m_apisstored in theVendorSaiobject. This approach needs us to check the object type and then call the corresponding APIs, so the code becomes more verbose:sai_status_t VendorSai::getStatsExt( _In_ sai_object_type_t object_type, _In_ sai_object_id_t object_id, _In_ uint32_t number_of_counters, _In_ const sai_stat_id_t *counter_ids, _In_ sai_stats_mode_t mode, _Out_ uint64_t *counters) { sai_status_t (*ptr)( _In_ sai_object_id_t port_id, _In_ uint32_t number_of_counters, _In_ const sai_stat_id_t *counter_ids, _In_ sai_stats_mode_t mode, _Out_ uint64_t *counters); switch ((int)object_type) { case SAI_OBJECT_TYPE_PORT: ptr = m_apis.port_api->get_port_stats_ext; break; case SAI_OBJECT_TYPE_ROUTER_INTERFACE: ptr = m_apis.router_interface_api->get_router_interface_stats_ext; break; case SAI_OBJECT_TYPE_POLICER: ptr = m_apis.policer_api->get_policer_stats_ext; break; ... default: SWSS_LOG_ERROR("not implemented, FIXME"); return SAI_STATUS_FAILURE; } return ptr(object_id, number_of_counters, counter_ids, mode, counters); }
The first approach is more succinct.
Main Event Loop
Syncd's main event loop follows SONiC's standard event dispatching pattern. On startup, Syncd registers all Selectable objects handling events with a Select object that waits for events. The main loop calls "select" to wait for events:
// File: src/sonic-sairedis/syncd/Syncd.cpp
void Syncd::run()
{
volatile bool runMainLoop = true;
std::shared_ptr<swss::Select> s = std::make_shared<swss::Select>();
onSyncdStart(m_commandLineOptions->m_startType == SAI_START_TYPE_WARM_BOOT);
// Start notification processing thread
m_processor->startNotificationsProcessingThread();
// Start MDIO threads
for (auto& sw: m_switches) { m_mdioIpcServer->setSwitchId(sw.second->getRid()); }
m_mdioIpcServer->startMdioThread();
// Registering selectable for event polling
s->addSelectable(m_selectableChannel.get());
s->addSelectable(m_restartQuery.get());
s->addSelectable(m_flexCounter.get());
s->addSelectable(m_flexCounterGroup.get());
// Main event loop
while (runMainLoop)
{
swss::Selectable *sel = NULL;
int result = s->select(&sel);
...
if (sel == m_restartQuery.get()) {
// Handling switch restart event and restart switch here.
} else if (sel == m_flexCounter.get()) {
processFlexCounterEvent(*(swss::ConsumerTable*)sel);
} else if (sel == m_flexCounterGroup.get()) {
processFlexCounterGroupEvent(*(swss::ConsumerTable*)sel);
} else if (sel == m_selectableChannel.get()) {
// Handle redis updates here.
processEvent(*m_selectableChannel.get());
} else {
SWSS_LOG_ERROR("select failed: %d", result);
}
...
}
...
}
Here, m_selectableChannel handles Redis database events. It interacts with Redis ProducerTable / ConsumerTable. Hence, all operations from orchagent will be stored in Redis lists, waiting for Syncd to consume.
// File: src/sonic-sairedis/meta/RedisSelectableChannel.h
class RedisSelectableChannel: public SelectableChannel
{
public:
RedisSelectableChannel(
_In_ std::shared_ptr<swss::DBConnector> dbAsic,
_In_ const std::string& asicStateTable,
_In_ const std::string& getResponseTable,
_In_ const std::string& tempPrefix,
_In_ bool modifyRedis);
public: // SelectableChannel overrides
virtual bool empty() override;
...
public: // Selectable overrides
virtual int getFd() override;
virtual uint64_t readData() override;
...
private:
std::shared_ptr<swss::DBConnector> m_dbAsic;
std::shared_ptr<swss::ConsumerTable> m_asicState;
std::shared_ptr<swss::ProducerTable> m_getResponse;
...
};
During the main loop startup, Syncd also launches two threads:
- A notification processing thread for receiving ASIC-reported notifications:
m_processor->startNotificationsProcessingThread() - A thread for handling MDIO communication:
m_mdioIpcServer->startMdioThread()
We'll discuss their details more thoroughly when introducing related workflows.
Initialize SAI Switch and Notifications
Once the main event loop is started, Syncd will call into SAI to create the Switch object. There are two main entry points: either a create switch request from ASIC_DB (called by swss) or Syncd directlly calls it for the Warm Boot process. Either way, the internal flow is similar.
A crucial step here is initializing the notification callbacks in the SAI implementation, such as FDB events. These callback functions are passed to SAI as Switch attributes in create_switch. The SAI implementation stores them so it can call back into Syncd whenever these events occur:
// File: src/sonic-sairedis/syncd/Syncd.cpp
sai_status_t Syncd::processQuadEvent(
_In_ sai_common_api_t api,
_In_ const swss::KeyOpFieldsValuesTuple &kco)
{
// Parse event into SAI object
sai_object_meta_key_t metaKey;
...
SaiAttributeList list(metaKey.objecttype, values, false);
sai_attribute_t *attr_list = list.get_attr_list();
uint32_t attr_count = list.get_attr_count();
// Update notifications pointers in attribute list
if (metaKey.objecttype == SAI_OBJECT_TYPE_SWITCH && (api == SAI_COMMON_API_CREATE || api == SAI_COMMON_API_SET))
{
m_handler->updateNotificationsPointers(attr_count, attr_list);
}
if (isInitViewMode())
{
// ProcessQuadEventInInitViewMode will eventually call into VendorSai, which calls create_swtich function in SAI.
sai_status_t status = processQuadEventInInitViewMode(metaKey.objecttype, strObjectId, api, attr_count, attr_list);
syncUpdateRedisQuadEvent(status, api, kco);
return status;
}
...
}
// File: src/sonic-sairedis/syncd/NotificationHandler.cpp
void NotificationHandler::updateNotificationsPointers(_In_ uint32_t attr_count, _In_ sai_attribute_t *attr_list) const
{
for (uint32_t index = 0; index < attr_count; ++index) {
...
sai_attribute_t &attr = attr_list[index];
switch (attr.id) {
...
case SAI_SWITCH_ATTR_SHUTDOWN_REQUEST_NOTIFY:
attr.value.ptr = (void*)m_switchNotifications.on_switch_shutdown_request;
break;
case SAI_SWITCH_ATTR_FDB_EVENT_NOTIFY:
attr.value.ptr = (void*)m_switchNotifications.on_fdb_event;
break;
...
}
...
}
}
// File: src/sonic-sairedis/syncd/Syncd.cpp
// Call stack: processQuadEvent
// -> processQuadEventInInitViewMode
// -> processQuadInInitViewModeCreate
// -> onSwitchCreateInInitViewMode
void Syncd::onSwitchCreateInInitViewMode(_In_ sai_object_id_t switchVid, _In_ uint32_t attr_count, _In_ const sai_attribute_t *attr_list)
{
if (m_switches.find(switchVid) == m_switches.end()) {
sai_object_id_t switchRid;
sai_status_t status;
status = m_vendorSai->create(SAI_OBJECT_TYPE_SWITCH, &switchRid, 0, attr_count, attr_list);
...
m_switches[switchVid] = std::make_shared<SaiSwitch>(switchVid, switchRid, m_client, m_translator, m_vendorSai);
m_mdioIpcServer->setSwitchId(switchRid);
...
}
...
}
From the open-sourced Mellanox's implementation, we can see how the SAI switch is created and the notification callbacks are set:
// File: https://github.com/Mellanox/SAI-Implementation/blob/master/mlnx_sai/src/mlnx_sai_switch.c
static sai_status_t mlnx_create_switch(_Out_ sai_object_id_t * switch_id,
_In_ uint32_t attr_count,
_In_ const sai_attribute_t *attr_list)
{
...
status = find_attrib_in_list(attr_count, attr_list, SAI_SWITCH_ATTR_SWITCH_STATE_CHANGE_NOTIFY, &attr_val, &attr_idx);
if (!SAI_ERR(status)) {
g_notification_callbacks.on_switch_state_change = (sai_switch_state_change_notification_fn)attr_val->ptr;
}
status = find_attrib_in_list(attr_count, attr_list, SAI_SWITCH_ATTR_SHUTDOWN_REQUEST_NOTIFY, &attr_val, &attr_idx);
if (!SAI_ERR(status)) {
g_notification_callbacks.on_switch_shutdown_request =
(sai_switch_shutdown_request_notification_fn)attr_val->ptr;
}
status = find_attrib_in_list(attr_count, attr_list, SAI_SWITCH_ATTR_FDB_EVENT_NOTIFY, &attr_val, &attr_idx);
if (!SAI_ERR(status)) {
g_notification_callbacks.on_fdb_event = (sai_fdb_event_notification_fn)attr_val->ptr;
}
status = find_attrib_in_list(attr_count, attr_list, SAI_SWITCH_ATTR_PORT_STATE_CHANGE_NOTIFY, &attr_val, &attr_idx);
if (!SAI_ERR(status)) {
g_notification_callbacks.on_port_state_change = (sai_port_state_change_notification_fn)attr_val->ptr;
}
status = find_attrib_in_list(attr_count, attr_list, SAI_SWITCH_ATTR_PACKET_EVENT_NOTIFY, &attr_val, &attr_idx);
if (!SAI_ERR(status)) {
g_notification_callbacks.on_packet_event = (sai_packet_event_notification_fn)attr_val->ptr;
}
...
}
ASIC Programming Workflow
ASIC programming workflow is the most important workflow in Syncd. When orchagent discovers any configuration changes, it sends ASIC programming request via ASIC_DB, which triggers this workflow and uses SAI to update the ASIC. After understanding Syncd's main event loop and the communication channels, the workflow will become easier to follow.
All steps happen sequentially on the main thread:
sequenceDiagram
autonumber
participant SD as Syncd
participant RSC as RedisSelectableChannel
participant SAI as VendorSai
participant R as Redis
loop Main thread loop
SD->>RSC: epoll notifies arrival of new messages
RSC->>R: Fetch all new messages from ConsumerTable
critical Lock Syncd
loop For each message
SD->>RSC: Get the message
SD->>SD: Parse message, get operation type and object
SD->>SAI: Call the corresponding SAI API to update the ASIC
SD->>RSC: Send the operation result to Redis
RSC->>R: Write the result into Redis
end
end
end
First, orchagent sends operations through Redis, which will be received by the RedisSelectableChannel. When the main event loop processes m_selectableChannel, it calls processEvent to process it, just like what we have discussed in the main event loop section.
Then, processEvent calls the relevant SAI API to update the ASIC. The logic is a giant switch-case statement that dispatches the operations:
// File: src/sonic-sairedis/syncd/Syncd.cpp
void Syncd::processEvent(_In_ sairedis::SelectableChannel& consumer)
{
// Loop all operations in the queue
std::lock_guard<std::mutex> lock(m_mutex);
do {
swss::KeyOpFieldsValuesTuple kco;
consumer.pop(kco, isInitViewMode());
processSingleEvent(kco);
} while (!consumer.empty());
}
sai_status_t Syncd::processSingleEvent(_In_ const swss::KeyOpFieldsValuesTuple &kco)
{
auto& op = kfvOp(kco);
...
if (op == REDIS_ASIC_STATE_COMMAND_CREATE)
return processQuadEvent(SAI_COMMON_API_CREATE, kco);
if (op == REDIS_ASIC_STATE_COMMAND_REMOVE)
return processQuadEvent(SAI_COMMON_API_REMOVE, kco);
...
}
sai_status_t Syncd::processQuadEvent(
_In_ sai_common_api_t api,
_In_ const swss::KeyOpFieldsValuesTuple &kco)
{
// Parse operation
const std::string& key = kfvKey(kco);
const std::string& strObjectId = key.substr(key.find(":") + 1);
sai_object_meta_key_t metaKey;
sai_deserialize_object_meta_key(key, metaKey);
auto& values = kfvFieldsValues(kco);
SaiAttributeList list(metaKey.objecttype, values, false);
sai_attribute_t *attr_list = list.get_attr_list();
uint32_t attr_count = list.get_attr_count();
...
auto info = sai_metadata_get_object_type_info(metaKey.objecttype);
// Process the operation
sai_status_t status;
if (info->isnonobjectid) {
status = processEntry(metaKey, api, attr_count, attr_list);
} else {
status = processOid(metaKey.objecttype, strObjectId, api, attr_count, attr_list);
}
// Send response
if (api == SAI_COMMON_API_GET) {
sai_object_id_t switchVid = VidManager::switchIdQuery(metaKey.objectkey.key.object_id);
sendGetResponse(metaKey.objecttype, strObjectId, switchVid, status, attr_count, attr_list);
...
} else {
sendApiResponse(api, status);
}
syncUpdateRedisQuadEvent(status, api, kco);
return status;
}
sai_status_t Syncd::processEntry(_In_ sai_object_meta_key_t metaKey, _In_ sai_common_api_t api,
_In_ uint32_t attr_count, _In_ sai_attribute_t *attr_list)
{
...
switch (api)
{
case SAI_COMMON_API_CREATE:
return m_vendorSai->create(metaKey, SAI_NULL_OBJECT_ID, attr_count, attr_list);
case SAI_COMMON_API_REMOVE:
return m_vendorSai->remove(metaKey);
...
default:
SWSS_LOG_THROW("api %s not supported", sai_serialize_common_api(api).c_str());
}
}
ASIC State Change Notification Workflow
On the other hand, when the ASIC state is changed or needs to report certain status, it notifies us through SAI. Syncd listens for these notifications, then reports them back to orchagent through our communication channel on top of ASIC_DB.
The workflow shows as below:
sequenceDiagram
box purple SAI Implementation Event Thread
participant SAI as SAI Impl
end
box darkblue Notification Processing Thread
participant NP as NotificationProcessor
participant SD as Syncd
participant RNP as RedisNotificationProducer
participant R as Redis
end
loop SAI Implementation Event Loop
SAI->>SAI: Get events from ASIC SDK
SAI->>SAI: Parse events, convert to SAI notifications
SAI->>NP: Serialize notifications<br/>and add to the notification thread queue
end
loop Notification Thread Loop
NP->>NP: Fetch notification from queue
NP->>SD: Acquire Syncd lock
critical Lock Syncd
NP->>NP: Deserialize notification, handle it
NP->>RNP: Re-serialize notification and send to Redis
RNP->>R: Write the notification to ASIC_DB via NotificationProducer
end
end
Here, let's look into a real implementation. For better understanding, we still use Mellanox's open-sourced SAI implementation as an example.
First of all, SAI implementation needs to be able to receive notification from ASIC. This is done by calling into the ASIC SDK. In Mellanox's SAI, it sets up an event thread to hook into ASIC, then use select to handle the events from ASIC SDK:
// File: https://github.com/Mellanox/SAI-Implementation/blob/master/mlnx_sai/src/mlnx_sai_switch.c
static void event_thread_func(void *context)
{
#define MAX_PACKET_SIZE MAX(g_resource_limits.port_mtu_max, SX_HOST_EVENT_BUFFER_SIZE_MAX)
sx_status_t status;
sx_api_handle_t api_handle;
sx_user_channel_t port_channel, callback_channel;
fd_set descr_set;
int ret_val;
sai_object_id_t switch_id = (sai_object_id_t)context;
sai_port_oper_status_notification_t port_data;
sai_fdb_event_notification_data_t *fdb_events = NULL;
sai_attribute_t *attr_list = NULL;
...
// Init SDK API
if (SX_STATUS_SUCCESS != (status = sx_api_open(sai_log_cb, &api_handle))) {
if (g_notification_callbacks.on_switch_shutdown_request) {
g_notification_callbacks.on_switch_shutdown_request(switch_id);
}
return;
}
if (SX_STATUS_SUCCESS != (status = sx_api_host_ifc_open(api_handle, &port_channel.channel.fd))) {
goto out;
}
...
// Register for port and channel notifications
port_channel.type = SX_USER_CHANNEL_TYPE_FD;
if (SX_STATUS_SUCCESS != (status = sx_api_host_ifc_trap_id_register_set(api_handle, SX_ACCESS_CMD_REGISTER, DEFAULT_ETH_SWID, SX_TRAP_ID_PUDE, &port_channel))) {
goto out;
}
...
for (uint32_t ii = 0; ii < (sizeof(mlnx_trap_ids) / sizeof(*mlnx_trap_ids)); ii++) {
status = sx_api_host_ifc_trap_id_register_set(api_handle, SX_ACCESS_CMD_REGISTER, DEFAULT_ETH_SWID, mlnx_trap_ids[ii], &callback_channel);
}
while (!event_thread_asked_to_stop) {
FD_ZERO(&descr_set);
FD_SET(port_channel.channel.fd.fd, &descr_set);
FD_SET(callback_channel.channel.fd.fd, &descr_set);
...
ret_val = select(FD_SETSIZE, &descr_set, NULL, NULL, &timeout);
if (ret_val > 0) {
// Port state change event
if (FD_ISSET(port_channel.channel.fd.fd, &descr_set)) {
// Parse port state event here ...
if (g_notification_callbacks.on_port_state_change) {
g_notification_callbacks.on_port_state_change(1, &port_data);
}
}
if (FD_ISSET(callback_channel.channel.fd.fd, &descr_set)) {
// Receive notification event.
packet_size = MAX_PACKET_SIZE;
if (SX_STATUS_SUCCESS != (status = sx_lib_host_ifc_recv(&callback_channel.channel.fd, p_packet, &packet_size, receive_info))) {
goto out;
}
// BFD packet event
if (SX_TRAP_ID_BFD_PACKET_EVENT == receive_info->trap_id) {
const struct bfd_packet_event *event = (const struct bfd_packet_event*)p_packet;
// Parse and check event valid here ...
status = mlnx_switch_bfd_packet_handle(event);
continue;
}
// Same way to handle BFD timeout event, Bulk counter ready event. Emiited.
// FDB event and packet event handling
if (receive_info->trap_id == SX_TRAP_ID_FDB_EVENT) {
trap_name = "FDB event";
} else if (SAI_STATUS_SUCCESS != (status = mlnx_translate_sdk_trap_to_sai(receive_info->trap_id, &trap_name, &trap_oid))) {
continue;
}
if (SX_TRAP_ID_FDB_EVENT == receive_info->trap_id) {
// Parse FDB events here ...
if (g_notification_callbacks.on_fdb_event) {
g_notification_callbacks.on_fdb_event(event_count, fdb_events);
}
continue;
}
// Packet event handling
status = mlnx_get_hostif_packet_data(receive_info, &attrs_num, callback_data);
if (g_notification_callbacks.on_packet_event) {
g_notification_callbacks.on_packet_event(switch_id, packet_size, p_packet, attrs_num, callback_data);
}
}
}
}
out:
...
}
Using FDB event as an example:
- When ASIC sends the FDB events, it will be received by the event loop above.
- The callback
g_notification_callbacks.on_fdb_eventstored in SAI implementation will be called to handle this event. - It then calls
NotificationHandler::onFdbEventin Syncd to serialize the event and put it into the notification queue:
// File: src/sonic-sairedis/syncd/NotificationHandler.cpp
void NotificationHandler::onFdbEvent(_In_ uint32_t count, _In_ const sai_fdb_event_notification_data_t *data)
{
std::string s = sai_serialize_fdb_event_ntf(count, data);
enqueueNotification(SAI_SWITCH_NOTIFICATION_NAME_FDB_EVENT, s);
}
Then the notification thread is signaled to pick up this event from the queue, then process it under the syncd lock:
// File: src/sonic-sairedis/syncd/NotificationProcessor.cpp
void NotificationProcessor::ntf_process_function()
{
std::mutex ntf_mutex;
std::unique_lock<std::mutex> ulock(ntf_mutex);
while (m_runThread) {
// When notification arrives, it will signal this condition variable.
m_cv.wait(ulock);
// Process notifications in the queue.
swss::KeyOpFieldsValuesTuple item;
while (m_notificationQueue->tryDequeue(item)) {
processNotification(item);
}
}
}
// File: src/sonic-sairedis/syncd/Syncd.cpp
// Call from NotificationProcessor::processNotification
void Syncd::syncProcessNotification(_In_ const swss::KeyOpFieldsValuesTuple& item)
{
std::lock_guard<std::mutex> lock(m_mutex);
m_processor->syncProcessNotification(item);
}
Now, it goes into the event dispatching and handling logic. syncProcessNotification function is essentially a series of if-else statements, which calls the corresponding handling function based on the event type:
// File: src/sonic-sairedis/syncd/NotificationProcessor.cpp
void NotificationProcessor::syncProcessNotification( _In_ const swss::KeyOpFieldsValuesTuple& item)
{
std::string notification = kfvKey(item);
std::string data = kfvOp(item);
if (notification == SAI_SWITCH_NOTIFICATION_NAME_SWITCH_STATE_CHANGE) {
handle_switch_state_change(data);
} else if (notification == SAI_SWITCH_NOTIFICATION_NAME_FDB_EVENT) {
handle_fdb_event(data);
} else if ...
} else {
SWSS_LOG_ERROR("unknown notification: %s", notification.c_str());
}
}
For each event, the handling function deserializes the event and processes it, such as handle_fdb_event and process_on_fdb_event:
// File: src/sonic-sairedis/syncd/NotificationProcessor.cpp
void NotificationProcessor::handle_fdb_event(_In_ const std::string &data)
{
uint32_t count;
sai_fdb_event_notification_data_t *fdbevent = NULL;
sai_deserialize_fdb_event_ntf(data, count, &fdbevent);
process_on_fdb_event(count, fdbevent);
sai_deserialize_free_fdb_event_ntf(count, fdbevent);
}
void NotificationProcessor::process_on_fdb_event( _In_ uint32_t count, _In_ sai_fdb_event_notification_data_t *data)
{
for (uint32_t i = 0; i < count; i++) {
sai_fdb_event_notification_data_t *fdb = &data[i];
// Check FDB event notification data here
fdb->fdb_entry.switch_id = m_translator->translateRidToVid(fdb->fdb_entry.switch_id, SAI_NULL_OBJECT_ID);
fdb->fdb_entry.bv_id = m_translator->translateRidToVid(fdb->fdb_entry.bv_id, fdb->fdb_entry.switch_id, true);
m_translator->translateRidToVid(SAI_OBJECT_TYPE_FDB_ENTRY, fdb->fdb_entry.switch_id, fdb->attr_count, fdb->attr, true);
...
}
// Send notification
std::string s = sai_serialize_fdb_event_ntf(count, data);
sendNotification(SAI_SWITCH_NOTIFICATION_NAME_FDB_EVENT, s);
}
Finally, it's written to ASIC_DB via NotificationProducer to notify orchagent:
// File: src/sonic-sairedis/syncd/NotificationProcessor.cpp
void NotificationProcessor::sendNotification(_In_ const std::string& op, _In_ const std::string& data)
{
std::vector<swss::FieldValueTuple> entry;
sendNotification(op, data, entry);
}
void NotificationProcessor::sendNotification(_In_ const std::string& op, _In_ const std::string& data, _In_ std::vector<swss::FieldValueTuple> entry)
{
m_notifications->send(op, data, entry);
}
// File: src/sonic-sairedis/syncd/RedisNotificationProducer.cpp
void RedisNotificationProducer::send(_In_ const std::string& op, _In_ const std::string& data, _In_ const std::vector<swss::FieldValueTuple>& values)
{
std::vector<swss::FieldValueTuple> vals = values;
// The m_notificationProducer is created in the ctor of RedisNotificationProducer as below:
// m_notificationProducer = std::make_shared<swss::NotificationProducer>(m_db.get(), REDIS_TABLE_NOTIFICATIONS_PER_DB(dbName));
m_notificationProducer->send(op, data, vals);
}
That's it! This is basically how things work in high level in Syncd!
References
BGP
BGP might be the most commonly used and important feature in switches. In this section, we take a deeper look at BGP-related workflows.
BGP Processes
SONiC uses FRRouting as its BGP implementation, responsible for handling the BGP protocol. FRRouting is an open-source routing software that supports multiple routing protocols, including BGP, OSPF, IS-IS, RIP, PIM, LDP, etc. When a new version of FRR is released, SONiC synchronizes it to the SONiC FRR repository: sonic-frr, with each version corresponding to a branch such as frr/8.2.
FRR mainly consists of two major parts. The first part includes the implementations of each protocol, where processes are named *d. When they receive routing update notifications, they inform the second part, the "zebra" process. The zebra process performs route selection and synchronizes the best routing information to the kernel. Its main structure is shown below:
+----+ +----+ +-----+ +----+ +----+ +----+ +-----+
|bgpd| |ripd| |ospfd| |ldpd| |pbrd| |pimd| |.....|
+----+ +----+ +-----+ +----+ +----+ +----+ +-----+
| | | | | | |
+----v-------v--------v-------v-------v-------v--------v
| |
| Zebra |
| |
+------------------------------------------------------+
| | |
| | |
+------v------+ +---------v--------+ +------v------+
| | | | | |
| *NIX Kernel | | Remote dataplane | | ........... |
| | | | | |
+-------------+ +------------------+ +-------------+
In SONiC, these FRR processes all run inside the bgp container. In addition, to integrate FRR with Redis, SONiC runs a process called fpmsyncd (Forwarding Plane Manager syncd) within the bgp container. Its main function is to listen to kernel routing updates and synchronize them to the APPL_DB. Because it is not part of FRR, its implementation is located in the sonic-swss repository.
References
- SONiC Architecture
- Github repo: sonic-swss
- Github repo: sonic-frr
- RFC 4271: A Border Gateway Protocol 4 (BGP-4)
- FRRouting
BGP CLI and vtysh
show Command
Since BGP is implemented using FRR, naturally, the show command will forward the direct request to FRR's vtysh. The key code is as follows:
# file: src/sonic-utilities/show/bgp_frr_v4.py
# 'summary' subcommand ("show ip bgp summary")
@bgp.command()
@multi_asic_util.multi_asic_click_options
def summary(namespace, display):
bgp_summary = bgp_util.get_bgp_summary_from_all_bgp_instances(
constants.IPV4, namespace, display)
bgp_util.display_bgp_summary(bgp_summary=bgp_summary, af=constants.IPV4)
# file: src/sonic-utilities/utilities_common/bgp_util.py
def get_bgp_summary_from_all_bgp_instances(af, namespace, display):
# The IPv6 case is omitted here for simplicity
vtysh_cmd = "show ip bgp summary json"
for ns in device.get_ns_list_based_on_options():
cmd_output = run_bgp_show_command(vtysh_cmd, ns)
def run_bgp_command(vtysh_cmd, bgp_namespace=multi_asic.DEFAULT_NAMESPACE, vtysh_shell_cmd=constants.VTYSH_COMMAND):
cmd = ['sudo', vtysh_shell_cmd] + bgp_instance_id + ['-c', vtysh_cmd]
output, ret = clicommon.run_command(cmd, return_cmd=True)
We can also verify by running vtysh directly:
root@7260cx3:/etc/sonic/frr# which vtysh
/usr/bin/vtysh
root@7260cx3:/etc/sonic/frr# vtysh
Hello, this is FRRouting (version 7.5.1-sonic).
Copyright 1996-2005 Kunihiro Ishiguro, et al.
7260cx3# show ip bgp summary
IPv4 Unicast Summary:
BGP router identifier 10.1.0.32, local AS number 65100 vrf-id 0
BGP table version 6410
RIB entries 12809, using 2402 KiB of memory
Peers 4, using 85 KiB of memory
Peer groups 4, using 256 bytes of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt
10.0.0.57 4 64600 3702 3704 0 0 0 08:15:03 6401 6406
10.0.0.59 4 64600 3702 3704 0 0 0 08:15:03 6401 6406
10.0.0.61 4 64600 3705 3702 0 0 0 08:15:03 6401 6406
10.0.0.63 4 64600 3702 3702 0 0 0 08:15:03 6401 6406
Total number of neighbors 4
config Command
Meanwhile, the config command directly operates on CONFIG_DB to achieve configuration changes.
Take remove neighbor as an example. The key code is shown as follows:
# file: src/sonic-utilities/config/main.py
@bgp.group(cls=clicommon.AbbreviationGroup)
def remove():
"Remove BGP neighbor configuration from the device"
pass
@remove.command('neighbor')
@click.argument('neighbor_ip_or_hostname', metavar='<neighbor_ip_or_hostname>', required=True)
def remove_neighbor(neighbor_ip_or_hostname):
"""Removes BGP neighbor configuration (internal or external) from the device"""
namespaces = [DEFAULT_NAMESPACE]
removed_neighbor = False
// ...existing code...
for namespace in namespaces:
config_db = ConfigDBConnector(use_unix_socket_path=True, namespace=namespace)
config_db.connect()
if _remove_bgp_neighbor_config(config_db, neighbor_ip_or_hostname):
removed_neighbor = True
// ...existing code...
References
- SONiC Architecture
- Github repo: sonic-frr
- Github repo: sonic-utilities
- RFC 4271: A Border Gateway Protocol 4 (BGP-4)
- FRRouting
Route Update in FRR
Route update is almost the most important workflow in SONiC. The entire process starts from the bgpd process and eventually reaches the ASIC chip through SAI. Many processes are involved in between, and the workflow is quite complex. However, once we understand it, we can understand the design of SONiC and many other configuration workflows much better. Therefore, in this section, we will deeply dive into its overall process.
To help us understand the workflow on the code level, we divide this workflow into two major parts: how FRR handles route changes in this chapter, and how the SONiC updates the routes and integrates with FRR in the next chapter.
FRR Handling Route Changes
sequenceDiagram
autonumber
participant N as Neighbor Node
box purple BGP Container
participant B as bgpd
participant ZH as zebra<br/> (Request Handling Thread)
participant ZF as zebra<br/> (Route Handling Thread)
participant ZD as zebra<br/> (Data Plane Handling Thread)
participant ZFPM as zebra<br/> (FPM Forward Thread)
participant FPM as fpmsyncd
end
participant K as Linux Kernel
N->>B: Establish BGP session,<br/>send route update
B->>B: Route selection, update local routing table (RIB)
alt If route changes
B->>N: Notify other neighbor nodes of route change
end
B->>ZH: Notify Zebra to update routing table<br/>through zlient local Socket
ZH->>ZH: Receive request from bgpd
ZH->>ZF: Put route request into<br/>route handling thread's queue
ZF->>ZF: Update local routing table (RIB)
ZF->>ZD: Put route table update request into<br/>data plane handling thread's<br/>message queue
ZF->>ZFPM: Request FPM handling thread to forward route update
ZFPM->>FPM: Notify fpmsyncd to<br/>issue route update<br/>through FPM protocol
ZD->>K: Send Netlink message to update kernel routing table
Regarding the implementation of FRR, this section focuses more on explaining its workflow from the code perspective rather than the details of its BGP implementation. If you want to learn about the details of FRR's BGP implementation, you can refer to the official documentation.
bgpd Handling Route Changes
bgpd is the process in FRR specifically used to handle BGP sessions. It opens TCP port 179 to establish BGP connections with neighbors and handles routing table update requests. When a route changes, FRR also uses this session to notify other neighbors.
When a request arrives at bgpd, it will land on the io thread first: bgp_io. As the name suggests, this thread is responsible for network read and write operations in bgpd:
// File: src/sonic-frr/frr/bgpd/bgp_io.c
static int bgp_process_reads(struct thread *thread)
{
...
while (more) {
// Read packets here
...
// If we have more than 1 complete packet, mark it and process it later.
if (ringbuf_remain(ibw) >= pktsize) {
...
added_pkt = true;
} else break;
}
...
if (added_pkt)
thread_add_event(bm->master, bgp_process_packet, peer, 0, &peer->t_process_packet);
return 0;
}
After the packet is read, bgpd sends it to the main thread for processing. Here, bgpd dispatches the packet based on its type. And the route update requests will be handed over to bpg_update_receive for processing:
// File: src/sonic-frr/frr/bgpd/bgp_packet.c
int bgp_process_packet(struct thread *thread)
{
...
unsigned int processed = 0;
while (processed < rpkt_quanta_old) {
uint8_t type = 0;
bgp_size_t size;
...
/* read in the packet length and type */
size = stream_getw(peer->curr);
type = stream_getc(peer->curr);
size -= BGP_HEADER_SIZE;
switch (type) {
case BGP_MSG_OPEN:
...
break;
case BGP_MSG_UPDATE:
...
mprc = bgp_update_receive(peer, size);
...
break;
...
}
// Process BGP UPDATE message for peer.
static int bgp_update_receive(struct peer *peer, bgp_size_t size)
{
struct stream *s;
struct attr attr;
struct bgp_nlri nlris[NLRI_TYPE_MAX];
...
// Parse attributes and NLRI
memset(&attr, 0, sizeof(struct attr));
attr.label_index = BGP_INVALID_LABEL_INDEX;
attr.label = MPLS_INVALID_LABEL;
...
memset(&nlris, 0, sizeof(nlris));
...
if ((!update_len && !withdraw_len && nlris[NLRI_MP_UPDATE].length == 0)
|| (attr_parse_ret == BGP_ATTR_PARSE_EOR)) {
// More parsing here
...
if (afi && peer->afc[afi][safi]) {
struct vrf *vrf = vrf_lookup_by_id(peer->bgp->vrf_id);
/* End-of-RIB received */
if (!CHECK_FLAG(peer->af_sflags[afi][safi], PEER_STATUS_EOR_RECEIVED)) {
...
if (gr_info->eor_required == gr_info->eor_received) {
...
/* Best path selection */
if (bgp_best_path_select_defer( peer->bgp, afi, safi) < 0)
return BGP_Stop;
}
}
...
}
}
...
return Receive_UPDATE_message;
}
Then, bgpd starts checking for better paths and updates its local routing table (RIB, Routing Information Base):
// File: src/sonic-frr/frr/bgpd/bgp_route.c
/* Process the routes with the flag BGP_NODE_SELECT_DEFER set */
int bgp_best_path_select_defer(struct bgp *bgp, afi_t afi, safi_t safi)
{
struct bgp_dest *dest;
int cnt = 0;
struct afi_safi_info *thread_info;
...
/* Process the route list */
for (dest = bgp_table_top(bgp->rib[afi][safi]);
dest && bgp->gr_info[afi][safi].gr_deferred != 0;
dest = bgp_route_next(dest))
{
...
bgp_process_main_one(bgp, dest, afi, safi);
...
}
...
return 0;
}
static void bgp_process_main_one(struct bgp *bgp, struct bgp_dest *dest, afi_t afi, safi_t safi)
{
struct bgp_path_info *new_select;
struct bgp_path_info *old_select;
struct bgp_path_info_pair old_and_new;
...
const struct prefix *p = bgp_dest_get_prefix(dest);
...
/* Best path selection. */
bgp_best_selection(bgp, dest, &bgp->maxpaths[afi][safi], &old_and_new, afi, safi);
old_select = old_and_new.old;
new_select = old_and_new.new;
...
/* FIB update. */
if (bgp_fibupd_safi(safi) && (bgp->inst_type != BGP_INSTANCE_TYPE_VIEW)
&& !bgp_option_check(BGP_OPT_NO_FIB)) {
if (new_select && new_select->type == ZEBRA_ROUTE_BGP
&& (new_select->sub_type == BGP_ROUTE_NORMAL
|| new_select->sub_type == BGP_ROUTE_AGGREGATE
|| new_select->sub_type == BGP_ROUTE_IMPORTED)) {
...
if (old_select && is_route_parent_evpn(old_select))
bgp_zebra_withdraw(p, old_select, bgp, safi);
bgp_zebra_announce(dest, p, new_select, bgp, afi, safi);
} else {
/* Withdraw the route from the kernel. */
...
}
}
/* EVPN route injection and clean up */
...
UNSET_FLAG(dest->flags, BGP_NODE_PROCESS_SCHEDULED);
return;
}
Finally, bgp_zebra_announce notifies zebra to update the kernel routing table through zclient.
// File: src/sonic-frr/frr/bgpd/bgp_zebra.c
void bgp_zebra_announce(struct bgp_node *rn, struct prefix *p, struct bgp_path_info *info, struct bgp *bgp, afi_t afi, safi_t safi)
{
...
zclient_route_send(valid_nh_count ? ZEBRA_ROUTE_ADD : ZEBRA_ROUTE_DELETE, zclient, &api);
}
zclient communicates with zebra using a local socket and provides a series of callback functions to receive notifications from zebra. The key code is shown as follows:
// File: src/sonic-frr/frr/bgpd/bgp_zebra.c
void bgp_zebra_init(struct thread_master *master, unsigned short instance)
{
zclient_num_connects = 0;
/* Set default values. */
zclient = zclient_new(master, &zclient_options_default);
zclient_init(zclient, ZEBRA_ROUTE_BGP, 0, &bgpd_privs);
zclient->zebra_connected = bgp_zebra_connected;
zclient->router_id_update = bgp_router_id_update;
zclient->interface_add = bgp_interface_add;
zclient->interface_delete = bgp_interface_delete;
zclient->interface_address_add = bgp_interface_address_add;
...
}
int zclient_socket_connect(struct zclient *zclient)
{
int sock;
int ret;
sock = socket(zclient_addr.ss_family, SOCK_STREAM, 0);
...
/* Connect to zebra. */
ret = connect(sock, (struct sockaddr *)&zclient_addr, zclient_addr_len);
...
zclient->sock = sock;
return sock;
}
In the bgpd container, we can find the socket file used for zebra communication in the /run/frr directory for simple verification:
root@7260cx3:/run/frr# ls -l
total 12
...
srwx------ 1 frr frr 0 Jun 16 09:16 zserv.api
zebra Updating Routing Table
Since FRR supports many routing protocols, if each routing protocol updates kernel independently, conflicts will inevitably arise, because it is difficult to coordinate. Therefore, FRR uses a separate process to communicate with all routing protocol handling processes, merges the information, and then update the kernel routing table. This process is zebra.
In zebra, kernel updates occur in a separate data plane handling thread: dplane_thread. All requests are sent to zebra through zclient, then get processed, and finally get forwarded to dplane_thread for handling. In whis way, the route update will always be in order, which avoids any conflicts to happen.
When zebra starts, it registers all request handlers. When a request arrives, the corresponding handler will be called based on the request type. And here is the key code:
// File: src/sonic-frr/frr/zebra/zapi_msg.c
void (*zserv_handlers[])(ZAPI_HANDLER_ARGS) = {
[ZEBRA_ROUTER_ID_ADD] = zread_router_id_add,
[ZEBRA_ROUTER_ID_DELETE] = zread_router_id_delete,
[ZEBRA_INTERFACE_ADD] = zread_interface_add,
[ZEBRA_INTERFACE_DELETE] = zread_interface_delete,
[ZEBRA_ROUTE_ADD] = zread_route_add,
[ZEBRA_ROUTE_DELETE] = zread_route_del,
[ZEBRA_REDISTRIBUTE_ADD] = zebra_redistribute_add,
[ZEBRA_REDISTRIBUTE_DELETE] = zebra_redistribute_delete,
...
Take adding a route (zread_route_add) as an example to explain the later workflow. From the following code, we can see that when a new route arrives, zebra will start checking and updating its internal routing table:
// File: src/sonic-frr/frr/zebra/zapi_msg.c
static void zread_route_add(ZAPI_HANDLER_ARGS)
{
struct stream *s;
struct route_entry *re;
struct nexthop_group *ng = NULL;
struct nhg_hash_entry nhe;
...
// Decode zclient request
s = msg;
if (zapi_route_decode(s, &api) < 0) {
return;
}
...
// Allocate new route entry.
re = XCALLOC(MTYPE_RE, sizeof(struct route_entry));
re->type = api.type;
re->instance = api.instance;
...
// Init nexthop entry, if we have an id, then add route.
if (!re->nhe_id) {
zebra_nhe_init(&nhe, afi, ng->nexthop);
nhe.nhg.nexthop = ng->nexthop;
nhe.backup_info = bnhg;
}
ret = rib_add_multipath_nhe(afi, api.safi, &api.prefix, src_p, re, &nhe);
// Update stats. IPv6 is omitted here for simplicity.
if (ret > 0) client->v4_route_add_cnt++;
else if (ret < 0) client->v4_route_upd8_cnt++;
}
// File: src/sonic-frr/frr/zebra/zebra_rib.c
int rib_add_multipath_nhe(afi_t afi, safi_t safi, struct prefix *p,
struct prefix_ipv6 *src_p, struct route_entry *re,
struct nhg_hash_entry *re_nhe)
{
struct nhg_hash_entry *nhe = NULL;
struct route_table *table;
struct route_node *rn;
int ret = 0;
...
/* Find table and nexthop entry */
table = zebra_vrf_get_table_with_table_id(afi, safi, re->vrf_id, re->table);
if (re->nhe_id > 0) nhe = zebra_nhg_lookup_id(re->nhe_id);
else nhe = zebra_nhg_rib_find_nhe(re_nhe, afi);
/* Attach the re to the nhe's nexthop group. */
route_entry_update_nhe(re, nhe);
/* Make it sure prefixlen is applied to the prefix. */
/* Set default distance by route type. */
...
/* Lookup route node.*/
rn = srcdest_rnode_get(table, p, src_p);
...
/* If this route is kernel/connected route, notify the dataplane to update kernel route table. */
if (RIB_SYSTEM_ROUTE(re)) {
dplane_sys_route_add(rn, re);
}
/* Link new re to node. */
SET_FLAG(re->status, ROUTE_ENTRY_CHANGED);
rib_addnode(rn, re, 1);
/* Clean up */
...
return ret;
}
Here, rib_addnode will forward this route add request to the rib processing thread, where the requests are being processed sequentially:
static void rib_addnode(struct route_node *rn, struct route_entry *re, int process)
{
...
rib_link(rn, re, process);
}
static void rib_link(struct route_node *rn, struct route_entry *re, int process)
{
rib_dest_t *dest = rib_dest_from_rnode(rn);
if (!dest) dest = zebra_rib_create_dest(rn);
re_list_add_head(&dest->routes, re);
...
if (process) rib_queue_add(rn);
}
Then, the request arrives at the RIB processing thread: rib_process, which further selects the best route and adds it to zebra's internal routing table (RIB):
/* Core function for processing routing information base. */
static void rib_process(struct route_node *rn)
{
struct route_entry *re;
struct route_entry *next;
struct route_entry *old_selected = NULL;
struct route_entry *new_selected = NULL;
struct route_entry *old_fib = NULL;
struct route_entry *new_fib = NULL;
struct route_entry *best = NULL;
rib_dest_t *dest;
...
dest = rib_dest_from_rnode(rn);
old_fib = dest->selected_fib;
...
/* Check every route entry and select the best route. */
RNODE_FOREACH_RE_SAFE (rn, re, next) {
...
if (CHECK_FLAG(re->flags, ZEBRA_FLAG_FIB_OVERRIDE)) {
best = rib_choose_best(new_fib, re);
if (new_fib && best != new_fib)
UNSET_FLAG(new_fib->status, ROUTE_ENTRY_CHANGED);
new_fib = best;
} else {
best = rib_choose_best(new_selected, re);
if (new_selected && best != new_selected)
UNSET_FLAG(new_selected->status, ROUTE_ENTRY_CHANGED);
new_selected = best;
}
if (best != re)
UNSET_FLAG(re->status, ROUTE_ENTRY_CHANGED);
} /* RNODE_FOREACH_RE */
...
/* Update fib according to selection results */
if (new_fib && old_fib)
rib_process_update_fib(zvrf, rn, old_fib, new_fib);
else if (new_fib)
rib_process_add_fib(zvrf, rn, new_fib);
else if (old_fib)
rib_process_del_fib(zvrf, rn, old_fib);
/* Remove all RE entries queued for removal */
/* Check if the dest can be deleted now. */
...
}
For new routes, rib_process_add_fib is called to add them to zebra's internal routing table and notify the dplane to update the kernel routing table:
static void rib_process_add_fib(struct zebra_vrf *zvrf, struct route_node *rn, struct route_entry *new)
{
hook_call(rib_update, rn, "new route selected");
...
/* If labeled-unicast route, install transit LSP. */
if (zebra_rib_labeled_unicast(new))
zebra_mpls_lsp_install(zvrf, rn, new);
rib_install_kernel(rn, new, NULL);
UNSET_FLAG(new->status, ROUTE_ENTRY_CHANGED);
}
void rib_install_kernel(struct route_node *rn, struct route_entry *re,
struct route_entry *old)
{
struct rib_table_info *info = srcdest_rnode_table_info(rn);
enum zebra_dplane_result ret;
rib_dest_t *dest = rib_dest_from_rnode(rn);
...
/* Install the resolved nexthop object first. */
zebra_nhg_install_kernel(re->nhe);
/* If this is a replace to a new RE let the originator of the RE know that they've lost */
if (old && (old != re) && (old->type != re->type))
zsend_route_notify_owner(rn, old, ZAPI_ROUTE_BETTER_ADMIN_WON, info->afi, info->safi);
/* Update fib selection */
dest->selected_fib = re;
/* Make sure we update the FPM any time we send new information to the kernel. */
hook_call(rib_update, rn, "installing in kernel");
/* Send add or update */
if (old) ret = dplane_route_update(rn, re, old);
else ret = dplane_route_add(rn, re);
...
}
There are two important operations here: one is to call the dplane_route_* functions to update the kernel routing table, and the other is the hook_call that appears twice here. The FPM hook function is hooked here to receive and forward routing table update notifications.
Here, let's look at them one by one:
dplane Updating Kernel Routing Table
Let's look at the dplane dplane_route_* functions first. They are essentially do the same thing: simply pack the request and put it into the dplane_thread message queue:
// File: src/sonic-frr/frr/zebra/zebra_dplane.c
enum zebra_dplane_result dplane_route_add(struct route_node *rn, struct route_entry *re) {
return dplane_route_update_internal(rn, re, NULL, DPLANE_OP_ROUTE_INSTALL);
}
enum zebra_dplane_result dplane_route_update(struct route_node *rn, struct route_entry *re, struct route_entry *old_re) {
return dplane_route_update_internal(rn, re, old_re, DPLANE_OP_ROUTE_UPDATE);
}
enum zebra_dplane_result dplane_sys_route_add(struct route_node *rn, struct route_entry *re) {
return dplane_route_update_internal(rn, re, NULL, DPLANE_OP_SYS_ROUTE_ADD);
}
static enum zebra_dplane_result
dplane_route_update_internal(struct route_node *rn, struct route_entry *re, struct route_entry *old_re, enum dplane_op_e op)
{
enum zebra_dplane_result result = ZEBRA_DPLANE_REQUEST_FAILURE;
int ret = EINVAL;
/* Create and init context */
struct zebra_dplane_ctx *ctx = ...;
/* Enqueue context for processing */
ret = dplane_route_enqueue(ctx);
/* Update counter */
atomic_fetch_add_explicit(&zdplane_info.dg_routes_in, 1, memory_order_relaxed);
if (ret == AOK)
result = ZEBRA_DPLANE_REQUEST_QUEUED;
return result;
}
Then, on the data plane handling thread dplane_thread, in its message loop, it take messages from the queue one by one and call their handling functions:
// File: src/sonic-frr/frr/zebra/zebra_dplane.c
static int dplane_thread_loop(struct thread *event)
{
...
while (prov) {
...
/* Process work here */
(*prov->dp_fp)(prov);
/* Check for zebra shutdown */
/* Dequeue completed work from the provider */
...
/* Locate next provider */
DPLANE_LOCK();
prov = TAILQ_NEXT(prov, dp_prov_link);
DPLANE_UNLOCK();
}
}
By default, dplane_thread uses kernel_dplane_process_func to process the messages. Inside this function, different kernel operations will be invoked based on the request type:
static int kernel_dplane_process_func(struct zebra_dplane_provider *prov)
{
enum zebra_dplane_result res;
struct zebra_dplane_ctx *ctx;
int counter, limit;
limit = dplane_provider_get_work_limit(prov);
for (counter = 0; counter < limit; counter++) {
ctx = dplane_provider_dequeue_in_ctx(prov);
if (ctx == NULL) break;
/* A previous provider plugin may have asked to skip the kernel update. */
if (dplane_ctx_is_skip_kernel(ctx)) {
res = ZEBRA_DPLANE_REQUEST_SUCCESS;
goto skip_one;
}
/* Dispatch to appropriate kernel-facing apis */
switch (dplane_ctx_get_op(ctx)) {
case DPLANE_OP_ROUTE_INSTALL:
case DPLANE_OP_ROUTE_UPDATE:
case DPLANE_OP_ROUTE_DELETE:
res = kernel_dplane_route_update(ctx);
break;
...
}
...
}
...
}
static enum zebra_dplane_result
kernel_dplane_route_update(struct zebra_dplane_ctx *ctx)
{
enum zebra_dplane_result res;
/* Call into the synchronous kernel-facing code here */
res = kernel_route_update(ctx);
return res;
}
And kernel_route_update is the real kernel operation. It notifies the kernel of route updates through netlink:
// File: src/sonic-frr/frr/zebra/rt_netlink.c
// Update or delete a prefix from the kernel, using info from a dataplane context.
enum zebra_dplane_result kernel_route_update(struct zebra_dplane_ctx *ctx)
{
int cmd, ret;
const struct prefix *p = dplane_ctx_get_dest(ctx);
struct nexthop *nexthop;
if (dplane_ctx_get_op(ctx) == DPLANE_OP_ROUTE_DELETE) {
cmd = RTM_DELROUTE;
} else if (dplane_ctx_get_op(ctx) == DPLANE_OP_ROUTE_INSTALL) {
cmd = RTM_NEWROUTE;
} else if (dplane_ctx_get_op(ctx) == DPLANE_OP_ROUTE_UPDATE) {
cmd = RTM_NEWROUTE;
}
if (!RSYSTEM_ROUTE(dplane_ctx_get_type(ctx)))
ret = netlink_route_multipath(cmd, ctx);
...
return (ret == 0 ? ZEBRA_DPLANE_REQUEST_SUCCESS : ZEBRA_DPLANE_REQUEST_FAILURE);
}
// Routing table change via netlink interface, using a dataplane context object
static int netlink_route_multipath(int cmd, struct zebra_dplane_ctx *ctx)
{
// Build netlink request.
struct {
struct nlmsghdr n;
struct rtmsg r;
char buf[NL_PKT_BUF_SIZE];
} req;
req.n.nlmsg_len = NLMSG_LENGTH(sizeof(struct rtmsg));
req.n.nlmsg_flags = NLM_F_CREATE | NLM_F_REQUEST;
...
/* Talk to netlink socket. */
return netlink_talk_info(netlink_talk_filter, &req.n, dplane_ctx_get_ns(ctx), 0);
}
FPM Route Update Forwarding
FPM (Forwarding Plane Manager) is the protocol in FRR used to notify other processes of route changes. Its main logic code is in src/sonic-frr/frr/zebra/zebra_fpm.c. It supports two protocols by default: protobuf and netlink. The one used in SONiC is the netlink protocol.
As mentioned earlier, it is implemented through hook functions. By listening for route changes in the RIB, the updates are forwarded to other processes through a local socket. This hook is registered at startup. And the most relevant one to us is the rib_update hook, as shown below:
static int zebra_fpm_module_init(void)
{
hook_register(rib_update, zfpm_trigger_update);
hook_register(zebra_rmac_update, zfpm_trigger_rmac_update);
hook_register(frr_late_init, zfpm_init);
hook_register(frr_early_fini, zfpm_fini);
return 0;
}
FRR_MODULE_SETUP(.name = "zebra_fpm", .version = FRR_VERSION,
.description = "zebra FPM (Forwarding Plane Manager) module",
.init = zebra_fpm_module_init,
);
When the rib_update hook is called, the zfpm_trigger_update function will be called, which puts the route update info into the fpm forwarding queue and triggers a write operation:
static int zfpm_trigger_update(struct route_node *rn, const char *reason)
{
rib_dest_t *dest;
...
// Queue the update request
dest = rib_dest_from_rnode(rn);
SET_FLAG(dest->flags, RIB_DEST_UPDATE_FPM);
TAILQ_INSERT_TAIL(&zfpm_g->dest_q, dest, fpm_q_entries);
...
zfpm_write_on();
return 0;
}
static inline void zfpm_write_on(void) {
thread_add_write(zfpm_g->master, zfpm_write_cb, 0, zfpm_g->sock, &zfpm_g->t_write);
}
The write callback takes the update from the queue, converts it into the FPM message format, and forwards it to other processes through a local socket:
static int zfpm_write_cb(struct thread *thread)
{
struct stream *s;
do {
int bytes_to_write, bytes_written;
s = zfpm_g->obuf;
// Convert route info to buffer here.
if (stream_empty(s)) zfpm_build_updates();
// Write to socket until we don' have anything to write or cannot write anymore (partial write).
bytes_to_write = stream_get_endp(s) - stream_get_getp(s);
bytes_written = write(zfpm_g->sock, stream_pnt(s), bytes_to_write);
...
} while (1);
if (zfpm_writes_pending()) zfpm_write_on();
return 0;
}
static void zfpm_build_updates(void)
{
struct stream *s = zfpm_g->obuf;
do {
/* Stop processing the queues if zfpm_g->obuf is full or we do not have more updates to process */
if (zfpm_build_mac_updates() == FPM_WRITE_STOP) break;
if (zfpm_build_route_updates() == FPM_WRITE_STOP) break;
} while (zfpm_updates_pending());
}
At this point, FRR's work is done.
References
- SONiC Architecture
- Github repo: sonic-swss
- Github repo: sonic-swss-common
- Github repo: sonic-frr
- Github repo: sonic-utilities
- Github repo: sonic-sairedis
- RFC 4271: A Border Gateway Protocol 4 (BGP-4)
- FRRouting
- FRRouting - BGP
- FRRouting - FPM
- Understanding EVPN Pure Type 5 Routes
Route Update in SONiC
After the work of FRR is done, the route update information is forwarded to SONiC, either via Netlink or FPM. This causes a series of operations in SONiC, and eventually updates the route table in the ASIC.
The main workflow is shown as below:
sequenceDiagram
autonumber
participant K as Linux Kernel
box purple bgp Container
participant Z as zebra
participant FPM as fpmsyncd
end
box darkred database Container
participant R as Redis
end
box darkblue swss Container
participant OA as orchagent
end
box darkgreen syncd Container
participant SD as syncd
end
participant A as ASIC
K->>FPM: Send notification via Netlink<br/>when kernel route changes
Z->>FPM: Send route update notification<br/>via FPM interface and Netlink<br/>message format
FPM->>R: Write route update information<br/>to APPL_DB through ProducerStateTable
R->>OA: Receive route update information<br/>through ConsumerStateTable
OA->>OA: Process route update information<br/>and generate SAI route object
OA->>SD: Send SAI route object<br/>to syncd through ProducerTable<br/>or ZMQ
SD->>R: Receive SAI route object, write to ASIC_DB
SD->>A: Configure ASIC through SAI interface
fpmsyncd Updating Route Configuration in Redis
First, let's start from the source. When fpmsyncd launches, it starts listening for FPM and Netlink events to receive route change messages and forward to RouteSync for processing:
// File: src/sonic-swss/fpmsyncd/fpmsyncd.cpp
int main(int argc, char **argv)
{
...
DBConnector db("APPL_DB", 0);
RedisPipeline pipeline(&db);
RouteSync sync(&pipeline);
// Register netlink message handler
NetLink netlink;
netlink.registerGroup(RTNLGRP_LINK);
NetDispatcher::getInstance().registerMessageHandler(RTM_NEWROUTE, &sync);
NetDispatcher::getInstance().registerMessageHandler(RTM_DELROUTE, &sync);
NetDispatcher::getInstance().registerMessageHandler(RTM_NEWLINK, &sync);
NetDispatcher::getInstance().registerMessageHandler(RTM_DELLINK, &sync);
rtnl_route_read_protocol_names(DefaultRtProtoPath);
...
while (true) {
try {
// Launching FPM server and wait for zebra to connect.
FpmLink fpm(&sync);
...
fpm.accept();
...
} catch (FpmLink::FpmConnectionClosedException &e) {
// If connection is closed, keep retrying until it succeeds, before handling any other events.
cout << "Connection lost, reconnecting..." << endl;
}
...
}
}
In FpmLink, the FPM events will be converted into Netlink messages. This unifies the message that being sent to RouteSync to Netlink. And RouteSync::onMsg will be called for processing them (for how Netlink receives and processes messages, please refer to 4.1.2 Netlink):
One small thing to notice is that - EVPN Type 5 messages must be processed in raw message form, so RouteSync::onMsgRaw will be called.
// File: src/sonic-swss/fpmsyncd/fpmlink.cpp
// Called from: FpmLink::readData()
void FpmLink::processFpmMessage(fpm_msg_hdr_t* hdr)
{
size_t msg_len = fpm_msg_len(hdr);
nlmsghdr *nl_hdr = (nlmsghdr *)fpm_msg_data(hdr);
...
/* Read all netlink messages inside FPM message */
for (; NLMSG_OK (nl_hdr, msg_len); nl_hdr = NLMSG_NEXT(nl_hdr, msg_len))
{
/*
* EVPN Type5 Add Routes need to be process in Raw mode as they contain
* RMAC, VLAN and L3VNI information.
* Where as all other route will be using rtnl api to extract information
* from the netlink msg.
*/
bool isRaw = isRawProcessing(nl_hdr);
nl_msg *msg = nlmsg_convert(nl_hdr);
...
nlmsg_set_proto(msg, NETLINK_ROUTE);
if (isRaw) {
/* EVPN Type5 Add route processing */
/* This will call into onRawMsg() */
processRawMsg(nl_hdr);
} else {
/* This will call into onMsg() */
NetDispatcher::getInstance().onNetlinkMessage(msg);
}
nlmsg_free(msg);
}
}
void FpmLink::processRawMsg(struct nlmsghdr *h)
{
m_routesync->onMsgRaw(h);
};
Next, when RouteSync receives a route change message, it makes judgments and dispatches in onMsg and onMsgRaw:
// File: src/sonic-swss/fpmsyncd/routesync.cpp
void RouteSync::onMsgRaw(struct nlmsghdr *h)
{
if ((h->nlmsg_type != RTM_NEWROUTE) && (h->nlmsg_type != RTM_DELROUTE))
return;
...
onEvpnRouteMsg(h, len);
}
void RouteSync::onMsg(int nlmsg_type, struct nl_object *obj)
{
// Refill Netlink cache here
...
struct rtnl_route *route_obj = (struct rtnl_route *)obj;
auto family = rtnl_route_get_family(route_obj);
if (family == AF_MPLS) {
onLabelRouteMsg(nlmsg_type, obj);
return;
}
...
unsigned int master_index = rtnl_route_get_table(route_obj);
char master_name[IFNAMSIZ] = {0};
if (master_index) {
/* If the master device name starts with VNET_PREFIX, it is a VNET route.
The VNET name is exactly the name of the associated master device. */
getIfName(master_index, master_name, IFNAMSIZ);
if (string(master_name).find(VNET_PREFIX) == 0) {
onVnetRouteMsg(nlmsg_type, obj, string(master_name));
}
/* Otherwise, it is a regular route (include VRF route). */
else {
onRouteMsg(nlmsg_type, obj, master_name);
}
} else {
onRouteMsg(nlmsg_type, obj, NULL);
}
}
From the code above, we can see that there are four different route processing entry points. These different routes will be finally written to different tables in APPL_DB through their respective ProducerStateTable:
| Route Type | Entry Point | Table |
|---|---|---|
| MPLS | onLabelRouteMsg | LABLE_ROUTE_TABLE |
| Vnet VxLan Tunnel Route | onVnetRouteMsg | VNET_ROUTE_TUNNEL_TABLE |
| Other Vnet Routes | onVnetRouteMsg | VNET_ROUTE_TABLE |
| EVPN Type 5 | onEvpnRouteMsg | ROUTE_TABLE |
| Regular Routes | onRouteMsg | ROUTE_TABLE |
Here we take regular routes as an example. The implementation of other functions is different, but the basic idea is the same:
// File: src/sonic-swss/fpmsyncd/routesync.cpp
void RouteSync::onRouteMsg(int nlmsg_type, struct nl_object *obj, char *vrf)
{
// Parse route info from nl_object here.
...
// Get nexthop lists
string gw_list;
string intf_list;
string mpls_list;
getNextHopList(route_obj, gw_list, mpls_list, intf_list);
...
// Build route info here, including protocol, interface, next hops, MPLS, weights etc.
vector<FieldValueTuple> fvVector;
FieldValueTuple proto("protocol", proto_str);
FieldValueTuple gw("nexthop", gw_list);
...
fvVector.push_back(proto);
fvVector.push_back(gw);
...
// Push to ROUTE_TABLE via ProducerStateTable.
m_routeTable.set(destipprefix, fvVector);
SWSS_LOG_DEBUG("RouteTable set msg: %s %s %s %s", destipprefix, gw_list.c_str(), intf_list.c_str(), mpls_list.c_str());
...
}
orchagent Processing Route Configuration Changes
Next, these route information will come to orchagent. When orchagent starts, it creates VNetRouteOrch and RouteOrch objects, which are used to listen and process Vnet-related routes and EVPN/regular routes respectively:
// File: src/sonic-swss/orchagent/orchdaemon.cpp
bool OrchDaemon::init()
{
...
vector<string> vnet_tables = { APP_VNET_RT_TABLE_NAME, APP_VNET_RT_TUNNEL_TABLE_NAME };
VNetRouteOrch *vnet_rt_orch = new VNetRouteOrch(m_applDb, vnet_tables, vnet_orch);
...
const int routeorch_pri = 5;
vector<table_name_with_pri_t> route_tables = {
{ APP_ROUTE_TABLE_NAME, routeorch_pri },
{ APP_LABEL_ROUTE_TABLE_NAME, routeorch_pri }
};
gRouteOrch = new RouteOrch(m_applDb, route_tables, gSwitchOrch, gNeighOrch, gIntfsOrch, vrf_orch, gFgNhgOrch, gSrv6Orch);
...
}
The entry function that process the incoming messages for all Orch objects is doTask. RouteOrch and VNetRouteOrch are the same. Here we take RouteOrch as an example to see how it handles route changes.
From RouteOrch, we can truly feel why these classes are named Orch. RouteOrch has more than 2500 lines, involving interactions with many other Orch objects and tons of details... The code is relatively difficult to read, so please be patient when reading.
Before we dive into the code, we have a few things to note for RouteOrch:
- From the above
initfunction, we can see thatRouteOrchnot only manages regular routes but also manages MPLS routes. The logic for handling these two types of routes is different. Therefore, in the following code, to simplify, we only show the logic for handling the regular routes. - Since
ProducerStateTabletransmits and receives messages in batches,RouteOrchalso processes the route updates in batches. To support batch processing,RouteOrchusesEntityBulker<sai_route_api_t> gRouteBulkerto cache the SAI route objects that need to be changed, and then applies these route object changes to SAI at the end of thedoTask()function. - Route operations require a lot of other information, such as the status of each port, the status of each neighbor, the status of each VRF, etc. To obtain this information,
RouteOrchinteracts with other Orch objects, such asPortOrch,NeighOrch,VRFOrch, etc.
Let's start with the RouteOrch::doTask function. It parses the incoming route operation messages, then calls the addRoute or removeRoute function to create or delete routes.
// File: src/sonic-swss/orchagent/routeorch.cpp
void RouteOrch::doTask(Consumer& consumer)
{
// Calling PortOrch to make sure all ports are ready before processing route messages.
if (!gPortsOrch->allPortsReady()) { return; }
// Call doLabelTask() instead, if the incoming messages are from MPLS messages. Otherwise, move on as regular routes.
...
/* Default handling is for ROUTE_TABLE (regular routes) */
auto it = consumer.m_toSync.begin();
while (it != consumer.m_toSync.end()) {
// Add or remove routes with a route bulker
while (it != consumer.m_toSync.end())
{
KeyOpFieldsValuesTuple t = it->second;
// Parse route operation from the incoming message here.
string key = kfvKey(t);
string op = kfvOp(t);
...
// resync application:
// - When routeorch receives 'resync' message (key = "resync", op = "SET"), it marks all current routes as dirty
// and waits for 'resync complete' message. For all newly received routes, if they match current dirty routes,
// it unmarks them dirty.
// - After receiving 'resync complete' (key = "resync", op != "SET") message, it creates all newly added routes
// and removes all dirty routes.
...
// Parsing VRF and IP prefix from the incoming message here.
...
// Process regular route operations.
if (op == SET_COMMAND)
{
// Parse and validate route attributes from the incoming message here.
string ips;
string aliases;
...
// If the nexthop_group is empty, create the next hop group key based on the IPs and aliases.
// Otherwise, get the key from the NhgOrch. The result will be stored in the "nhg" variable below.
NextHopGroupKey& nhg = ctx.nhg;
...
if (nhg_index.empty())
{
// Here the nexthop_group is empty, so we create the next hop group key based on the IPs and aliases.
...
string nhg_str = "";
if (blackhole) {
nhg = NextHopGroupKey();
} else if (srv6_nh == true) {
...
nhg = NextHopGroupKey(nhg_str, overlay_nh, srv6_nh);
} else if (overlay_nh == false) {
...
nhg = NextHopGroupKey(nhg_str, weights);
} else {
...
nhg = NextHopGroupKey(nhg_str, overlay_nh, srv6_nh);
}
}
else
{
// Here we have a nexthop_group, so we get the key from the NhgOrch.
const NhgBase& nh_group = getNhg(nhg_index);
nhg = nh_group.getNhgKey();
...
}
...
// Now we start to create the SAI route entry.
if (nhg.getSize() == 1 && nhg.hasIntfNextHop())
{
// Skip certain routes, such as not valid, directly routes to tun0, linklocal or multicast routes, etc.
...
// Create SAI route entry in addRoute function.
if (addRoute(ctx, nhg)) it = consumer.m_toSync.erase(it);
else it++;
}
/*
* Check if the route does not exist or needs to be updated or
* if the route is using a temporary next hop group owned by
* NhgOrch.
*/
else if (m_syncdRoutes.find(vrf_id) == m_syncdRoutes.end() ||
m_syncdRoutes.at(vrf_id).find(ip_prefix) == m_syncdRoutes.at(vrf_id).end() ||
m_syncdRoutes.at(vrf_id).at(ip_prefix) != RouteNhg(nhg, ctx.nhg_index) ||
gRouteBulker.bulk_entry_pending_removal(route_entry) ||
ctx.using_temp_nhg)
{
if (addRoute(ctx, nhg)) it = consumer.m_toSync.erase(it);
else it++;
}
...
}
// Handle other ops, like DEL_COMMAND for route deletion, etc.
...
}
// Flush the route bulker, so routes will be written to syncd and ASIC
gRouteBulker.flush();
// Go through the bulker results.
// Handle SAI failures, update neighbors, counters, send notifications in add/removeRoutePost functions.
...
/* Remove next hop group if the reference count decreases to zero */
...
}
}
Here we take addRoute as an example. It mainly does a few things below:
- Get next hop information from
NeighOrchand check if the next hop is really available. - If the route is a new or re-added back while waiting to be deleted, a new SAI route object will be created.
- If it is an existing route, the existing SAI route object is updated.
// File: src/sonic-swss/orchagent/routeorch.cpp
bool RouteOrch::addRoute(RouteBulkContext& ctx, const NextHopGroupKey &nextHops)
{
// Get nexthop information from NeighOrch.
// We also need to check PortOrch for inband port, IntfsOrch to ensure the related interface is created and etc.
...
// Start to sync the SAI route entry.
sai_route_entry_t route_entry;
route_entry.vr_id = vrf_id;
route_entry.switch_id = gSwitchId;
copy(route_entry.destination, ipPrefix);
sai_attribute_t route_attr;
auto& object_statuses = ctx.object_statuses;
// Create a new route entry in this case.
//
// In case the entry is already pending removal in the bulk, it would be removed from m_syncdRoutes during the bulk call.
// Therefore, such entries need to be re-created rather than set attribute.
if (it_route == m_syncdRoutes.at(vrf_id).end() || gRouteBulker.bulk_entry_pending_removal(route_entry)) {
if (blackhole) {
route_attr.id = SAI_ROUTE_ENTRY_ATTR_PACKET_ACTION;
route_attr.value.s32 = SAI_PACKET_ACTION_DROP;
} else {
route_attr.id = SAI_ROUTE_ENTRY_ATTR_NEXT_HOP_ID;
route_attr.value.oid = next_hop_id;
}
/* Default SAI_ROUTE_ATTR_PACKET_ACTION is SAI_PACKET_ACTION_FORWARD */
object_statuses.emplace_back();
sai_status_t status = gRouteBulker.create_entry(&object_statuses.back(), &route_entry, 1, &route_attr);
if (status == SAI_STATUS_ITEM_ALREADY_EXISTS) {
return false;
}
}
// Update existing route entry in this case.
else {
// Set the packet action to forward when there was no next hop (dropped) and not pointing to blackhole.
if (it_route->second.nhg_key.getSize() == 0 && !blackhole) {
route_attr.id = SAI_ROUTE_ENTRY_ATTR_PACKET_ACTION;
route_attr.value.s32 = SAI_PACKET_ACTION_FORWARD;
object_statuses.emplace_back();
gRouteBulker.set_entry_attribute(&object_statuses.back(), &route_entry, &route_attr);
}
// Only 1 case is listed here as an example. Other cases are handled with similar logic by calling set_entry_attributes as well.
...
}
...
}
After creating and setting up all the routes, RouteOrch calls gRouteBulker.flush() to write all the routes to ASIC_DB. The flush() function is straightforward: it processes all requests in batches, with each batch being 1000 by default, defined in OrchDaemon and passed through the constructor:
// File: src/sonic-swss/orchagent/orchdaemon.cpp
#define DEFAULT_MAX_BULK_SIZE 1000
size_t gMaxBulkSize = DEFAULT_MAX_BULK_SIZE;
// File: src/sonic-swss/orchagent/bulker.h
template <typename T>
class EntityBulker
{
public:
using Ts = SaiBulkerTraits<T>;
using Te = typename Ts::entry_t;
...
void flush()
{
// Bulk remove entries
if (!removing_entries.empty()) {
// Split into batches of max_bulk_size, then call flush. Similar to creating_entries, so details are omitted.
std::vector<Te> rs;
...
flush_removing_entries(rs);
removing_entries.clear();
}
// Bulk create entries
if (!creating_entries.empty()) {
// Split into batches of max_bulk_size, then call flush_creating_entries to call SAI batch create API to create
// the objects in batch.
std::vector<Te> rs;
std::vector<sai_attribute_t const*> tss;
std::vector<uint32_t> cs;
for (auto const& i: creating_entries) {
sai_object_id_t *pid = std::get<0>(i);
auto const& attrs = std::get<1>(i);
if (*pid == SAI_NULL_OBJECT_ID) {
rs.push_back(pid);
tss.push_back(attrs.data());
cs.push_back((uint32_t)attrs.size());
// Batch create here.
if (rs.size() >= max_bulk_size) {
flush_creating_entries(rs, tss, cs);
}
}
}
flush_creating_entries(rs, tss, cs);
creating_entries.clear();
}
// Bulk update existing entries
if (!setting_entries.empty()) {
// Split into batches of max_bulk_size, then call flush. Similar to creating_entries, so details are omitted.
std::vector<Te> rs;
std::vector<sai_attribute_t> ts;
std::vector<sai_status_t*> status_vector;
...
flush_setting_entries(rs, ts, status_vector);
setting_entries.clear();
}
}
sai_status_t flush_creating_entries(
_Inout_ std::vector<Te> &rs,
_Inout_ std::vector<sai_attribute_t const*> &tss,
_Inout_ std::vector<uint32_t> &cs)
{
...
// Call SAI bulk create API
size_t count = rs.size();
std::vector<sai_status_t> statuses(count);
sai_status_t status = (*create_entries)((uint32_t)count, rs.data(), cs.data(), tss.data()
, SAI_BULK_OP_ERROR_MODE_IGNORE_ERROR, statuses.data());
// Set results back to input entries and clean up the batch below.
for (size_t ir = 0; ir < count; ir++) {
auto& entry = rs[ir];
sai_status_t *object_status = creating_entries[entry].second;
if (object_status) {
*object_status = statuses[ir];
}
}
rs.clear(); tss.clear(); cs.clear();
return status;
}
// flush_removing_entries and flush_setting_entries are similar to flush_creating_entries, so we omit them here.
...
};
SAI Object Forwarding in orchagent
At this point, you might have noticed something strange - The EntityBulker seems to be directly calling the SAI API. Shouldn't they be called in syncd? If we follow the SAI API objects passed to EntityBulker, we will even find that sai_route_api_t is indeed the SAI interface, and there is SAI initialization code in orchagent, as follows:
// File: src/sonic-sairedis/debian/libsaivs-dev/usr/include/sai/sairoute.h
/**
* @brief Router entry methods table retrieved with sai_api_query()
*/
typedef struct _sai_route_api_t
{
sai_create_route_entry_fn create_route_entry;
sai_remove_route_entry_fn remove_route_entry;
sai_set_route_entry_attribute_fn set_route_entry_attribute;
sai_get_route_entry_attribute_fn get_route_entry_attribute;
sai_bulk_create_route_entry_fn create_route_entries;
sai_bulk_remove_route_entry_fn remove_route_entries;
sai_bulk_set_route_entry_attribute_fn set_route_entries_attribute;
sai_bulk_get_route_entry_attribute_fn get_route_entries_attribute;
} sai_route_api_t;
// File: src/sonic-swss/orchagent/saihelper.cpp
void initSaiApi()
{
SWSS_LOG_ENTER();
if (ifstream(CONTEXT_CFG_FILE))
{
SWSS_LOG_NOTICE("Context config file %s exists", CONTEXT_CFG_FILE);
gProfileMap[SAI_REDIS_KEY_CONTEXT_CONFIG] = CONTEXT_CFG_FILE;
}
sai_api_initialize(0, (const sai_service_method_table_t *)&test_services);
sai_api_query(SAI_API_SWITCH, (void **)&sai_switch_api);
...
sai_api_query(SAI_API_NEIGHBOR, (void **)&sai_neighbor_api);
sai_api_query(SAI_API_NEXT_HOP, (void **)&sai_next_hop_api);
sai_api_query(SAI_API_NEXT_HOP_GROUP, (void **)&sai_next_hop_group_api);
sai_api_query(SAI_API_ROUTE, (void **)&sai_route_api);
...
sai_log_set(SAI_API_SWITCH, SAI_LOG_LEVEL_NOTICE);
...
sai_log_set(SAI_API_NEIGHBOR, SAI_LOG_LEVEL_NOTICE);
sai_log_set(SAI_API_NEXT_HOP, SAI_LOG_LEVEL_NOTICE);
sai_log_set(SAI_API_NEXT_HOP_GROUP, SAI_LOG_LEVEL_NOTICE);
sai_log_set(SAI_API_ROUTE, SAI_LOG_LEVEL_NOTICE);
...
}
I believe whoever saw this code for the first time will definitely feel confused. But don't worry, this is actually the SAI object forwarding mechanism in orchagent.
If you are familiar with RPC, the proxy-stub pattern might sounds very familar to you - using a unified way to define the interfaces called by both parties in communication, implementing message serialization and sending on the client side, and implementing message receiving, deserialization, and dispatching on the server side. Here, SONiC does something similar: using the SAI API itself as a unified interface, implementing message serialization and sending for orchagent to call, and implementing message receiving, deserialization, and dispatch functions in syncd.
Here, the sending end is called ClientSai, implemented in src/sonic-sairedis/lib/ClientSai.*. Serialization and deserialization are implemented in SAI metadata: src/sonic-sairedis/meta/sai_serialize.h:
// File: src/sonic-sairedis/lib/ClientSai.h
namespace sairedis
{
class ClientSai:
public sairedis::SaiInterface
{
...
};
}
// File: src/sonic-sairedis/meta/sai_serialize.h
// Serialize
std::string sai_serialize_route_entry(_In_ const sai_route_entry_t &route_entry);
...
// Deserialize
void sai_deserialize_route_entry(_In_ const std::string& s, _In_ sai_route_entry_t &route_entry);
...
When orchagent is compiled, it links to libsairedis, which implements the SAI client and handles the serialization and message sending:
# File: src/sonic-swss/orchagent/Makefile.am
orchagent_LDADD = $(LDFLAGS_ASAN) -lnl-3 -lnl-route-3 -lpthread -lsairedis -lsaimeta -lsaimetadata -lswsscommon -lzmq
Here, we use Bulk Create as an example to see how ClientSai serializes and sends the SAI API call:
// File: src/sonic-sairedis/lib/ClientSai.cpp
sai_status_t ClientSai::bulkCreate(
_In_ sai_object_type_t object_type,
_In_ sai_object_id_t switch_id,
_In_ uint32_t object_count,
_In_ const uint32_t *attr_count,
_In_ const sai_attribute_t **attr_list,
_In_ sai_bulk_op_error_mode_t mode,
_Out_ sai_object_id_t *object_id,
_Out_ sai_status_t *object_statuses)
{
MUTEX();
REDIS_CHECK_API_INITIALIZED();
std::vector<std::string> serialized_object_ids;
// Server is responsible for generate new OID but for that we need switch ID
// to be sent to server as well, so instead of sending empty oids we will
// send switch IDs
for (uint32_t idx = 0; idx < object_count; idx++) {
serialized_object_ids.emplace_back(sai_serialize_object_id(switch_id));
}
auto status = bulkCreate(object_type, serialized_object_ids, attr_count, attr_list, mode, object_statuses);
// Since user requested create, OID value was created remotely and it was returned in m_lastCreateOids
for (uint32_t idx = 0; idx < object_count; idx++) {
if (object_statuses[idx] == SAI_STATUS_SUCCESS) {
object_id[idx] = m_lastCreateOids.at(idx);
} else {
object_id[idx] = SAI_NULL_OBJECT_ID;
}
}
return status;
}
sai_status_t ClientSai::bulkCreate(
_In_ sai_object_type_t object_type,
_In_ const std::vector<std::string> &serialized_object_ids,
_In_ const uint32_t *attr_count,
_In_ const sai_attribute_t **attr_list,
_In_ sai_bulk_op_error_mode_t mode,
_Inout_ sai_status_t *object_statuses)
{
...
// Calling SAI serialize APIs to serialize all objects
std::string str_object_type = sai_serialize_object_type(object_type);
std::vector<swss::FieldValueTuple> entries;
for (size_t idx = 0; idx < serialized_object_ids.size(); ++idx) {
auto entry = SaiAttributeList::serialize_attr_list(object_type, attr_count[idx], attr_list[idx], false);
if (entry.empty()) {
swss::FieldValueTuple null("NULL", "NULL");
entry.push_back(null);
}
std::string str_attr = Globals::joinFieldValues(entry);
swss::FieldValueTuple fvtNoStatus(serialized_object_ids[idx] , str_attr);
entries.push_back(fvtNoStatus);
}
std::string key = str_object_type + ":" + std::to_string(entries.size());
// Send to syncd via the communication channel.
m_communicationChannel->set(key, entries, REDIS_ASIC_STATE_COMMAND_BULK_CREATE);
// Wait for response from syncd.
return waitForBulkResponse(SAI_COMMON_API_BULK_CREATE, (uint32_t)serialized_object_ids.size(), object_statuses);
}
Finally, ClientSai calls m_communicationChannel->set() to send the serialized SAI objects to syncd. This channel, before the 202106 version, was the ProducerTable based on Redis. Possibly for efficiency reasons, starting from the 202111 version, this channel has been changed to ZMQ.
// File: https://github.com/sonic-net/sonic-sairedis/blob/202106/lib/inc/RedisChannel.h
class RedisChannel: public Channel
{
...
/**
* @brief Asic state channel.
*
* Used to sent commands like create/remove/set/get to syncd.
*/
std::shared_ptr<swss::ProducerTable> m_asicState;
...
};
// File: src/sonic-sairedis/lib/ClientSai.cpp
sai_status_t ClientSai::initialize(
_In_ uint64_t flags,
_In_ const sai_service_method_table_t *service_method_table)
{
...
m_communicationChannel = std::make_shared<ZeroMQChannel>(
cc->m_zmqEndpoint,
cc->m_zmqNtfEndpoint,
std::bind(&ClientSai::handleNotification, this, _1, _2, _3));
m_apiInitialized = true;
return SAI_STATUS_SUCCESS;
}
For the inter-process communication, we are going to skip the details here. Please feel free to refer to the Redis-based channels described in Chapter 4.
syncd Updating ASIC
Finally, when the SAI objects are generated and sent to syncd, syncd will receive, processa and updates ASIC_DB, then finally updates the ASIC. We have already described this workflow in detail in the Syncd-SAI Workflow, so we will skip them here. For more details, please refer to the Syncd-SAI Workflow chapter.
References
- SONiC Architecture
- Github repo: sonic-swss
- Github repo: sonic-swss-common
- Github repo: sonic-frr
- Github repo: sonic-utilities
- Github repo: sonic-sairedis
- RFC 4271: A Border Gateway Protocol 4 (BGP-4)
- FRRouting
- FRRouting - BGP
- FRRouting - FPM
- Understanding EVPN Pure Type 5 Routes