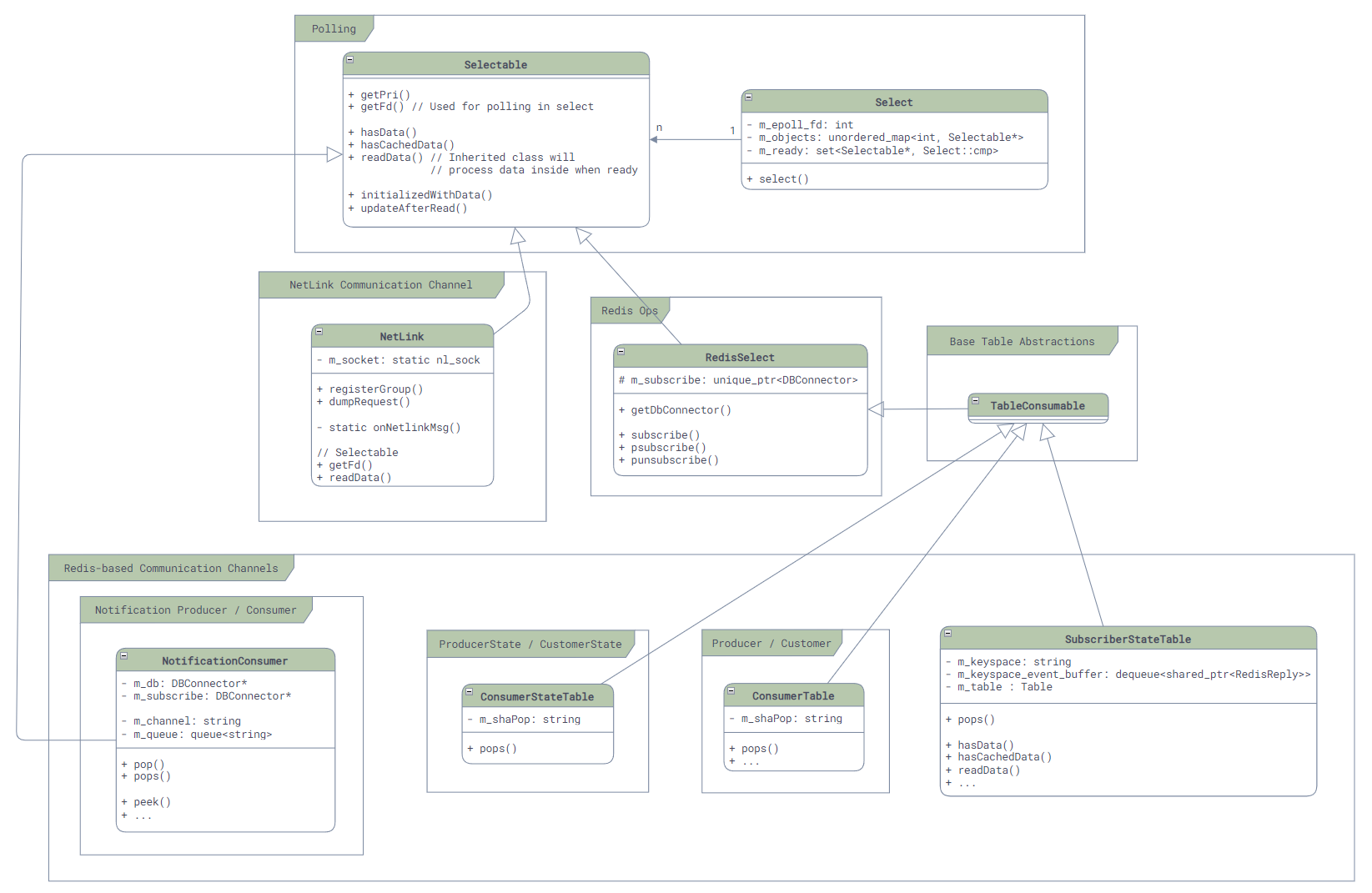
Event Dispatching and Error Handling
Epoll-based Event Dispatching
Just like many other Linux services, SONiC uses epoll at its core for event dispatching:
- Any class that supports event dispatching should inherit from
Selectableand implement two key functions:int getFd();: Returns the fd for epoll to listen on. For most services, this fd is the one used for Redis communication, so the call togetFd()ultimately delegates to the Redis library.uint64_t readData(): Reads data when an event arrives.
- Any objects that need to participate in event dispatching must register with the
Selectclass. This class registers allSelectableobjects' fds with epoll and callsSelectable'sreadData()when an event arrives.
Here's the class diagram:
The core logic lives in the Select class, which can be simplified as follows:
int Select::poll_descriptors(Selectable **c, unsigned int timeout, bool interrupt_on_signal = false)
{
int sz_selectables = static_cast<int>(m_objects.size());
std::vector<struct epoll_event> events(sz_selectables);
int ret;
while(true) {
ret = ::epoll_wait(m_epoll_fd, events.data(), sz_selectables, timeout);
// ...
}
// ...
for (int i = 0; i < ret; ++i)
{
int fd = events[i].data.fd;
Selectable* sel = m_objects[fd];
sel->readData();
// error handling here ...
m_ready.insert(sel);
}
while (!m_ready.empty())
{
auto sel = *m_ready.begin();
m_ready.erase(sel);
// After update callback ...
return Select::OBJECT;
}
return Select::TIMEOUT;
}
However, here comes the question... where is the callback? As mentioned, readData() only reads the message and stores it in a pending queue for processing. The real processing needs to call pops(). So at which point does every upper-level message handler get called?
Here, let's look back again at portmgrd's main function. From the simplified code below, we can see - unlike a typical event loop, SONiC does not handle events with callbacks; the outermost event loop directly calls the actual handlers:
int main(int argc, char **argv)
{
// ...
// Create PortMgr, which implements Orch interface.
PortMgr portmgr(&cfgDb, &appDb, &stateDb, cfg_port_tables);
vector<Orch *> cfgOrchList = {&portmgr};
// Create Select object for event loop and add PortMgr to it.
swss::Select s;
for (Orch *o : cfgOrchList) {
s.addSelectables(o->getSelectables());
}
// Event loop
while (true)
{
Selectable *sel;
int ret;
// When anyone of the selectables gets signaled, select() will call
// into readData() and fetch all events, then return.
ret = s.select(&sel, SELECT_TIMEOUT);
// ...
// Then, we call into execute() explicitly to process all events.
auto *c = (Executor *)sel;
c->execute();
}
return -1;
}
Error Handling
Another thing about event loops is error handling. For example, if a Redis command fails, or the connection is broken, or any kind of failure happens, what will happen to our services?
SONiC's error handling is very simple: it just throws exceptions (for example, in the code that fetches command results). Then the event loop catches the exceptions, logs them, and continues:
RedisReply::RedisReply(RedisContext *ctx, const RedisCommand& command)
{
int rc = redisAppendFormattedCommand(ctx->getContext(), command.c_str(), command.length());
if (rc != REDIS_OK)
{
// The only reason of error is REDIS_ERR_OOM (Out of memory)
// ref: https://github.com/redis/hiredis/blob/master/hiredis.c
throw bad_alloc();
}
rc = redisGetReply(ctx->getContext(), (void**)&m_reply);
if (rc != REDIS_OK)
{
throw RedisError("Failed to redisGetReply with " + string(command.c_str()), ctx->getContext());
}
guard([&]{checkReply();}, command.c_str());
}
There is no specific code here for statistics or telemetry, so monitoring is somewhat weak. We also need to consider data errors (for example, partial writes leading to corrupted data), though simply restarting *syncd or *mgrd services might fix such issues because many stored data in database will be wiped out, such as APPL_DB, and the services will do a full sync on startup.