Event Dispatching and Error Handling
基于epoll的事件分发机制
As with many Linux services, SONiC uses epoll as the event distribution mechanism at the bottom:
- 所有需要支持事件分发的类都需要继承
Selectable类,并实现两个最核心的函数:int getFd();(用于返回epoll能用来监听事件的fd)和uint64_t readData()(用于在监听到事件到来之后进行读取)。而对于一般服务而言,这个fd就是redis通信使用的fd,所以getFd()函数的调用,都会被最终转发到Redis的库中。 - 所有需要参与事件分发的对象,都需要注册到
Select类中,这个类会将所有的Selectable对象的fd注册到epoll中,并在事件到来时调用Selectable的readData()函数。
The class diagram is as follows:
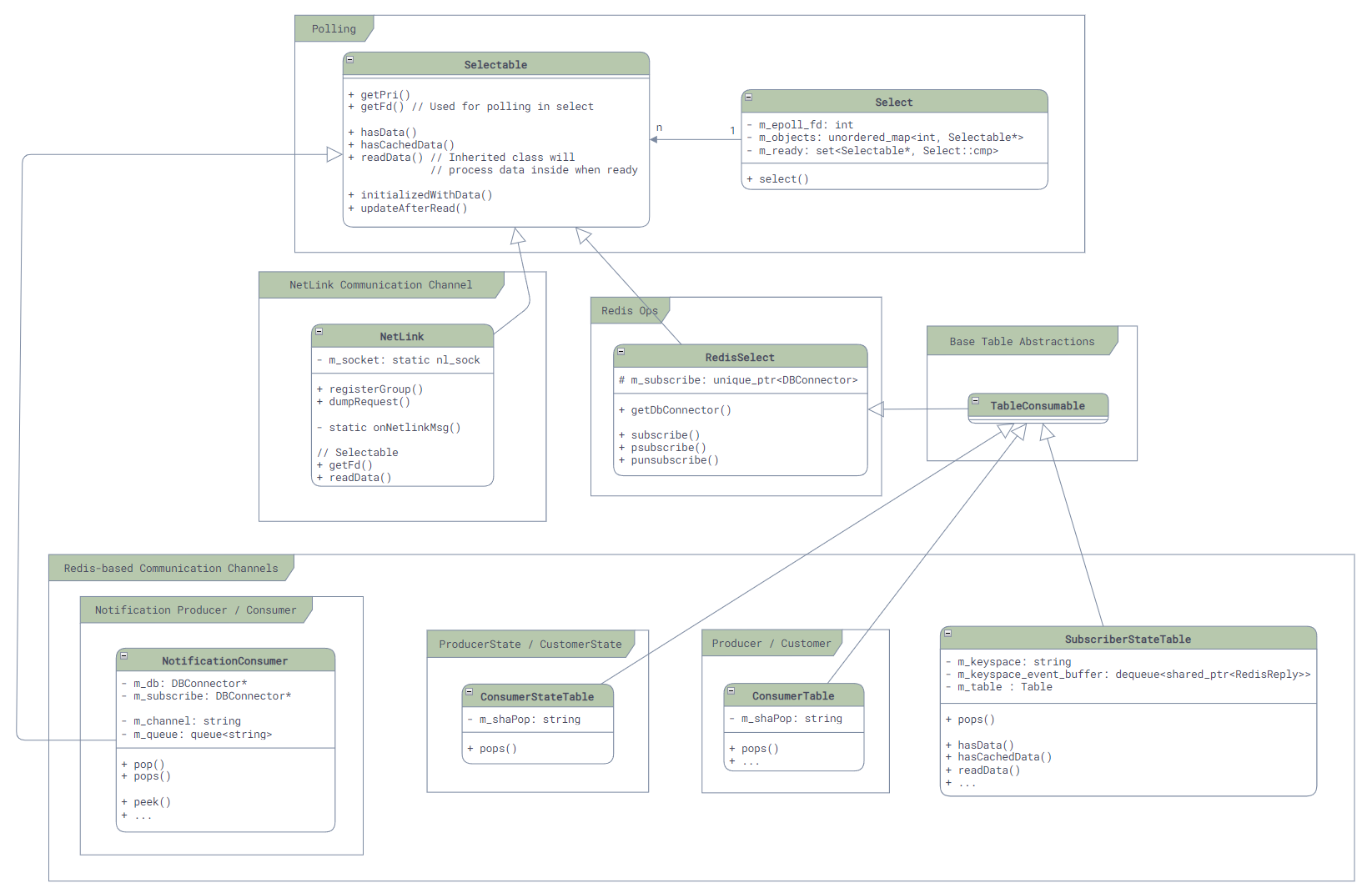
In the Select class, we can easily find its most core code, and the implementation is very simple:
int Select::poll_descriptors(Selectable **c, unsigned int timeout, bool interrupt_on_signal = false)
{
int sz_selectables = static_cast<int>(m_objects.size());
std::vector<struct epoll_event> events(sz_selectables);
int ret;
while(true) {
ret = ::epoll_wait(m_epoll_fd, events.data(), sz_selectables, timeout);
// ...
}
// ...
for (int i = 0; i < ret; ++i)
{
int fd = events[i].data.fd;
Selectable* sel = m_objects[fd];
sel->readData();
// error handling here ...
m_ready.insert(sel);
}
while (!m_ready.empty())
{
auto sel = *m_ready.begin();
m_ready.erase(sel);
// After update callback ...
return Select::OBJECT;
}
return Select::TIMEOUT;
}
However, the question arises ...... What about callbacks? As we mentioned above, readData() just reads the message out and puts it in a pending queue, it doesn't really process the message, the real message processing needs to call the pops() function to take the message out and process it, so where does it call each of the upper level wrapped message processing?
Here we still find the main function of our old friend portmgrd. From the following simplified code, we can see that unlike the general Event Loop implementation, the final event handling in SONiC is not achieved through callbacks, but requires the outermost Event Loop to be actively called to complete:
int main(int argc, char **argv)
{
// ...
// Create PortMgr, which implements Orch interface.
PortMgr portmgr(&cfgDb, &appDb, &stateDb, cfg_port_tables);
vector<Orch *> cfgOrchList = {&portmgr};
// Create Select object for event loop and add PortMgr to it.
swss::Select s;
for (Orch *o : cfgOrchList) {
s.addSelectables(o->getSelectables());
}
// Event loop
while (true)
{
Selectable *sel;
int ret;
// When anyone of the selectables gets signaled, select() will call
// into readData() and fetch all events, then return.
ret = s.select(&sel, SELECT_TIMEOUT);
// ...
// Then, we call into execute() explicitly to process all events.
auto *c = (Executor *)sel;
c->execute();
}
return -1;
}
错误处理
Another issue we have with Event Loop is error handling. For example, what happens to our service if a Redis command is executed incorrectly, a connection is broken, a fault occurs, etc.?
From the code point of view, the error handling in SONiC is very simple, that is, it just throws an exception (for example, the code to get the result of command execution, as follows), then catches the exception in the Event Loop, prints the log, and then continues the execution.
RedisReply::RedisReply(RedisContext *ctx, const RedisCommand& command)
{
int rc = redisAppendFormattedCommand(ctx->getContext(), command.c_str(), command.length());
if (rc != REDIS_OK)
{
// The only reason of error is REDIS_ERR_OOM (Out of memory)
// ref: https://github.com/redis/hiredis/blob/master/hiredis.c
throw bad_alloc();
}
rc = redisGetReply(ctx->getContext(), (void**)&m_reply);
if (rc != REDIS_OK)
{
throw RedisError("Failed to redisGetReply with " + string(command.c_str()), ctx->getContext());
}
guard([&]{checkReply();}, command.c_str());
}
Regarding the types of exceptions and errors and their causes, there is no code seen inside the code for statistics and Telemetry, so monitoring is said to be weak. Also need to consider data error scenarios, such as dirty data due to sudden disconnection halfway through writing the database, but a simple restart of the related *syncd and *mgrd services may solve such problems, as the full amount of synchronization will be performed at startup.