PCIe(二) —— 配置空间
在上一篇中,我们简单的介绍了PCIe的总体架构,设备树和主要组成部分,并且了解了如何通过lspci命令和Windows下的设备管理器来查看PCIe的系统结构。这一篇,我们来更加深入的看看PCIe中的设备相关的信息,如配置空间,来帮助我们了解PCIe和这些命令的工作原理。
1. It is all about memory
理解PCIe的关键,我个人觉得是理解内存的访问。这里先小小的剧透一下,PCIe中主要定义了4种请求:Memory Transaction,I/O request,Configuration Space Access和Message。除了最后一种以外,其余三种全都是基于内存访问的,甚至连中断发起都是基于内存访问的,所以如果我们能很好的理解内存的访问,我们就能很好的理解PCIe。
学过操作系统的小伙伴对虚拟内存这个概念肯定不陌生。在现代的操作系统中,当CPU想去访问一段内存的时候,它访问的地址并不是真实内存的物理地址,而是一个虚拟地址,这个地址需要经过MMU进行地址转换,将其变为物理地址之后才能通过总线去物理内存拿到真实的数据 [2]。
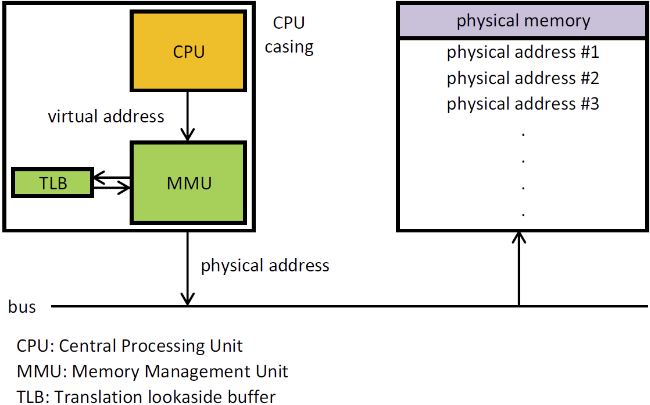
而PCIe中基于内存访问的请求的实现,也正是利用类似的机制:
- PCIe中的每一个设备,无论是Endpoint(Type 0)还是Switch(Type 1),都会分配自己的内存地址空间,而这个地址空间会被映射到系统的物理地址空间中,并最终映射到虚拟内存中去。
- 当CPU发起一个内存读写请求的时候,如果这个地址经过了MMU的翻译,最后的物理地址落到了PCIe某个设备的内存空间之后,就会触发Root Complex将其转换为PCIe的请求,并通过PCIe总线发给对应的设备。
“但是等等,你说物理地址???物理地址不应该就是物理内存的地址吗?”嗯,没错,这里就是物理地址,物理地址空间中不仅仅有物理内存,还有PCIe设备的内存,在访问物理地址的时候,处理器会将请求发给内存控制器,内存控制器会根据总线上各个Root Complex的Host Bridge的配置,将其传递给DRAM或者对应的Root Complex,最终交给对应的PCIe的设备。
然而,系统是如何知道哪些地址的访问需要转换为PCIe的请求,最后又发送给哪些设备呢?这就需要我们来看看PCIe的配置空间了。
2. 设备配置空间
在PCIe中,每个设备都会拥有一块独立的配置空间(Configuuraiton Space),这块空间的大小是4096字节,其中头部和PCI3.0保持兼容,有64个字节,这块空间的大小是固定的,不会随着设备的类型或者系统的重启而改变。
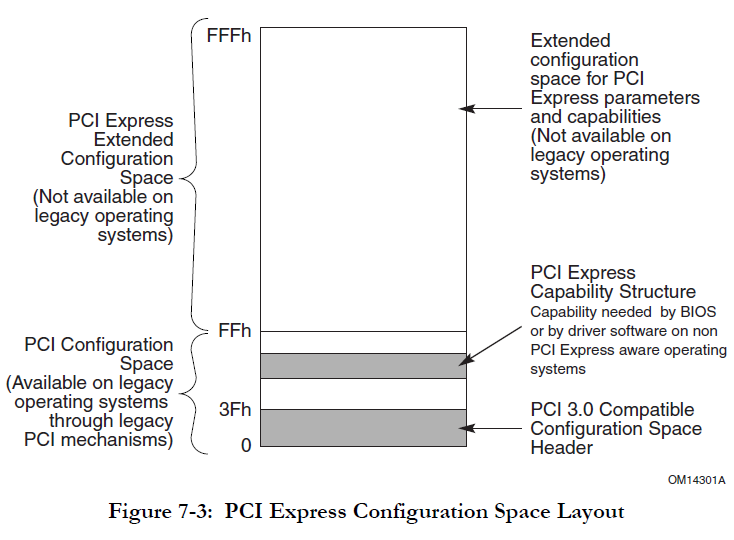
上一章我们提到过,PCIe中有两类设备:Type 0表示终端设备,和Type 1表示Switch。由于职责的不同,其配置空间的内容也不同。但是为了保持一致,方便管理,这两类设备的配置有很多相同的部分,比如配置空间的头部,如下图所示:
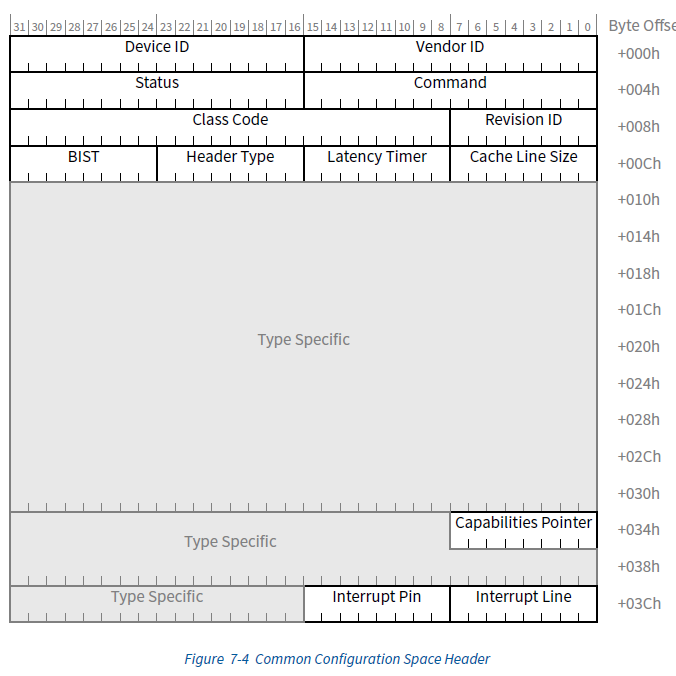
除了我们上面提到的Vector ID和Device ID,这个头部还包含了很多其他的字段。由于太多细节对我们前期理解PCIe并没有太多帮助,我们这里就不一一介绍了,感兴趣小伙伴可以移步PCIe的规范文档7.5.1.1 Type 0/1 Common Configuration Space进行查看 [1]。
3. 配置空间的分配与访问
在系统启动时,BIOS会通过ACPI(Advanced Configuration and Power Interface)找到所有的PCIe设备,并为其分配配置空间,映射到物理地址空间中,然后通过ECAM(Enhanced Configuration Access Mechanism)转交给操作系统。我们通过acpidump对MCFG表进行导出,然后使用iasl就可以查看到ECAM的基址了:
1 | # Dump MCFG table from ACPI as binary file: mcfg.dat |
而为了方便访问,PCIe使用BDF来构造每个配置空间相对于ECAM的偏移。由于每个空间都是4096个字节,所以PCIe将BDF向左移位了12位,对其进行预留。其地址映射关系如下:
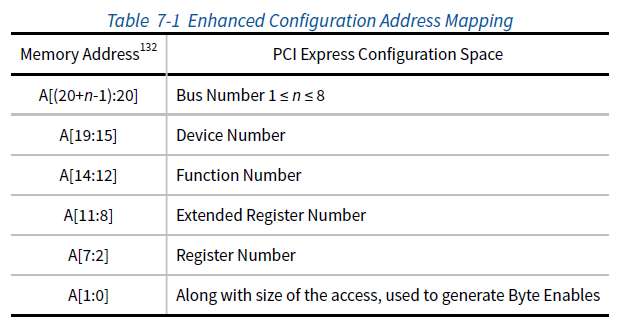
打个比方,如果某个设备的BDF是46:00.1,ECAM基址是0xE0000000,那么其配置空间起始地址就是:0xE0000000 + (0x46 << 20) | (0x00 << 15) | (0x01 << 12) = 0xE46001000。或者简单的记忆就是BDF的Hex后面跟三个0。我们这里也可以通过lspci和/dev/mem进行直接的物理内存访问来验证:
1 | $ lspci -s 46:00.1 -nn |
这段内存的前面几个数字14e4和165f就是这个设备的Vendor ID和Device ID,这和我们通过lspci看到的完全一致:[14e4:165f]。
当然,每次这样进行计算和转换来查看原始的配置空间是非常麻烦的,所以我们可以通过setpci来直接访问:
1 | $ setpci -s 46:00.1 00.w |
使用
setpci的时候需要注意:无论是读取和写入,请务必按照目标字段的长度来进行输入,PCIe的内存地址的IO并不一定是内存的读取,而有可能被转换成PCIe的请求,如果长度不对,则很有可能出现错误。
4. Type 0配置空间
接下来,我们来看看每一类设备的配置空间。由于PCIe上大部分我们使用的设备都是Type 0的终端设备,我们就先从Type 0开始吧!
4.1. Type 0配置空间的结构
Type 0设备的配置空间如下:
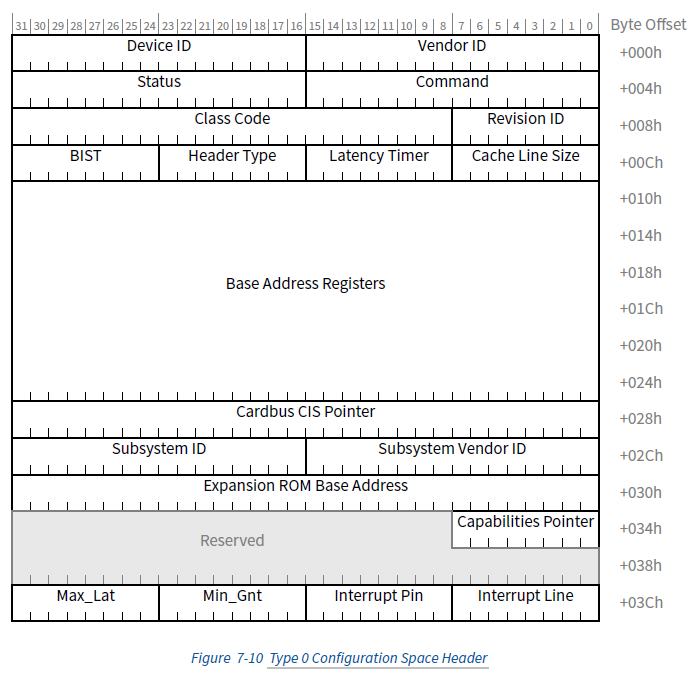
和公共字段相比,Type 0的配置空间多了一些字段:
- Subsystem ID和Subsystem Vendor ID:顾名思义,用来帮助每个设备厂商标识更细粒度设备信息
- Cardbus CIS Pointer Register:已经废弃,以前用于PC-Card中
- Expansion ROM Base Address Register:用于描述设备的ROM的地址,这里和我们的主要内容关系不大,就不过多展开了
4.2. BAR(Base Address Register)
除了上面这些字段,其中最重要的就是BAR了。在Type 0的配置空间中,BAR区域有24个字节,可以保存6个指针/地址,每一个都可以用来描述一个不同的内存空间或者IO空间的地址和范围。
为了描述不同类型的地址空间,这里的指针不是单纯的指针,而有着自己的结构,如下 [1] [3] :
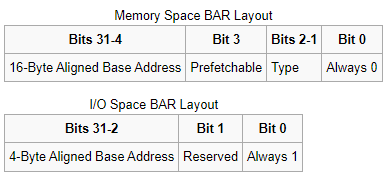
其中:
- 最低位Bit 0:是一个标志位,用于描述地址空间的类型,0表示内存空间,1表示IO空间
- Memory Space中的Bit [2:1] - Type:用于描述内存空间的类型,00表示32位地址空间,10表示64位地址空间
- Memory Space中的Bit 3 - Prefetchable:用于描述内存空间是否支持预取,0表示不支持,1表示支持。如果一段内存空间支持预取,它意味着读取时不会产生任何副作用,所以CPU可以随时将其预取到DRAM中。而如果预取被启用,在读取数据时,内存控制器也会先去DRAM查看是否有缓存。当然,这是一把双刃剑,如果数据本身不支持预取,那么除了可能导致数据不一致,多一次DRAM的查询还会导致速度下降。
另外也许你会觉得很奇怪,一个32位的空间,又是如何又表示地址又表示范围呢?这里其实和BAR的初始化过程有关。BAR的寄存器初始化主要有三步 [1](7.5.1.2.1 Base Address Registers):
- BIOS将全1的地址写入BAR寄存器,这样会导致BAR寄存器的值被重置,并被设备重新写入初始值。这个初始值是一个地址,表示如果将这个BAR寄存器指向的内存放在物理内存的最后,其地址为多少。比如,如果我们需要4KB的内存空间,那么这个地址就是0xFFFFF000,当然这里还需要加上最低几位表示类型的Flag。另外,如何这个空间不可用,那么返回全0。
- BIOS读取BAR寄存器的值,并去除掉最后几位Flag,然后将其取反并加1,求出其大小。比如0xFFFFF000,取反之后就是0x00000FFF,加1之后就是0x00001000,也就是4KB。
- BIOS接着进行真正的地址分配和映射,并将这个新的地址重新写入BAR。这个时候设备没有权利拒绝这个修改,并且也不能再对这个地址进行任何的更改了,不然系统可能会整个崩溃。
在这样的握手之后,我们就通过BAR中这一个地址大小的空间,又表示了地址,又传递了大小了。
对于BAR空间中保存的所有的地址,我们都可以通过lspci来查看到:
1 | $ sudo lspci -s 81:00.0 -nn -vv |
从上面我们可以看到,这块显卡中有4个地址空间,三块是内存空间,一块是I/O空间。Region的编号表示其地址在BAR中间的偏移,比如Region 1就是BAR中的第二个DWORD,Region 3就是BAR中的第4个DWORD(Region 1是64位,所以需要占用8个字节),以此类推。这里我们也可以把原始的物理内存dump出来,进行验证。这里我把不同的地址,用不同的颜色标记了出来:

5. Type 1配置空间与PCIe遍历
接下来我们来看看Type 1设备,也就是Switch,的配置空间。它的配置空间和Type 0配置空间有着很大的不同。虽然我们可以看到它们大小是一样的,但是其中BAR空间和设备信息的字段变成了很多的地址信息,如下 [1]:

这些改动的原因是因为作为Switch,它并不需要也不会实现特定的功能,它的作用就是为PCIe的消息提供路由转发的机制,所以中间所有的字段几乎都变成了和路由转发相关的地址信息。
- Primary Bus Number / Secondary Bus Number / Subordinate Bus Number:用于基于BDF的转发
- Memory Base / Memory Limit:用于基于内存空间地址的转发
- Prefetchable Memory Base (Upper) / Prefetchable Memory Limit (Upper):也是用于基于内存空间地址的转发,不过是Prefetchable的地址
- IO Base / IO Limit:用于基于IO空间地址的转发
然而,说到路由转发,一个很奇怪的问题就出现了:为什么我们没有在配置空间中看到我们网络交换机中的那种复杂的路由表呢?这其实和PCIe如何进行ID和地址的分配有关,这个过程叫做PCIe的遍历(PCIe Enumeration)。我们这里就用下面这张图来说明一下这个过程是如何进行的:
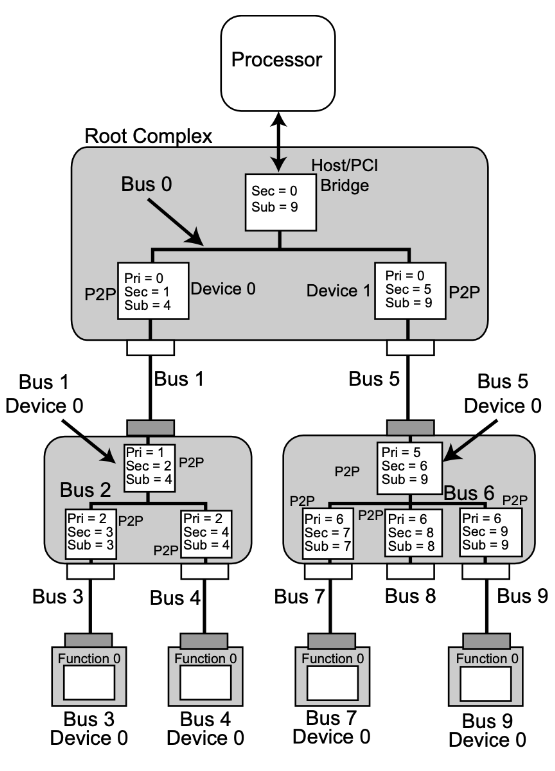
整个PCIe的遍历过程其实是一个简单的DFS和线段树,拿上图的BDF来举例子,每一个Bridge中都保存着三个用于路由的关键信息:
- Primary Bus Number(Pri):这个Bridge所在的Bus Number,也就是它的上游连接的Bus Number
- Secondary Bus Number(Sec):这个Bridge所连接的下一个Bridge的Bus Number
- Subordinate Bus Number(Sub):这个Bridge所连接的下游所有的Bus的最大的Bus Number
这些信息形成了一个递归的结构来帮助我们进行基于BDF进行路由,而PCIe的遍历就是来建立这个递归的结构。我们来看看上图中的遍历过程:
- 首先,我们从Root Complex的Host Bridge出发。Host Bridge略有不同,因为他的上游没有连接任何总线,所以没有Pri,它的下游连接的是Root Complex中的总线,也就是Bus 0,所以我们的遍历从Bus 0开始,此时Host Bridge中的Sec是0。另外,虽然此时Sub未知,但是为了安全,在向下遍历的过程中,我们会把Sub设置为最大值,也就是0xFF,这样即便是出错,我们也不会出现无法路由的情况。
- 然后,我们遍历到了Root Complex中的第一个Bridge,很明显它的Pri是0。由于桥接的原因,它的下游总线的Bus Number要保证唯一,于是我们加1,所以它的Sec是1,同样Sub还是改为0xFF。
- 然后,我们继续递归,到了第一个Switch的Upstream Bridge,因为它所连接的Bus Number是1,所以它的Pri是1,而同理,它的下游会连接到它的内部总线,于是需要把Bus Number再加1,变成2,于是Sec为2。
- 继续递归到第一个Downstream Bridge,同样它的下游的Bus Number需要加一,于是Pri为2,Sec为3。
- 继续递归,到了第一个Endpoint,它的下游没有任何设备,所以开始回溯。
- 回到了步骤4所在的Bridge,此时最大的Bus Number为3,所以Sub更新为3,最后Pri为3,Sec为3,Sub为3。
- 同理,第二个Bridge的Pri为3,Sec为4,Sub为4。
- 然后回到步骤3访问的Bridge,此时最大的Bus Number为4,所以Sub更新为4,最后Pri为1,Sec为2,Sub为4。
- 依次类推,直到所有的设备完成。
等所有的步骤结束,我们就会得到上面这张图中对应的分配了!类似的,内存的空间,IO的地址空间,Prefetchable的地址空间,都会进行类似的遍历和分配,然后把最后合并的区间保存在上游的配置空间中,这样大家应该就理解了为什么配置空间中只需要保存一个区间就可以进行路由了,而不需要保存复杂的路由表了。
另外,PCIe的热插拔其实就是靠在遍历过程中预留更多的Bus Number来实现的,这样就可以在不影响已有设备的情况下,插入新的设备了。
6. 消息路由
现在,有了上面的路由信息,我们就可以很轻松的来对PCIe的消息进行路由了!它其实就是一个非常简单的线段树,我们假设需要将一个消息从CPU发给BDF为04:00.0的设备,那么其路由过程如下:
- 首先,CPU会请求Host Bridge产生消息,然后由于Bus 4在第一个Bridge的Sec和Sub之间,Root Complex会将这个消息通过这个Bridge转发出去。
- 然后继续递归,这个消息将通过Bus 1传递给下游Switch中的连接上游总线的Bridge。而这个Switch会来检查它下游所有Bridge的配置,最后发现Bus 4在它的第二个下游Bridge的Sec和Sub之间,于是这个Switch会将这个消息通过这个Bridge转发出去。
- 消息经过Bus 4到达Function
04:00.0。
7. 配置空间访问流程
为了总结,我们就从CPU出发,用对配置空间的读请求做一个例子,来对整体的流程来一个总结吧!
- 首先,CPU执行内存访问指令来读取虚拟内存中映射的,在ECAM中的,某个配置空间的内容。比如:
mov ax, [0x10e8100000]。 - 然后,这个读请求的地址经过MMU,查询页表得到物理内存的地址。假设,这个物理地址是BDF为
81:00.0的设备的配置空间地址:0xe8100000。 - 这个读请求会被发送给Memory Controller,Memory Controller检查这个地址之后,发现这个地址不属于DRAM,于是转发给对应的PCIE控制器,到Root Complex中。
- Root Complex的Host Bridge收到这个请求,发现这个请求属于设备的配置空间,于是将这个请求转换为一个配置空间的读请求(请求名称叫CfgR0,具体的结构后面会介绍),地址是BDF
81:00.0,Offset是0,长度是2个字节,并利用BDF开始路由。 - Root Complex根据所有连接到其上面的设备和桥的配置空间里的配置,将这个请求转发给对应的设备。如果是设备本身就检查Device Number和Function Number,如果是桥,就检查Secondary Bus Number和Subordinate Bus Number,然后进行递归的转发。
- 最后,请求到达设备。
数据返回的流程和请求的流程非常类似,只不过是从设备出发,返回给CPU,这里就不再赘述了。
8. 总结
好了,这一篇我们把配置空间的结构,分配和访问,都大概总结了一遍,并且还介绍了它们的头部字段和这些字段的意义,包括BAR和消息路由的原理。之后,如果有时间,我们会继续来探索PCIe的数据报文的结构和传输等等。
9. 参考资料
- [1]: PCI Express Base Specification
- [2]: Memory Management Unit
- [3]: OSDev WIKI - PCI
- [4]: White Paper: Introduction to Intel® Architecture
- [5]: Mindshare - An Introduction to PCI Express
原创文章,转载请标明出处:Soul Orbit
本文链接地址:PCIe(二) —— 配置空间