PCIe(四)—— 物理层
在看完事务层和数据链路层之后,我们来继续我们的协议栈之旅吧!这一篇中,我们会来看看PCIe物理层(Physical Layer)是如何工作的,从而帮助我们更加深入的了解PCIe的数据传输。
1. 物理层(Physical Layer)
当数据链路层将上层数据封装好后,就会将其交给物理层进行传输。而物理层的主要目的将数据转换为易于介质传输的电信号,并发送出去,或者将接收到的转换后的信号,转变为上层能处理的数据包。其主要结构如下:
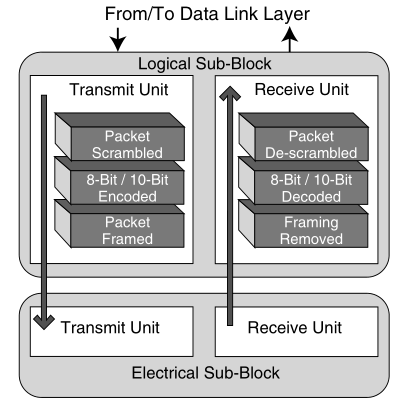
物理层主要分为两个子块:
- 逻辑子块(Logical Sub-Block):逻辑子块负责编码和解码数据,以及处理时钟恢复和同步。它将数据链路层发送过来的数据进行编码后发送到电气子块。在接收方向,逻辑子块将电气子块接收的编码数据进行解码,恢复原始的数据,并送入数据链路层进行后续处理。此外,逻辑子块还处理与时钟恢复和数据流的对齐和同步相关的任务。
- 电气子块(Electrical Sub-Block):电气子块负责实际的数据传输。它将逻辑子块编码的数据转换为电信号,并通过物理链路发送出去。在接收方向,电气子块将接收到的电信号转换回编码数据,并发送给逻辑子块。电气子块还负责处理物理链路的一些特性,如电平调整,差分信号传输,以及其他与物理链路的电气特性相关的任务。
我们这里可以看到,物理层做的事情其实非常的多。如果你和我一样,以前主要做软件的小伙伴,也许会感觉到有些惊讶。不过没有关系,要理解物理层做的事情,关键是理解它们的目的。PCIe的信号特点是:高频和短距,而这些事情都是为了帮助我们稳定的传输这样的信号而设计的,其设计目标主要有:
- DC均衡(DC-Balanced):DC均衡是指在传输的数据中,0和1的数量是相等的。这样做的目的是为了保证信号的稳定传输,因为如果0和1的数量不相等,那么信号的电平就会有一个偏移,这样会导致信号的稳定性变差。
- 稳定的高频传输:避免常见的高频信号传输问题,比如电平上行下行的速度过慢导致信号变形,传输线路问题导致的信号速率抖动(Jitter),连续的相同的bit导致电信号无法正常的通过滤波器,等等。
- 最小化EMI(Electromagnetic Interference):尽量避免高频信号中重复的数据模式产生EMI干扰其他的线路,也要避免其他电磁辐射源对自己的传输线路的干扰,导致信号失真。
这里,我们就来逐个的看看物理层的设计吧!
物理层还会负责一些其他的工作,比如:链路(Link)初始化,传输速率协商(Data Rate Negotiation)等等等等。这些内容由于和我们的主线 —— 数据传输的关系不大,所以我们就不在这里展开了,有兴趣的小伙伴可以自行查阅相关资料。
2. 链路(Link)和通道(Lane)
在了解物理层的具体内容之前,我们先来看看PCIe物理上到底长什么样子,还有它链路(Link)和通道(Lane)的概念。
PCIe的插槽想必大家都不陌生,在主板上都见过,最短的是PCIe x1,很少用到,最长的是PCIe x16,可以用来插显卡,另外其实还有x32的插槽,但是仅仅在大型服务器上才会使用。如下图: [7]

对于一个多通道(Lane)的PCIe设备而言,比如16通道(x16),虽然通道是多个,但是这些通道是连向同一个设备的,所以链路(Link)只有一个。在传输数据时,PCIe会将数据分配给所有通道并行传输,但是每个通道内部的数据传输是串行的,而接收方会将所有通道的数据最后重新汇总在一起,这样就利用了并行的多通道(Lane)建立起了一个串行的通信链路(Link)。
另外,我们知道短的PCIe设备还可以插在长的PCIe插槽中使用,这个扩展的魔法也是来源于PCIe中通道(Lane)的设计。PCIe接口的Pin分为两个部分:公共部分和数据传输通道。前着和后者会有一个小挡板隔开,这个叫做Mechanical Key,一般就简单叫做Key。我们在PCIe接口的Pinout中可以看到它具体的实现: [6]
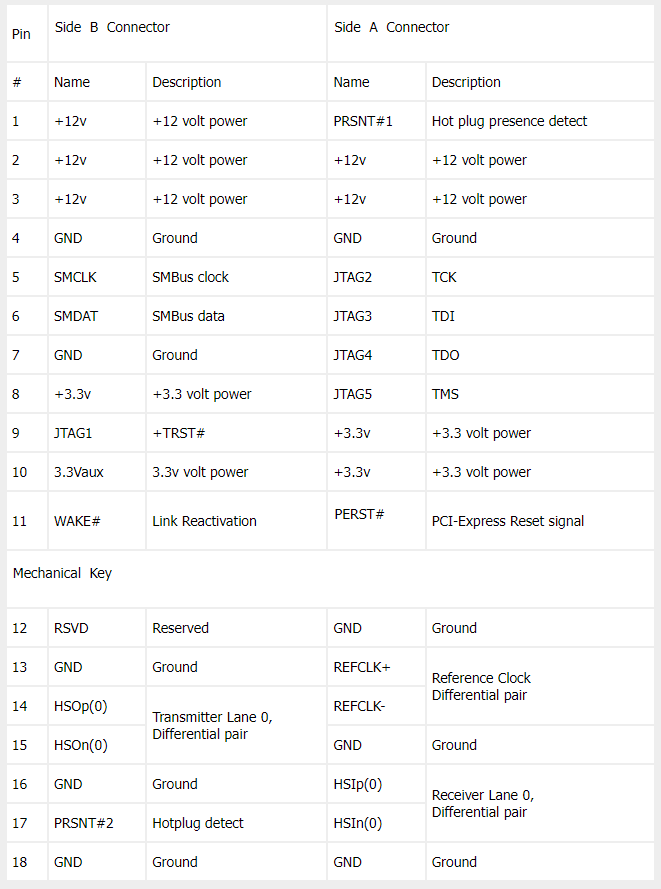
其中,key之前的是公共部分,不管是x1还是x16,都一样。它包括很多功能,比如:大量的12v和3.3v的电压输入和接地,用于避免一根金手指电流过载,JTAG调试接口,SMBus用于设备信息上报,比如传感器,以及WAKE#用于唤醒设备和PREST#用于重置设备等等。
而key之后就是数据通道了,其中包括了接地,时钟,发送通道,接收通道,和热插拔检测引脚。而每个功能引脚两侧都是接地,这样可以帮助我们保持信号干净,减少EMI。而我们x1到x16可以扩展的魔法其实非常简单:x1和x16的区别仅仅在于,x16会把x1的所有的引脚重复16次,仅此而已。这样,物理层通过对通道的检测,就可以用x16的插槽适配比它小的任何设备了。
好了,了解了PCIe的物理接口,我们就可以来看PCIe物理层的具体设计了。
3. 逻辑子块(Logical Sub-Block)
我们还是跟随着数据发送的脚步,来看看物理层的设计。当数据链路层将打包好的数据传下来之后,首先到达的就是逻辑子块(Logical Sub-Block)了,在这里,我们会对数据进行一些处理,比如:打乱(Scrambling),编码(Encoding),以及插入控制字符(Control Character)等等。
3.1. 链路串行化(Link Serializer)
首先,由于一个链路(Link)中可能存在多个通道(Lane),所以我们需要将一个Link中的数据预先分配到多个通道中去。这里,物理层会将数据根据链路(Link)上通道的数量,将数据按字节分配给各个通道,然后再将其转化为串行的Bits,交给之后的逻辑进行处理和发送。
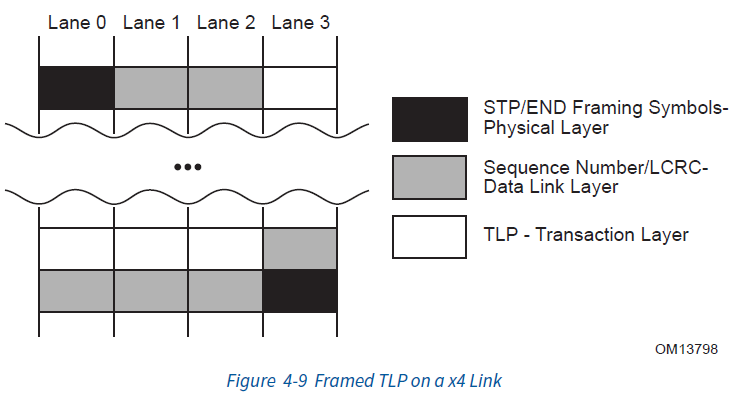
自然的,接收方则相反,当所有的数据处理完成之后,需要将每个通道(Lane)中的数据合并成一个链路(Link)上去,再交给数据链路层进行处理。
3.2. 数据加扰(Data Scrambling)
首先,物理层会将接收到的数据进行加扰(Scrambling),让原本规整的数据流看上去像是随机数一样(所以有时候又把这个称为伪随机数生成:pseudo-random number generator)。
这样做的目的是为了避免信号的能量聚集在某些特殊的频段上,从而减少EMI。原理是这样:我们传输的数据其实是大量高频的0和1,而由于传输的数据可能是类似的,所以会形成特定高频的01变化的模式。了解傅里叶变换的小伙伴知道,任何周期信号都可以表示为一系列成谐波关系的正弦信号的叠加。这样分解之后,这种特定形状的高频信号,就会在特定的频率上产生能量集中的电磁波,导致干扰。而加扰(Scrambling)就是为了避免这种特定形状的信号出现,从而避免这种情况的发生。
而PCIe使用了一种非常聪明的方法进行数据加扰 —— 利用XOR运算!也就是线性反馈移位寄存器(LFSR,Linear-feedback shift register) [8]。其结构如下:
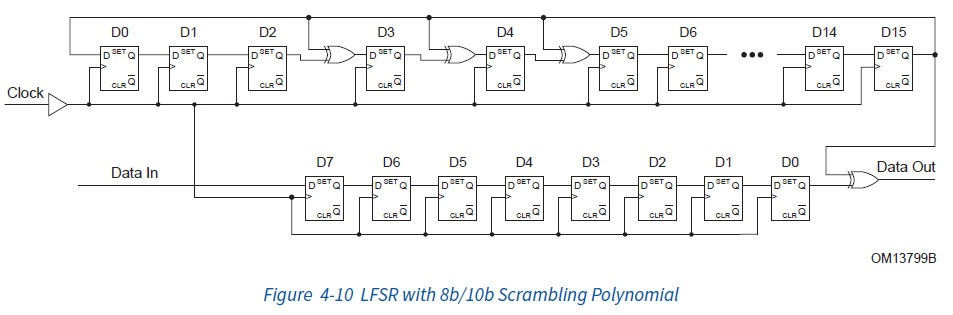
PCIe使用的是伽罗瓦(Galois)式LFSR,其中PCIe 1.0和2.0使用的是16位的LFSR的多项式表达为:
$$ G(X) = X^{16} + X^5 + X^4 + X^3 + 1 $$
而3.0开始之后,使用的是更长的23位LFSR,表达为:
$$ G(X) = X^{23} + X^{21} + X^{16} + X^8 + X^5 + X^2 + 1 $$
其计算方法用动画表示如下:

这样,每一次时钟,LFSR就会产生一个伪随机的bit,然后我们用这个bit和数据再进行一次XOR运算,就可以达到数据加扰的目的了。
另外,PCIe1.0和2.0中,数据加扰用的LFSR的初始值(Seed)都是0xFFFF,但是在PCIe3.0之后,为了避免不同的Lane上出现相似的数据,每条Lane上的LFSR的初始值(Seed)都不一样(大于等于8的Lane ID需要对8取模):
| Lane | Seed |
|---|---|
| 0 | 1DBFBCh |
| 1 | 0607BBh |
| 2 | 1EC760h |
| 3 | 18C0DBh |
| 4 | 010F12h |
| 5 | 19CFC9h |
| 6 | 0277CEh |
| 7 | 1BB807h |
这个方法聪明的地方在于,通过XOR产生的伪随机数是可以恢复的!因为只要操作数一样,两次XOR操作的效果会被抵消,所以只要发送方和接收方的Seed一样,那么接收方就可以通过执行完全一样的LFSR操作,来恢复出原始的数据。
最后,为了方便我们用示波器调试,数据加扰是可以被关闭的。
3.3. Encoding
在打乱数据之后,接下来就是对数据进行编码(Encoding)了。编码的目的是保证传输的0和1的数量尽可能的一致,从而保持DC平衡(DC Balance),让数据的传输更加可靠,也能帮助PCIe从数据信号中恢复时钟(Clock Recovery)。
PCIe使用的编码方式有三种:8b/10b编码,128b/130b编码和242B/256B FLIT编码。而一旦知道了编码方式和PCIe的总线时钟频率,我们就可以算出来每条Lane的传输速率了。用PCIe 1.0 8b/10b来举例子,这个代表8bit的数据会被编码为10b的数据进行传输,所以,最后每条Lane的传输速率就是:
$$ Throughput = \frac{TransferRate \times EffectivePayloadPercentage}{8bits} = \frac{2.5GT/s \times \frac{8bits}{10bits}}{8bits} = 250MB/s $$
以下是PCIe各个版本的编码方式和传输速率:
| PCIe Version | Line code | Transfer rate per lane | Throughput x1 | Throughput x16 |
|---|---|---|---|---|
| 1.0 | 8b/10b | 2.5 GT/s | 250 MB/s | 4 GB/s |
| 2.0 | 8b/10b | 5 GT/s | 500 MB/s | 8 GB/s |
| 3.0 | 128b/130b | 8 GT/s | 984.6 MB/s | 15.75 GB/s |
| 4.0 | 128b/130b | 16 GT/s | 1.969 GB/s | 31.51 GB/s |
| 5.0 | 128b/130b | 32 GT/s | 3.938 GB/s | 63.02 GB/s |
| 6.0 | 1b/1b 242B/256B FLIT | 64 GT/s | 7.564 GB/s | 121.00 GB/s |
注意:242B/256B是大写的B,不再是bit而是Byte了。
3.3.1. 8b/10b编码
8b/10b编码主要用在PCIe 1.0和2.0中,为2.5GT/s和5GT/s的传输频率提供数据编码 [4]。它的核心思想是,将一个8bits的数据拆分成一个5bits的数据和一个3bits的数据,然后分别通过一个固定的关系映射到6bits和4bits的中空间中去,从而避免连续的0或者1的出现。如下:ABCDEFGH被拆分成ABCDE和FGH,然后转换为小端,再分别映射到abcdei和fghj中去。
转换后的8b/10b编码有两种类型的值:控制码(K)和数据码(D),根据数据ABCDE和FGH的分组,被记为D.<ABCDE>.<FGH>或者K.<ABCDE>.<FGH>。其具体的映射方式如下:[4]
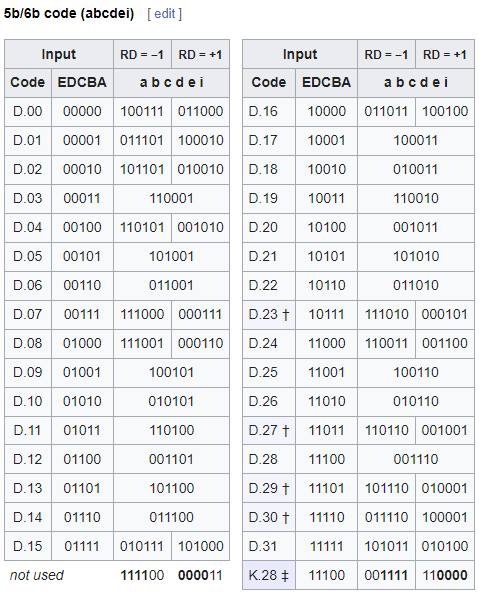
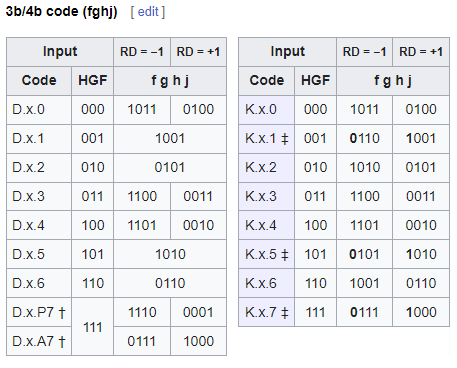
这里**RD(Running Disparity)**代表着当前字节开始前,前面的数据流中1的数量减去0的数量的差值。为了保证精确的01数量一致,8b/10b编码会使用这个值对当前字节的编码进行调整。这样它就能保证在传输每个字节之前,RD的值不会超过$\pm1$,在传输数据过程中,RD的值不会超过$\pm2$。
由于硬编码的原因,8b/10b编码可以精确的01数量一致,从而达到稳定的保持DC平衡,但是它的问题在于编码设计复杂,而且编码的效率有高达20%的浪费!这也是为什么PCIe 3.0之后,就不再使用8b/10b编码的原因。
3.3.2. 128b/130b编码
PCIe 3.0之后,为了提高编码效率从而提升有效带宽,PCIe开始使用128b/130b编码。可以看到由于每130个bits中间,只有2个bits是浪费的,所以它的效率高达98.46%!
128b/130b编码是64b/66b编码的变形 [5],唯一的区别是将其payload的部分扩大了一倍(64b -> 128b)。它和8b/10b最大的不同在于它不再使用硬编码表进行转换了,而是依赖于上面我们提到的3.0之后的LFSR算法来进行转换,从而生成一个统计意义上的DC平衡的数据流。
除了使用LFSR算法进行数据处理以外,在编码的时候,128b/130b编码会做两件事情:Framing和Encoding。
3.3.2.1. Framing
首先,128b/130b编码会将整个上层的包(不是一个block)的之前和之后加上特定的标识用的Token,用来表示这个包的开始:
-
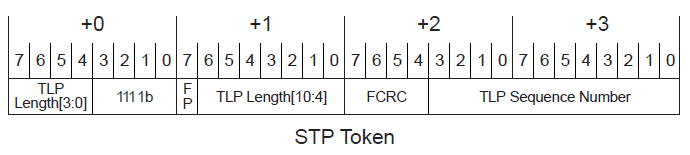
对于TLP而言,它会在前面增加一个2字节的头,并且复写数据链路层的前4个bits,将其修改为FCRC,从而和已有的数据链路层的Seq一起组成一个4字节的token —— STP(Start of TLP)。
-
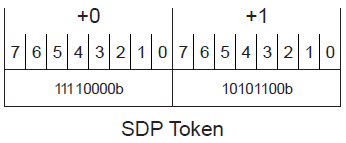
对于DLLP而言,它会用一个2字节的Token - SDP(Start of DLLP)表示开始。
这两个Token会被永远从Lane 0开始,并作为一个数据包的开头(Byte 0)。另外,除此以外,还有用来标记空闲的IDL(Logical Idle),Nullify之前TLP的EDB(EnD Bad),和标记数据流结束的EDS(End of Data Stream)。
3.3.2.2. Encoding
然后,128b/130b编码会将整个数据包分为大小为128bit的block,然后在每个128bits的payload之前,加上一个2bits的同步头(SyncHeader),用来表示这个payload的类型并且做多通道同步。这个同步头的值有两种:
- 01b:表示这个payload是数据块(Data Block),长度为128bits
- 10b:表示这个payload是Ordered Set Block,长度也为128bits
比如,我们假设需要在一个通道上传输一个数据块,总共16个字节,S0-S15,其中最低位的bit我们记作.0,最高位记作.7,那么传输序列如下(注意同步头也会被转位小端发送,所以01b会变成10b):
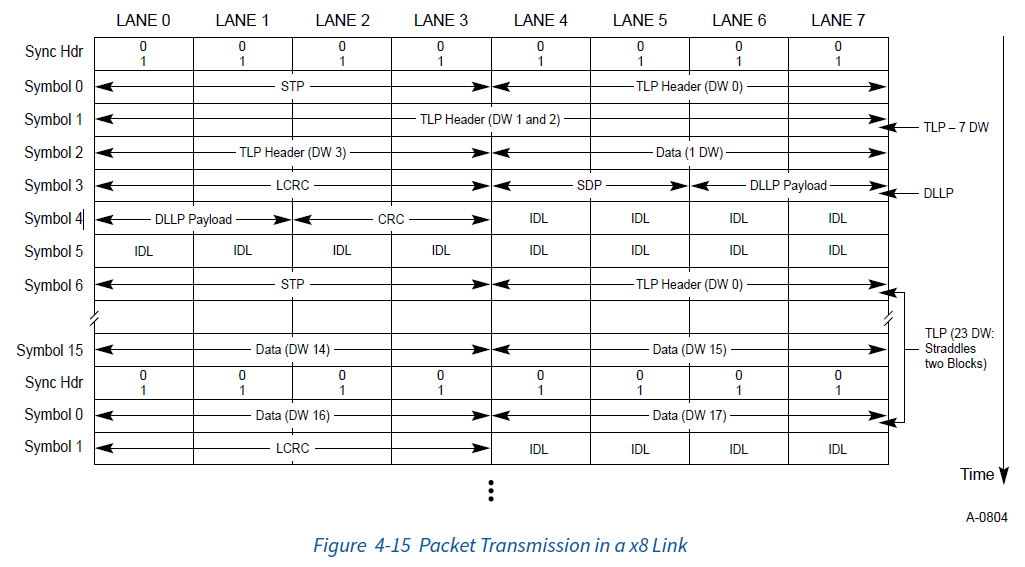
当有多条通道的时候,发送的时候数据将被分配到多个通道上同时发送,并且时钟对齐的:
这里有一个8通道上传输TLP和DLLP的例子,最后的传输效果如下:
3.3.3. 242B/256B FLIT编码
虽然128b/130b的编码很好,但是随着对速率的要求变得更高,PCIe6.0更换了从PCIe1.0一致沿用下来的NRZ(Non-Return-To-Zero)信号调制方式,而是转而使用了PAM4(Pulse Amplitude Modulation 4)信号调制方式。这种调制方式可以在同样的信号频率下,提供双倍的传输速率(下面会详细说)。然而这样的调制方式,也让错误率变得更高,所以PCIe6.0开始,PCIe使用了242B/256B FLIT编码,加入更多的校验机制,来提高信号的可靠性。
242B/256B FLIT编码的传输单位是一个FLIT,大小为256个字节(不是bits)。结构如下:
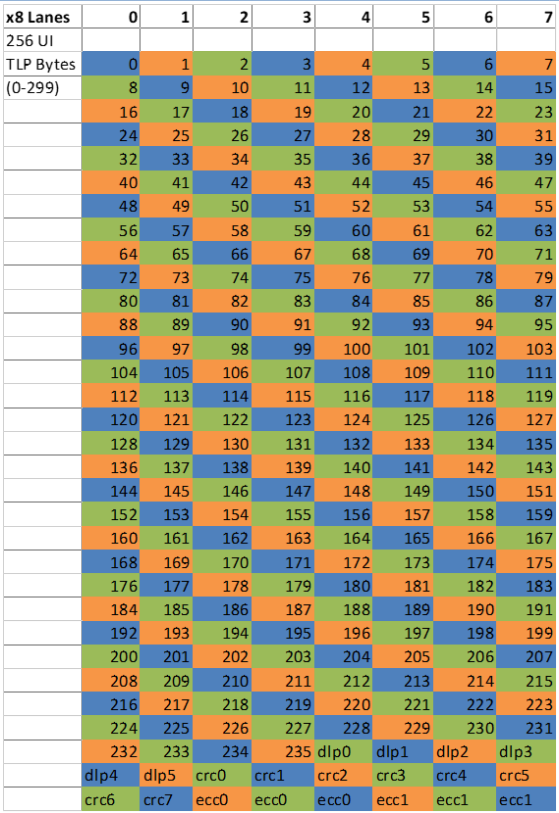
其中没有包头,从报文开始,前236个字节是TLP数据,然后是6个字节的DLLP(Data Link Layer Packet),8个字节的CRC,最后是6个字节的FEC(Forward Error Correction)。由于FLIT中已经带有CRC了,所以DLLP和TLP中是没有CRC的。传输后如果发现问题,就会尝试使用FEC进行修正(单字节),如果不行,就会对整个FLIT进行重传。
另外,一旦开启了FLIT模式,PCIe就会一直使用FLIT模式,即使速率降低到NRZ的速率(比如2.5 GT/s,5.0 GT/s,8.0 GT/s,16.0 GT/s,32.0 GT/s)也不会转换回NRZ模式了。
4. 电气子块(Electrical Sub-block)
到这里,我们的数据就可以发给下一个模块,进行真正的电信号传输准备了,这个模块就是电气子块(Electrical Sub-block)。
4.1. 并行转串行(P2S,Parallel to Serial)
首先,由于我们最后的信号是串行的,而逻辑子块上传下来的数据是是一个一个的字节(单通道),所以需要将按字节的并行信号转变为最后的串行信号(Parallel to Serial),再进行发送。
自然的,接收方则相反,最后当所有的数据处理完成之后,需要将串行的数据重新转化为并行的数据,交给数据链路层进行处理。
4.2. 调制(Modulation)
接下来转换为串行的数据需要经过调制,将其变为易于传输的电信号,而接收方则需要将电信号重新解调,转换会数字信号。
4.2.1. NRZ编码(Non-Return-to-Zero)
在PCIe1.0到5.0中,PCIe一直使用的调制方法叫做不归零码(NRZ,Non-Return-to-Zero) [10]。这种调制方式特点是与归零码(RZ,Return-to-Zero)相比,它的每个比特1会占满整个时钟周期,不会在后半个周期归零。PCIe使用的是中的两极不归零码(Bipolar NRZ level),它的编码方法很简单,就是将0变为负电平$-V$,1变为正电平$+V$,其电平图和眼图如下:
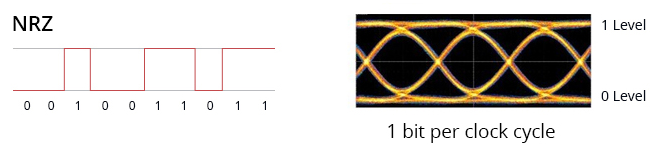
由于不归零码本身没有稳定的机制传递时钟,所以需要上面提到的编码(Encoding),加扰(Scrambling)和其他方式来进行辅助时钟恢复,这个我们下面会提到。
4.2.2. PAM4编码
为了支持更高的传输速率,PCIe6.0开始使用PAM4(Pulse Amplitude Modulation 4)调制方式,即脉冲幅度调制,将00变为$-V$,10变为$+V$,01变为$-V/3$,11变为$+V/3$,其眼图与每个电平表示的信号如下:
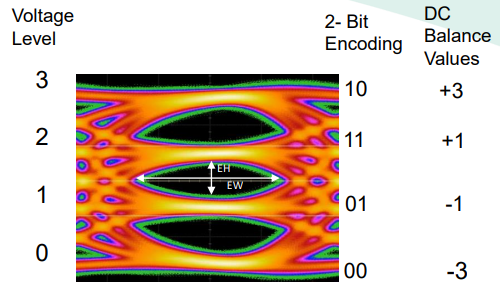
这样在同样的电压下,容纳的状态就变成了之前的两倍,所以在同样的时钟下,传输速率也就变成了之前的两倍!但是这样也就导致了更高概率的误码。
4.3. 预加重(Pre-emphasis)
接着,为了对抗传输介质导致的信号问题,为了能更清晰的传递高频的信号,经过调制的信号,将会经过预加重(Pre-emphasis)处理。即在发送端,对高频信号中的产生变化的第一个信号进行加强,从而让信号能更快的产生变化,保证高频信号的稳定。具体的操作很直观,如下图:[11]
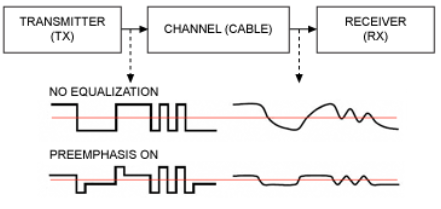
当然,为了避免预加重导致的信号变形,在接收方也要进行去加重(De-emphasis)。
4.4. 差分信号(Differential Signal)
再接下来,再最后发送给真正的电路前,为了对抗电磁辐射等等原因导致的干扰,PCIe使用了差分信号(Differential Signaling)的方式进行传输。即将信号分为正负两个信号,然后在接收端,将两个信号相减,重新得到原始信号(这就是在Pinout中,我们看到的Differential Pair)。
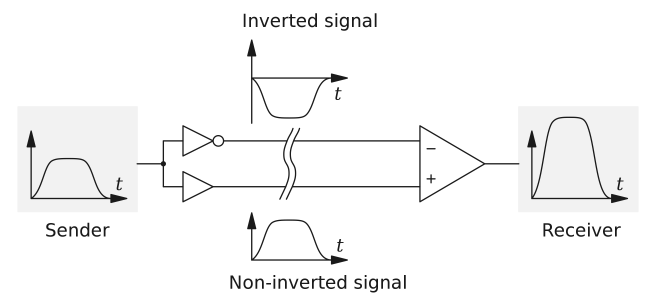
我们假设原始信号中的电压为$V_{Tx}$,经过差分处理的两路信号为$+\frac{V_{Tx}}{2}$和$-\frac{V_{Tx}}{2}$,干扰导致的电压变化为$\Delta{V_{noise}}$,那么忽略传输的损耗,在接收端收到的电压就是:
$$ V_{Rx} = (+\frac{V_{Tx}}{2} + \Delta{V_{noise}}) - (-\frac{V_{Tx}}{2} + \Delta{V_{noise}}) = V_{Tx} $$
这样,通过差分信号,我们就抵消了信道上的干扰。
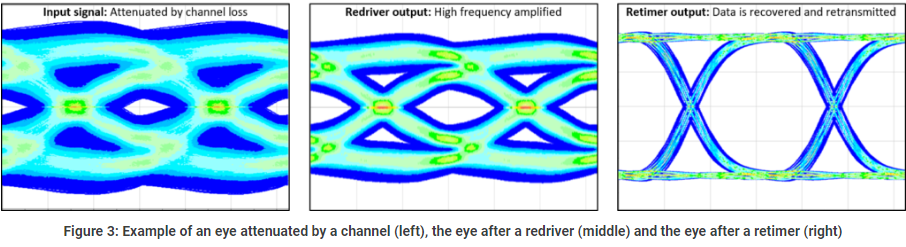
4.5. 时钟和信号恢复
除了上面的功能之外,在接收方,想获得干净的信号,我们还需要做两件事情:
-
时钟恢复(Clock Recovery):虽然PCIe的数据通道Pinout中是可以看到时钟信号REFCLK的,但是这个时钟信号传递的时钟仅仅是一个基础频率,一般在100MHz,而数据发送的频率从PCIe 1.0就已经达到了2.5GHz了,所以PCIe的接收方需要将REFCLK的时钟和数据中的01变化结合,将真正的时钟信号恢复出来。这也是为什么PCIe的数据需要进行编码的另一个原因之一 —— 用稳定的01变化帮助我们恢复稳定的时钟。
-
Retimer:由于PCIe的信号传输可能会有很多的干扰,导致信号的抖动(Jitter),所以在接收方,为了避免抖动的产生,我们还需要加入Retimer,对信号进行重新整形,保证信号的稳定。[13]
5. 物理层小结
好的,到这里,物理层里面和数据传输相关的内容就基本总结完了。我们可以看到,当数据链路层发过来一个包,物理层需要经过相当多的步骤才会将其真正发到外部电路中去,以保证其信号的稳定。
当然,物理层里面还有一些其他的功能,比如启动时对链路的初始化,使用Ordered Set对速率的自适应,Lane-to-Lane deskew等等,但是这些功能和我们的数据传输不是直接相关的,我们这里就跳过了,有兴趣的小伙伴可以去查阅PCIe的规范文档,里面有很详细的描述。[1]
这里,我们也把PCIe各个版本的主要参数再次总结一下,方便大家查阅:
| PCIe Version | Modulation | Line code | Transfer rate per lane | Throughput x1 | Throughput x16 |
|---|---|---|---|---|---|
| 1.0 | NRZ | 8b/10b | 2.5 GT/s | 250 MB/s | 4 GB/s |
| 2.0 | NRZ | 8b/10b | 5 GT/s | 500 MB/s | 8 GB/s |
| 3.0 | NRZ | 128b/130b | 8 GT/s | 984.6 MB/s | 15.75 GB/s |
| 4.0 | NRZ | 128b/130b | 16 GT/s | 1.969 GB/s | 31.51 GB/s |
| 5.0 | NRZ | 128b/130b | 32 GT/s | 3.938 GB/s | 63.02 GB/s |
| 6.0 | PAM-4 | 1b/1b 242B/256B FLIT | 64 GT/s / 32 GBd | 7.564 GB/s | 121.00 GB/s |
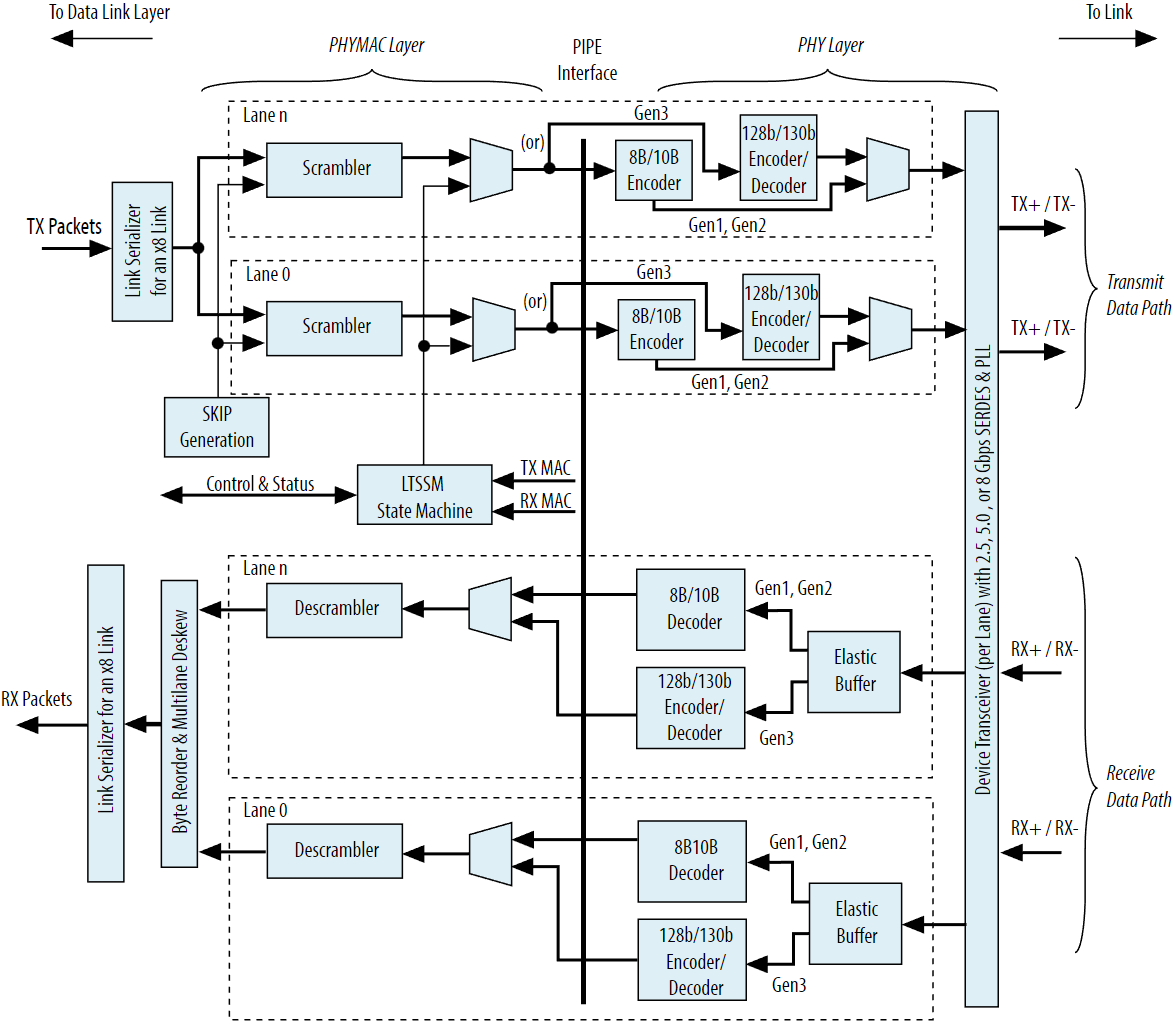
最后,我们依然用Intel Cyclone 10的物理层架构图作为最后的总结,大家可以对照着上面我们提到的各个子模块的内容来服用,如下:[9]
6. 小结
好的,到这里我们已经看完了整个PCIe的协议栈,相信大家已经对其有了一定的了解。最后,我们来举一个栗子,将整个协议栈串起来,看看一个PCIe的请求到底是怎么被发送的吧!
我们这里依然使用一个内存事务(Memory Transaction)来举例子:
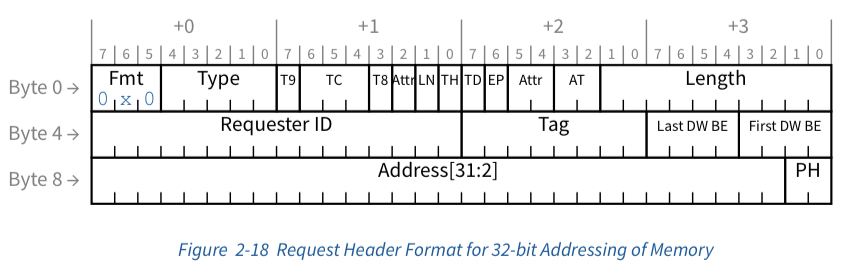
- 首先,CPU发起一个内存读请求,需要读取4字节内存
- 内存控制器收到该请求后发现其不在DRAM空间中,于是转交给PCIe Root Complex
- Root Complex检查其主桥(Host Bridge)配置空间的信息,确认地址在其连接的设备的内存空间内,开始创建数据包
- Root Complex使用其地址构造读内存的内存事务的TLP,长度3DW,设置好各个字段:Fmt = 0,Type = 0,RequesterID = 0(表示Root Complex),和Length = 1(单位为DW),另外,根据规则设置好TC用于流控,我们这里使用默认值0
- TLP构造完毕后会将TC(Traffic Class)映射到VC(Virtual Channel),从根据数据链路层中上报上来的每个VC中每种TLP的信用额度,进行流控,如果没有问题,则会将事务层发送给数据链路层
- 数据链路层收到TLP后,会为其分配一个唯一的12bits的序列号,然后加上一个2字节的包含该序列号的报头,然后计算包括新报头和TLP报文的4字节CRC,将其放在包尾,交给物理层处理
- 现在进入物理层的逻辑子块(Logical Sub-block),如果需要,物理层会其进行再次封包(framing),在报文前加上两字节STP token,并再次计算FCRC,将其写入数据链路层发来的包的第一个字节的高四位
- 然后,物理层根据链路的通道数量进行链路序列化,假设我们这里的链路使用8通道进行传输,那么这个请求将会平均分配给这8个通道。到这里我们的包一共20个字节,所以前4个通道会分配3字节,后4个通道会被分配2字节
- 接着,物理层会开始使用LFSR进行数据加扰,让数据看上去像是一堆随机数,用于保证最后链路中的DC平衡
- 然后,物理层会对每个通道上的数据进行编码(Encoding),这里根据PCIe版本的不同,会使用不同的编码,比如:8b/10b,128b/130b和242B/256B编码,对于空闲的区域,需要补齐的话,也会使用IDL token进行补齐
- 现在,我们来到了物理层的电气子块(Electrical Sub-block),首先,电气子块会讲每个通道发来的字节流转换为比特流,这一步叫做并行转串行(P2S)
- 然后,电子子块会对每个bit进行调制,根据PCIe版本的不同,可以选择NRZ或者PAM4的调制方法
- 然后,电气子块会对信号进行预加重(Pre-emphasis),以保证高频信号能很好的被传输线路传输
- 最后,发送给传输线路之前,PCIe还会将其变换为差分信号,以避免外部线路中的干扰
这样,我们的PCIe请求就被转化为最后的电信号啦!接收方的处理流程也非常类似,将所有步骤反过来即可,不过在最开始物理层将查分信号合并之后,PCIe会有两步额外的操作:
- 恢复时钟:PCIe根据REFCLK的基础时钟和数据中的01变换对数据的时钟进行恢复,以保证数据的正确读取
- Retimer:如果传输线路导致了电信号发生时间上的jitter,retimer可以帮助去除这些jitter,以恢复干净的信号
这样,整个roundtrip我们就都跑通啦!所以到这里,协议栈就算是基本结束啦。下次有时间,我们再来继续看看PCIe所支持的各个事务都长什么样子,如何工作,以及它们是如何进行路由的吧!
7. 感谢
- 感谢元宇宙大老鼠 @Dalaoshu4大佬的指正,修正了数据加扰的中文翻译和NRZ的翻译和定义。
8. 参考资料
- [1]: PCI Express Base Specification
- [2]: OSDev WIKI - PCI
- [3]: Mindshare - An Introduction to PCI Express
- [4]: 8b/10b encoding
- [5]: 64b/66b encoding
- [6]: PCI Express Pinout
- [7]: Use connect PCIe slot
- [8]: Linear-feedback shift register
- [9]: Intel® Arria® 10 or Intel® Cyclone® 10 GX Avalon® Memory-Mapped (Avalon-MM) DMA Interface for PCI Express* Solutions User Guide
- [10]: NRZ
- [11]: An Introduction to Preemphasis and Equalization in Maxim GMSL SerDes Devices
- [12]: PCI Express® Electrical Basics
- [13]: PCI Express® Retimers vs. Redrivers: An Eye-Popping Difference
原创文章,转载请标明出处:Soul Orbit
本文链接地址:PCIe(四)—— 物理层