测试,你写代码时最好的朋友(下篇)
我们终于来到了这个系列的最后一篇,在上一篇中,我们讨论了如何写出好的测试,如何利用数据驱动测试来降低测试的维护成本,提高程序和测试的可观察性,并且提高错误调试的速度。希望到了现在,你会开始觉得数据驱动测试相当方便,并跃跃欲试的想在自己的项目里面进行实践。
不过,如果我们仅仅到此为止,那就真的太浪费了。我们还只刚刚解锁了它的一半威力而已!我们这一篇就来讨论以下它的进阶版本,我称其为面向数据的测试,并且利用它做到线下测试即线上测试,从而实现测试的大统一!
1. 数据驱动测试(DDT)
首先,我们先来快速回顾一下数据驱动测试吧!
数据驱动测试,顾名思义,其特点就是将被测试程序的输入通过数据的方式进行存储,并在测试时依次循环执行,最后将被测试程序的输出与预先设置好的期望结果进行对比,从而达到测试的目的,流程大致如下:

使用数据驱动测试,优点就是使用方便,并且可以有效的降低代码量,但是其缺点也很明显:
- 测试数据庞大,维护复杂,但是我们在第二篇也通过生成基线的方式解决了该问题。通过这种方式,可以极大的减少人员成本。
- 随着测试的量越来越大,我们的测试数据集也会越来越大,特别是在大模块和服务的E2E的测试中,场景的状态会产生组合爆炸的问题,最终导致了一个新的问题:维护测试数据集的成本越来越高。
- 数据驱动测试对随机测试(fuzz test)不是非常友好,因为我们没有这些随机数据对应的参照结果,所以一般最后都只尝试捕获类似于崩溃这种的重大问题,而不能对具体的业务逻辑进行测试。
所以,这些问题有没有什么办法解决呢?
2. 测试即知识
另外我们再回头看看一个本质的问题:测试到底是什么?
在第一篇中,我们提到测试是强制的文档,而我们分离了测试数据之后,你会发现一件很直观的事情:测试的输入和输出变成了一个有强约束性的文档,它用一种统一的可读可维护的方式规定了在我们程序接受了某种输入的情况会产生怎样的输出,对系统造成什么样的影响。
比如,Go的example test就是一种非常接近的尝试,它通过在测试的结尾使用comment来描述输出,从而使测试文档化。
1 | func ExampleReverse() { |
我们如果回头看看第二篇中我们抽取出的测试数据,就会发现这和Go的做法异曲同工,唯一不同的是由于没有语言的支持,这个数据我们只好将其放在其他的文件里面。
而这个有着强约束力的文档,不正是我们的知识库么?而它也是接下来我们要做的一切事情的根基。
3. 面向数据的测试
现在我们就可以换个角度看待我们的测试了,既然在大模块和服务级别的测试中,状态会产生组合爆炸,那为什么不利用我们的知识库,结合我们的业务特点,总结出一套数据的规则,然后再利用这个规则对我们的程序进行测试呢?规则本身是无状态的,所以我们可以对其进行复用,这样不就解决场景组合爆炸的问题了吗?所以现在是时候引入面向数据的测试了!
为了实现面向数据的测试,我们需要做两件事情:
- 我们需要可以拿到被测试程序在任意时间的数据切片;
- 在数据驱动开发之上,引入基于规则的测试器,帮助我们解决状态组合爆炸的问题;
3.1. 数据切片与面向数据编程(DOP)
首先,我们来看看数据切片。这里我们还是拿在中篇中我们提到过的服务测试做例子,我们从其中抽取出来的测试状态如下:
1 | struct StatesToTest |
其展开后的状态用json表示如下:
1 | { |
在这个例子中,我们的数据切片包含了在这个时间点下当前服务的内部状态和其发给下游服务的状态,当然对于不同的情况我们可以对其进行一些改变,如:
- 我们的服务内部数据如果存在分片,那么我们可以只返回一个分片的内容。比如,针对用户数据的业务处理,只要不存在跨用户的数据处理,我们可以返回某特定用户的数据,而不是该服务中所有用户的数据。
- 我们同样可以保存当前最近一次处理过的上游服务发过来的原始请求的状态或者其他内部状态来进行更丰富的测试。
这也和现在很多微服务的设计思路不谋而合,比如,DDIA第六章数据分区中提到的请求路由,和微服务设计这本书中提到的服务即状态机,都是在某种程度上通过设计数据分片来设计最终的服务。
所以,这里我们可以借用面向数据编程的思想,将数据看作程序的第一公民来对待,并且在设计服务的初期就对服务和状态发现进行支持,这样,我们就可以非常方便的获取到我们需要的数据切片了。
3.2. 基于规则的测试器
接下来,我们来看看第二点:基于规则的测试器。
3.2.1. 总结规则,编写测试器
现在,我们拿到了数据切片,而我们主要的测试内容有两个:
- 判断传递给下游服务中的Foo和Bar是否和当前服务内部中的Foo和Bar相等
- TrackedStats中记录的请求数要等和发给下游服务的请求数一致
所以我们可以针对其抽取出三条规则,写成代码如下,非常简单:
1 | void MyDownstreamService1RequestShouldMatchServiceInternalState(_In_ const StatesToTest& state) { |
3.2.2. 测试测试器
好了,现在虽然我们已经有了一些测试器,但是我们怎么知道他们工作的是否正常呢?别忘了我们已经积累好了一个庞大的知识库,所以只要将其代入之前的测试中就可以啦,代码看起来就是这样:
1 | TEST_METHOD(MyService_WhenReceivingValidRequest_DownstreamServicesShouldBeProgrammed) |
这里也许你会好奇,这个和最开始我们的测试逐个数据写assert有什么区别呢?不也是写一堆assert么?这里其实有几个本质的区别:
- 至此,我们被测试的代码已经经过了一大轮的重构,并具备了获取数据切片的能力,而我们的所有测试都是基于一个完整的数据切片来完成的。
- 我们的测试是基于规则的,它只会去测试数据与数据之间的关系,而绝对不会去测试某个数据等于某个绝对值,比如0或者1,这样就避免的状态组合爆炸的问题。
- 我们需要测试的场景是多种多样的,但是规则是无状态的,而且大量的规则都是可以复用的,这样可以减少我们的测试代码量。
也许这些听着依然差别不大,所以下一节我们就来看看这些基于规则的测试器都能帮我们做些什么吧!
3.2.3. 程序逻辑本身也是规则测试器
另外,当我们将代码重构到了这一步,各种测试都能被通过测试数据稳定的复现的时候,其实我们会发现,我们需要测试的程序本身已经是一个很好的测试器了,所以虽然听起来有点荒谬,但是我们确实可以通过简单的对比新老版本代码的行为(数据切片)来达到测试的目的。
不过我们觉得荒谬也是有原因的,其主要问题就在于,这个说到底还是在用自己证明自己:
- 由于测试用的基线数据都是自动生成的,将程序本身作为规则测试器会比较容易因为粗心或者代码审查不严格而引入新的问题,所以这里更好的做法还是总结一套真正的规则进行测试。
- 对于预料之外,程序本身没有处理到的情况,我们的测试也覆盖不到。
所以最好还是自己提炼出真正的规则来,用以测试吧!
3.2.4. 使用测试器
3.2.4.1. 线下测试即线上测试
也许大家都经历过线上系统中一些老旧过时的状态导致各种线上事故频发的情况,特别是新服务升级,一些以前没有清理干净的状态就很容易导致问题,如果有一种方法能对所有的线上服务的状态进行测试就好了,而这正是基于规则的测试器大显身手的地方之一!
由于所有的测试器都是无状态的,仅仅和其输入有关,而且测试的是输入和输出的关联性,所以我们不仅仅可以用这些规则来做本地的测试,还可以对我们线上的服务进行不间断的在线测试,用以发现预料之外的情况发生。其流程也非常简单:
- 服务发现:找到我们系统中的所有服务并对每一个服务依次进行步骤2:
- 数据发现:找到我们系统中的所有数据,比如,如果是用户管理的服务,那就是每个用户的数据,如果是某个特定业务的服务,那就获取其对应的分片数据,然后获取其在特定时刻相关的数据切片,并对每一个切片进行步骤3:
- 测试发现:找到这个数据切片相关的所有测试,比如,如果是用户数据,那么我们可能可以找到这些测试:
UserPasswordShouldBeEncrypted,UserEmailShouldBeValid,UserAgeShouldBeValid,等等。 - 测试执行:执行每个被发现的测试,并对其结果进行统计和上报。上报的内容至少需要包括,数据的id,数据的位置(原服务的信息),测试的名称,及其结果和具体的失败原因。如果可能,最好还能包括数据的具体内容,毕竟有些错误可能是短时的,过几分钟就消失了,而有了数据内容我们就能很容易的在本地进行重现。
为了执行线上测试,我们如果使用actor model控制每个数据分片,可以让每个actor自己在timer中执行。如果担心数据量过大导致占用服务资源太多,我们也写一个独立的测试服务,对所有的测试进行执行和调度,避免资源浪费。
一旦拥有了这个测试服务,我们做任何新的功能,都可以先将前置条件添加到相关的测试器中进行发布,确认了全网都没有任何问题之后再进行最终的服务发布,这样就可以大大降低服务发布的风险!
3.2.4.2. 抽象测试器
线上测试听上去非常的棒,但是中间我们会遇到一个小问题,那就是测试发现。如果和之前的代码一样都是一个一个的函数,可能管理起来会比较复杂。所以我们能可以对其进行一个小小的抽象,提取一个公共的基类,并且增加一个工厂方法以支持测试发现,如下:
1 | class Validator { |
当然,如果语言支持更高级的特性,我们可以将其进一步简化,如:python中的decorator,或者c#或java中的attribute,抑或是rust中的宏。但是基本思想是类似的。
3.2.4.3. 随机测试(Fuzz Test)和形式化证明
我们上面提到过,数据驱动测试对随机测试并不是很友好,因为我们没有任何先验数据进行参照,但是使用了规则测试器之后,我们便可以非常轻松的对随机的输入进行测试了。
另一方面,由于支持对任意的输入进行测试,我们还获得了对代码进行形式化证明的能力,并让形式化证明的系统为我们生成错误的测试用例,帮助我们查找系统中的问题。

3.3. 面向数据的测试总结
由于这是这个系列的最后一篇,所以我们来混着前面两篇的内容一起总结面向数据测试吧:
- 首先,写任何代码,不管大小,我们都要设计好接口和代码分界,然后针对代码分界进行测试,这样既保证了测试的完备,也能给代码重构留下一定的空间;
- 然后,对于小的模块和函数,我们可以应用数据驱动测试,将输入和输出分离出来成测试数据,保存成可读的文件格式,并将程序中会导致不稳定的代码进行分离和固定,做到稳定的测试和问题复现;
- 测试数据需要和代码一起提交以反映代码对系统带来的所有变化,而在程序逻辑变化之后,如果需要更新测试数据,我们可以利用新的程序重新生成测试数据,并将其作为新的基线;
- 测试时,我们不应该将代码覆盖率作为目标,而应该从数据和业务的角度考虑,将场景覆盖率作为最终的目标;
- 对于大模块和服务的设计,如果是管理数据的服务,我们应该从数据分片的角度出发对服务进行设计,将数据本身作为头等公民之一,并对服务和数据发现做好支持,并依次为依托进行测试;
- 在测试大模块和服务时,我们可以通过提炼规则测试器来避免数据驱动测试中状态组合爆炸的问题;
- 最后,我们还可以利用面向数据测试做到对随机测试和形式化证明的支持;
这里,我们也再来一张图,对面向数据测试进行一个归纳:
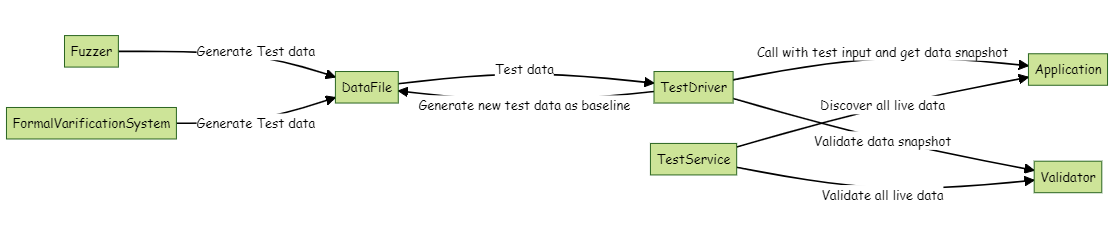
4. 工欲善其事,必先利其器
最后,好的测试的辅助工具能让我们事半功倍。对于任何一个稍稍成熟一点的项目来说,好的工具都是必不可少的。
4.1. 日志(Log)与日志查看器(Log Viewer)
调试测试时,除了调试器以外,日志便是我们最好的帮手,特别是当调试多线程问题的时候,使用调试器调试经常会变得非常的困难。但是日志也有它自己的问题,就是量太大,很难抓住重点,所以我们需要一个好的日志查看器来帮助我们调试。
一个好的日志查看器,除了能进行日志查询和分级以外,最好还需要具备如下功能:
#1: 支持对任意字段的过滤,并至少能支持"or"和"and"语义
关于procmon,Mark Russinovich有一个非常有意思的talk,大家有兴趣可以去围观:Building 25+ years of SysInternals: Exploring ZoomIt | BRK200H。
#2: 支持日志高亮
#3: 支持场景(Scenario)分析
这个是为了帮助我们快速定位只和我们有关的日志。
- 每个场景都有一个开头事件和一个结尾事件,我们可以通过一定的方法将其关联起来,比如线程ID,模块名,日志中解析出来的元数据等等。
- 场景的支持能大大提高我们分析日志的速度,因为我们只需要查看和我们场景相关的日志即可。
支持场景分析的日志有很多,比如:
- OpenTelemetry中的span,通过它我们可以将操作记录成树的形式,然后在其他的工具中方便的查看,从而帮助我们了解和分析系统中的热点,比如jaeger。
- Windows Performance Analyzer(WPA)中的Region of Interest也是一个很好的例子。
当然让日志查看器变好用的方法还有很多,比如对服务端或离线日志的支持(下载相关日志本地二次查询以加快速度),对产品本身的理解和支持(比如显示服务部署位置,高亮关键场景,显示场景树用来关联相关场景和日志等等)。这里就不一一列举了,大家可以根据自己产品的需要来实现或选择合适的日志查看器。
4.2. 测试历史数据
我们都肯定遇到过一些不稳定的测试,不知道他们什么时候就会出错,很难重现。其中可能是上面提到的不稳定因素造成的,也有可能是不稳定的测试环境造成的。其中性能测试就是一个重灾区。性能测试的结果会受很多因素的影响,哪怕是在同一台机器上,比如系统繁忙程度,热启动冷启动,随机的GC等等等等。我们很多时候都不知道某一次速度慢是不是真正的问题。所以为了避免这些因素的影响,我们除了要运行多次测试看均值以外,收集每次测试的历史数据也是非常有帮助的。
这是Azure Pipeline中的对测试历史数据的支持:Test trends with historical data。我们不仅能看见每个测试是否出错,还能看这些测试每次花了多久,从趋势上判断是不是性能变差了。
4.3. 快捷命令
最后,我们还可以在代码库中加入各种快捷命令,帮助我们更快的进行调试。以下列举一些我们现在项目中的常用命令作为栗子:
ut-log: 使用日志查看器打开最近一次执行的测试的日志。ut-d: 使用windbg加载指定的测试,加载多进程调试设置和异常捕获设置,并运行测试。这样是为了方便调试在Visual Studio很难调试的错误,比如,栈和堆的错误等等。slv <log-path>: 使用日志查看器打开指定的日志
5. 总结
到此,我们最后来总结一下吧:
- 首先,我们讨论了传统的数据驱动开发和它的局限性;
- 接下来,我们重新审视了测试的意义,并且将我们分离出来的测试数据看作我们的知识库来辅助我们的开发;
- 然后,我们讨论了面向数据开发的方法,用以克服传统数据驱动开发的局限性;
- 最后,我们还简单的讨论了一下用于支持测试的工具,如:日志和一个好的日志查看器的标准,如何收集历史数据并帮助我们观察测试走向和应对不稳定的测试;如何通过快捷指令来帮助我们简化日常开发;
好的,至此这个系列终于完结啦,如果你看到了这里的话,真的非常感谢!也希望这个系列能对大家平时的开发工作能起到一些帮助。
原创文章,转载请标明出处:Soul Orbit
本文链接地址:测试,你写代码时最好的朋友(下篇)